
package mainimport "fmt" func main() { fmt.Println("Hello World!")}
也就是说go语言的入口点是main.main(真正的入口点),即是main包下的main函数。对这个demo,我们编译之后用ida打开查看,搜索主函数,当确定了主函数入口时,尝试反编译代码,缺发现失败,如下图所示:
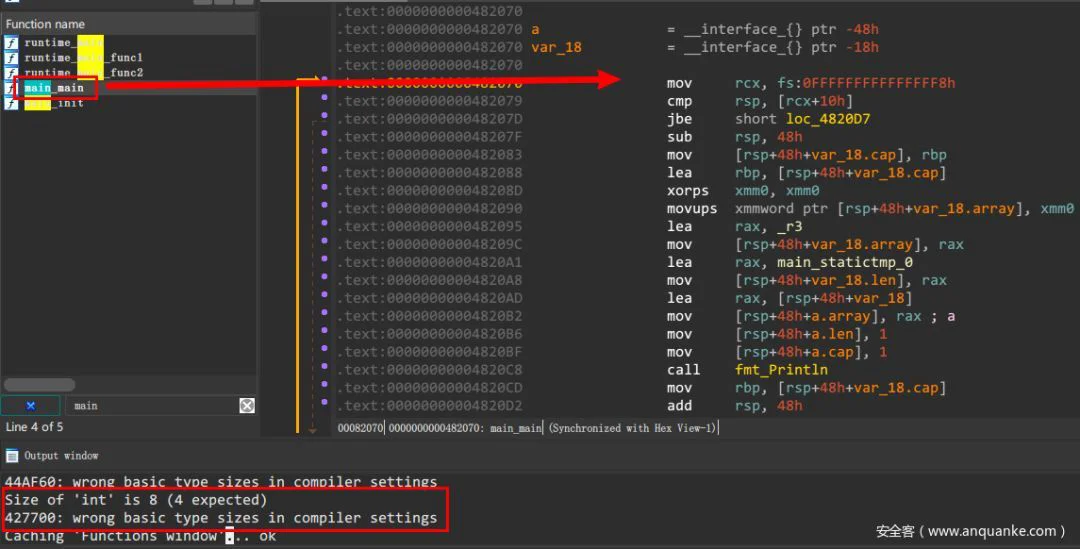
给出的提示是Size of 'int' is 8 (4 expected),对于这种错误,通过选项中的编译设置,修改整型的字长大小即可解决问题,如下图所示。
得到如下的代码:
void __cdecl main_main(){ __int64 v0; // rdx error_0 v1; // di __interface_{} ST00_24_2; // ST00_24 __interface_{} v3; // [rsp+30h] [rbp-18h] void *retaddr; // [rsp+48h] [rbp+0h] while ( (unsigned __int64)&retaddr <= *(_QWORD *)(__readfsqword(0xFFFFFFF8) + 16) ) runtime_morestack_noctxt(); v3.array = (__DIE_10518_interface_{} *)&r3; v3.len = (__int64)&main_statictmp_0; ST00_24_2.array = (__DIE_10518_interface_{} *)&v3; ST00_24_2.len = 1LL; ST00_24_2.cap = 1LL; fmt_Println(ST00_24_2, v1, v0);}
对于ida反编译出的go语言代码,可读性较差,类型转换较多,结构体较复杂,异常处理比较冗长,对于main_statictmp_0这个结构体,在go语言中包括了2部分,分别是字符串偏移量和字符串长度,这个结构体所指向的是string <offset unk_4B317B, 0Dh>,指出了字符串的偏移量和长度,长度是0xd(即”Hello World!”的长度),另外go语言中所有字符串都是放在一起的,所以偏移量和长度是很关键的,如下图所示:
