
写在前面 最后总结有福利
Go语言作为新兴的语言,最近发展势头很是迅猛,其最大的特点就是原生支持并发。它使用的是“协程(goroutine)模型”,和传统基于 OS 线程和进程实现不同,Go
语言的并发是基于用户态的并发,这种并发方式就变得非常轻量,能够轻松运行几万并发逻辑。
Go 的并发属于 CSP 并发模型的一种实现,CSP 并发模型的核心概念是:“不要通过共享内存来通信,而应该通
过通信来共享内存”。这在 Go 语言中的实现就是 Goroutine 和 Channel。
场景描述
在一些场景下,有大规模请求(十万或百万级qps),我们处理的请求可能不需要立马知道结果,例如数据的打点,文件的上传等等。这时候我们需要异步化处理。常用的方法有使用resque、MQ、RabbitMQ等。这里我们在Golang语言里进行设计实践。
方案演进
直接使用goroutine
在Go语言原生并发的支持下,我们可以直接使用一个goroutine(如下方式)去并行处理这个请求。但是,这种方法明显有些不好的地方,我们没法控制goroutine产生数量,如果处理程序稍微耗时,在单机万级十万级qps请求下,goroutine大规模爆发,内存暴涨,处理效率会很快下降甚至引发程序崩溃。
...
go handle(request)
...
1
2
3
4
goroutine协同带缓存的管道
我们定义一个带缓存的管道;
var queue = make(chan job, MAX_QUEUE_SIZE)
1
然后起一个协程处理管道传来的请求;
go func(){
for {
select {
case job := <-queue:
job.Do(request)
case <- quit:
return
}
}
}()
1
2
3
4
5
6
7
8
9
10
11
12
接收请求,发送job进行处理
job := &Job{request}
queue <- job
1
2
3
讲真,这种方法使用了缓冲队列一定程度上了提高了并发,但也是治标不治本,大规模并发只是推迟了问题的发生时间。当请求速度远大于队列的处理速度时,缓冲区很快被打满,后面的请求一样被堵塞了。
job队列+工作池
只用缓冲队列不能解决根本问题,这时候我们可以参考一下线程池的概念,定一个工作池(协程池),来限定最大