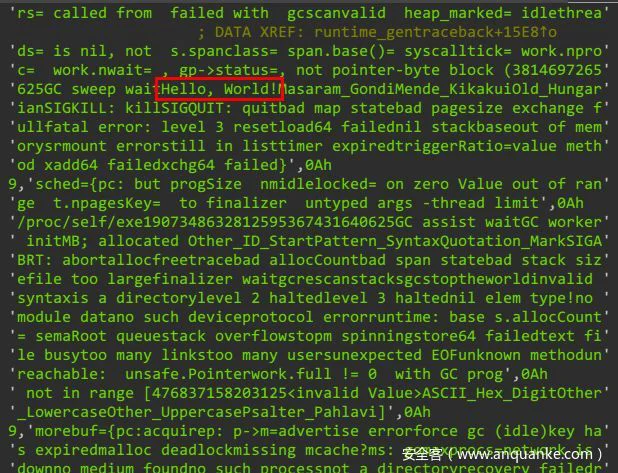
解决无符号的问题
对于上文那个demo而言,是有符号的程序,逆向起来有信息可以参考,大大加快了逆向的速度,但是对这道题而言,是无符号的,无符号的程序逆向起来由于不知道函数的功能,会特别饶,很容易把人绕进去。如下图所示:
当然也有人能纯静态分析出来,比如奈沙夜影师傅,参考最上面贴出来的链接,使用动态调试结合黑盒测试的方法Orz。师傅也自嘲道:Go语言的逆向感觉目前没啥方便的工具,只能硬怼汇编,缺少符号的情况下还是有点麻烦的,等一个师傅们的指教,这个题目我是纯黑盒调试出来的。针对这个问题,自己参考了几篇博文,收集了一些方法,供参考。
从签名角度出发
众所周知,签名是对函数、第三方库很好的检测方式,通过签名,ida很容易能分析出函数的名称,从而大概知道函数的作用。由于没有官方的签名库,所以这需要自己制作,参考了diffway@兰云科技银河实验室的方法,论述如下:
idb2pat.py+sigmake制作签名
idb2pat.py是火眼公司FireEye Labs Advanced Reverse Engineering团队编写的脚本,代码在GitHub上开源,该脚本主要通过CRC16的方式来计算每个函数块的特性,从而来识别不同的函数。这点也和IDA官方对签名文件的说明相符合,参见IDA F.L.I.R.T. Technology: In-Depth。
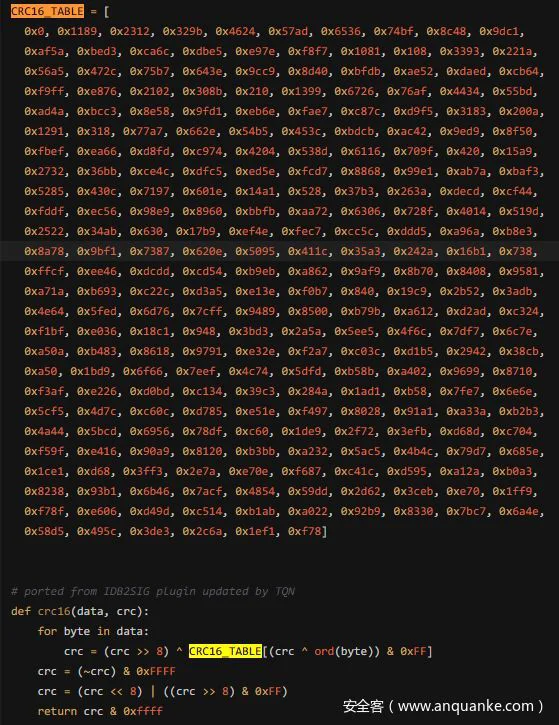
通过生成pat文件后,再使用ida SDK中提供的sigmake工具来生成相应的sig签名文件,将其复制到ida安装目录下的sigpc目录,然后我们在ida中就可以载入签名进行识别。在2088个函数中,识别出1271个函数,但是不是每个识别出的函数都能有效的命名,所以实际识别出的函数个数也就600左右,识别率较低,而且只能识别出被制作签名的程序所带的包,如果另一个程序使用了其他的包,那将无法识别,拓展性较低。
bindiff或者diaphora对比
通过bindiff或者diaphora来对比不同是ida数据库,以获取函数的特征也是种很好的方法,这种方法在平时分析静态链接的程序也很有用。但是存在的问题也很明显,由于diaphora是python编写的,所以运行速度是肉眼可见的慢,对于1000数量级的函数保存到数据库中竟然也要3分钟左右,保存完之后,再分析对比的时候,需要更多时间,效率很低。当数据完成对比之后,我们得到情况如下图所示:
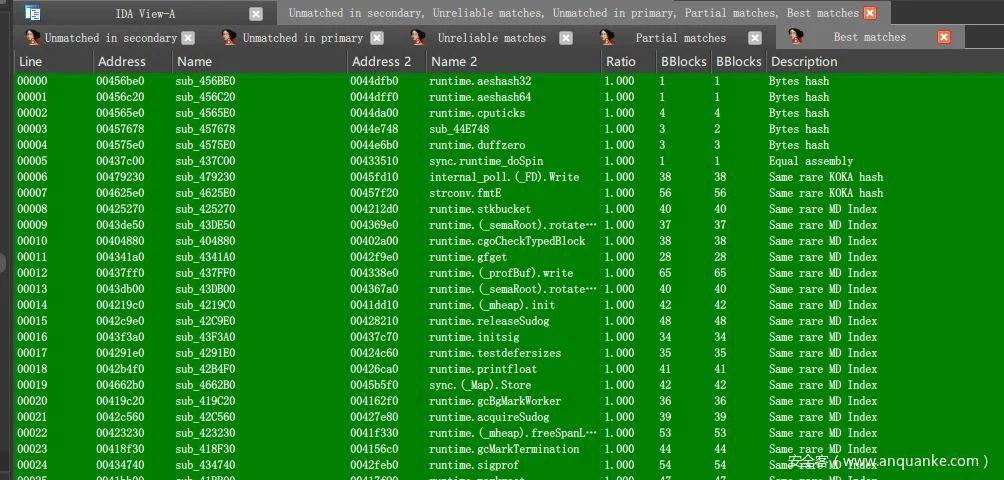
主要分为五栏:完全匹配、部分匹配、只在第一个数据库出现的、只在第二个数据库出现的以及不可靠匹配的。对我们来说,我们只需要关注匹配率高的即可,所以我们首选对完全匹配中的函数进行重命名,方法很简单,就是选中所有的完全匹配的函数,然后右键导入即可。
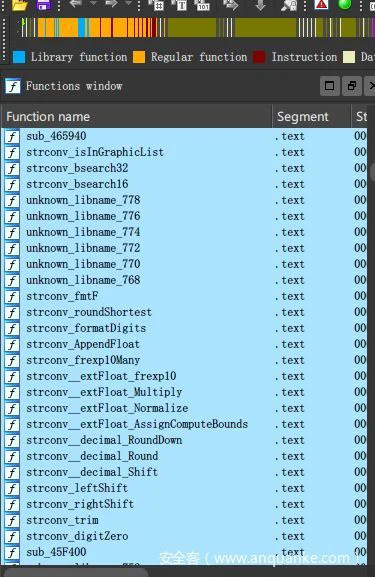
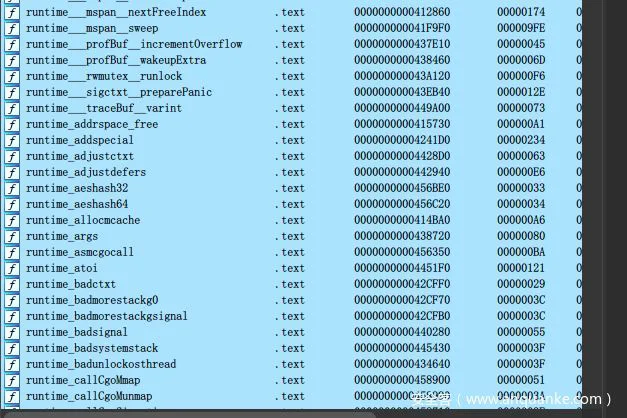
该方法的主要问题是速度太慢,不管是在前期初始化数据库的时候,还是后面重命名函数的时候,非常卡顿。其次是对函数类别没有很好的区分度,如下图所示,同样都是运行时函数,对函数类别处理不好,也不能对主函数进行区别,和第一种方式一样,识别率不高,只能识别出被制作签名的程序所带的部分库函数。
Rizzo插件生成数据库识别
关于rizzo,可以参看GitHub上的介绍Rizzo,同样也是一种对ida数据库进行保存然后提取信息进行对比的工具,收录于devttys0的ida脚本目录中。自己也进行了测试,速度还可以。
Building Rizzo signatures, this may take a few minutes...Generated 1314 formal signatures and 844 fuzzy signatures for 1784 functions in 10.64 seconds.Saving signatures to C:UsersxxxxxxDesktop11111.riz... done.Built signatures in 12.30 seconds
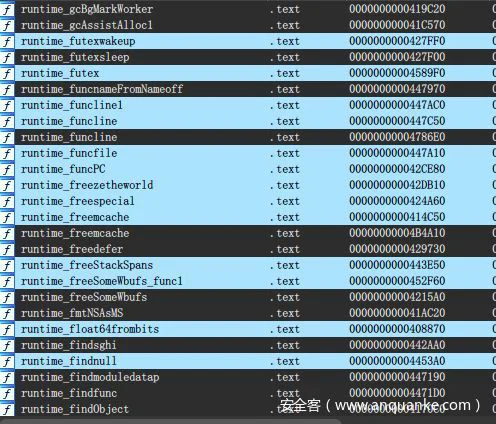
那么在保存完之后,载入riz文件进行测试,如下图所示。基本识别情况和上面2种方式差不多,也存在对原始文件的局部依赖性,所不同的是,这种方式不会误识别,而前面2种方式会产生很多未知的函数命名情况,歧义性较低。猜测是前面2种方法对模糊测试效果更好,第三种方式属于保守型的测试方法,会将极大概率的函数进行重命名,而较低的大概率函数则不会通过。
从Golang特性出发
上面的3种方法虽然能对部分函数进行识别,但是效果一半,前2种方法识别率大概有50%左右,第3种只有20%左右。且三者均不能对签名生成程序中没有的函数进行识别,也就是说连每个程序中的主函数都无法定位,因为每个程序中的主函数均不一致。下面将从Go语言的特性来解决这个问题。
GolangAssist脚本
在网上有一篇著名的go语言逆向解析博文,安全客中也有人提供了翻译,链接参见前言部分。该作者对golang的编译原理有着较深的理解,同时其提供了golang_loader_assist.py脚本用于还原符号信息,这对逆向而言真是再好也不为过了。但是这个脚本无法恢复Windows下编译的go程序,因为这个脚本中最重要的部分,是找到go语言程序中一个非常重要的段,叫做.gopclntab,在这个段中保存了函数的实际名称,而在Windows下编译的程序中则不存在这个段。
在这个脚本中最终的部分如下图所示:
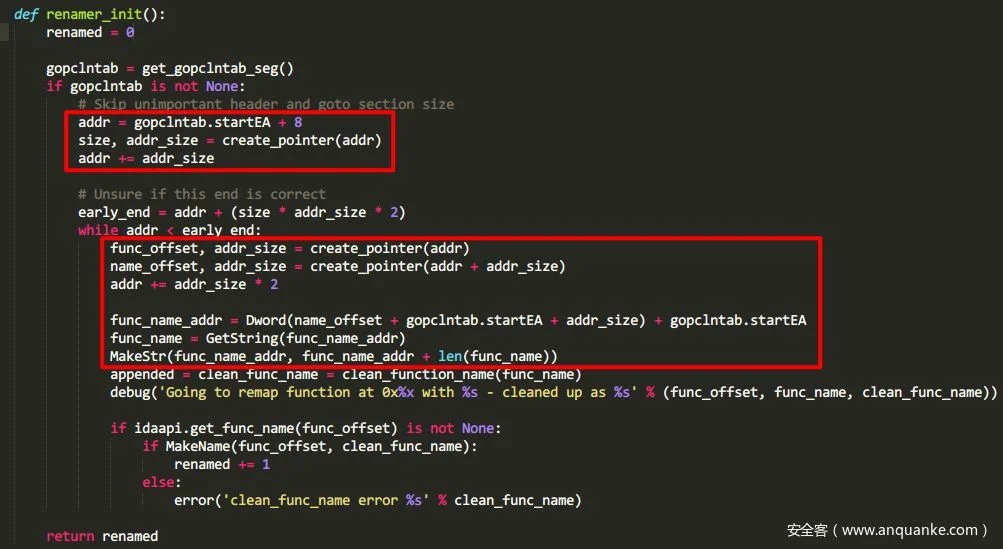
首先通过get_segm_by_name('.gopclntab')来定位到.gopclntab段的首地址。然后寻找偏移量是8的地方,根据程序字长来创建指针,再接下来一个字长则给出了.gopclntab段的大小,这样我们就能开始逐个处理每条数据,对每条数据而言,其中都包含了一个函数指针和一个函数名字符串偏移量,循环处理这些数据就能对所有的函数名进行还原,得到带符号信息的函数名称。
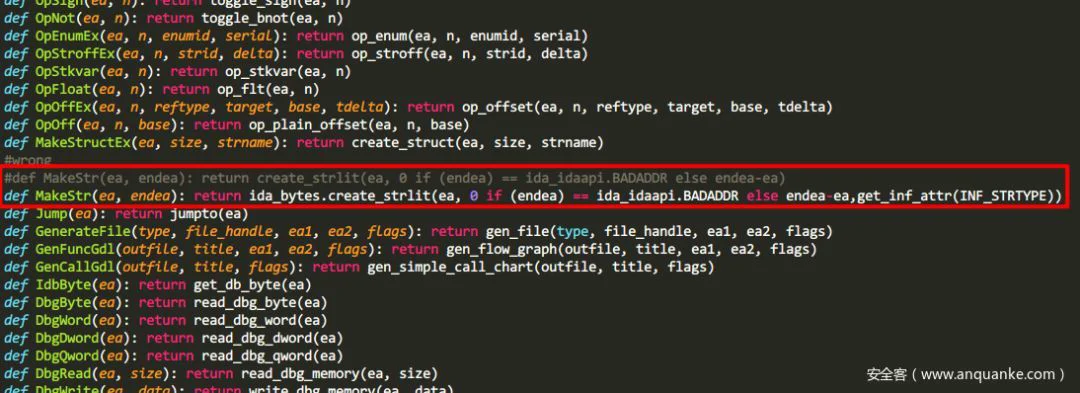
在实际使用这个脚本进行测试的过程中,需要注意的是,由于ida7.0对sdk和api的大量更新和重新,在idapython中的创建字符串函数MakeStr出错,主要原因是函数的重复定义,参看前言中看雪论坛的相关讨论,修改方式如上图所示。
自己将最关键的部分代码进行了分析和抽取,脚本如上,这段代码可直接在ida中运行,用以定位函数名偏移量和修改函数名,但是注意最后这个地方函数名修改会有点问题,原因是函数名中除了下划线不能出现其他字符,但是当我们运行完毕后,很多函数名是存在特殊符号的,需要自己过滤。
gopclntab = get_segm_by_name('.gopclntab')if gopclntab is not None: base = gopclntab.startEA + 8 # 计算函数名个数 count = Dword(base) # 基地址 base += 8 for i in xrange(0, 2 * count, 2): # 创建函数指针 MakeQword(base + 8*i) functionAddr = Qword(base + 8*i) # 创建函数名字符串偏移量(相对于gopclntab基地址而言) MakeQword(base + 8*i + 8) offset = Qword(base + 8*i + 8) offset = Dword(offset + gopclntab.startEA + 8) # 函数名字符串偏移量(文件偏移量FOA) functionName = offset + gopclntab.startEA name = GetString(functionName) # 创建字符串 MakeStr(functionName, functionName + len(name)) # 修改函数名(ida禁止函数名出现特殊符号,需过滤后才能达到100%效果,我这里没有过滤) MakeName(functionAddr, name)
运行结果如下图所示:
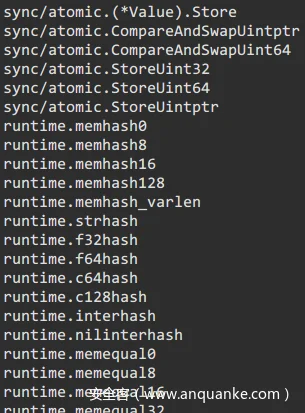
通过分析go语言特有的.gopclntab段,我们可以恢复调试符号信息,只有该段中保存的信息均可以进行恢复,恢复率达到98%以上。
IDAGolangHelper脚本
刚刚讨论完了GolangAssist,效果是非常不错的,而作为GolangAssist的升级版本,IDAGolangHelper做的则更加完善,该脚本的作者在2016年底的zeronights会议中展示了他的成果,有兴趣的同学可以参看他的PPT,其实整个脚本的思路和上面一样,同样是通过.gopclntab这个段所保存的符号信息来获取函数信息,如下图所示。

除此之外,作者进一步分析了go语言的版本问题,通过2种方式来确定当前程序的go语言版本,一是通过特征字符串的来进行查找,二是通过分析go中特有的结构体类型,由于不同版本之间有结构体会产生变化,作者提出了这种思路来确定版本信息。

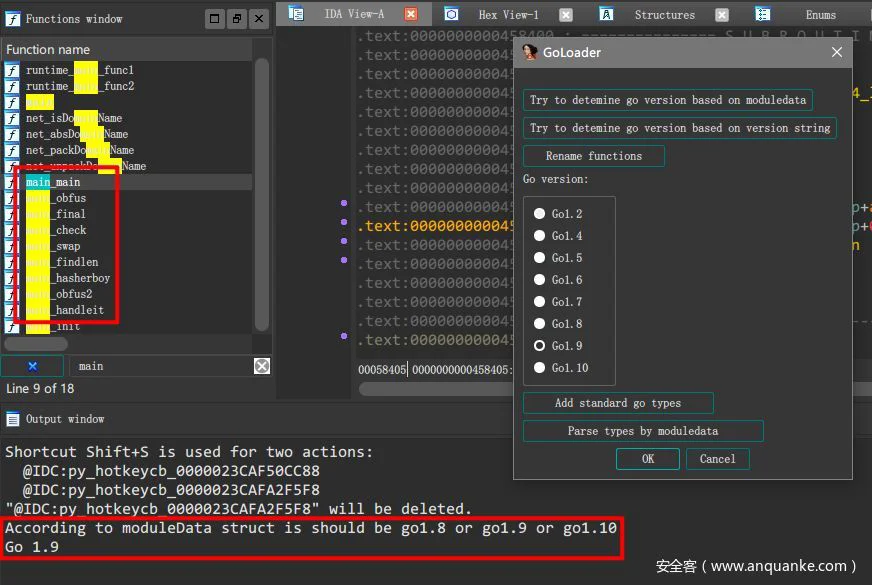
而通过实际分析证明,第一种方法,即特征字符串的方式来查找版本还是会更高效,更准确些,相比而言,第二种方法由于版本之间的差异不多,则会导致歧义。下图是使用效果,当我们载入该脚本后,第二种方式只能判断是go1.8或1.9或1.10,但是特征字符串则较好的确定是go1.9版本。在重命名函数后,再搜索main字符串,就能定位到main包中的所有函数了。
其他方法
当然无符号问题解决的方法还有很多,比如著名符号执行引擎angr中就使用了基于函数语义识别库函数,也有人对源码进行了分析。函数语义就是分析函数的功能和执行的操作,包括寄存器、内存、堆栈和对其他函数的调用流,作为人去分析函数的时,也是类似的,所以感觉这里也可以用机器学习的方法来进一步提高分析效率。
当然学术界也有对这方面的研究,比如二进制代码函数相似度匹配技术研究这篇论文,通过函数的序言部分的特征,提出了二阶段函数匹配方法TPM,在识别出相似函数后,找到其调用关系和决策规则,然后递归的识别不同版本的函数,据论文所述,识别准确率平均高于diaphora和patchdiff方法,也是值得借鉴的。
结语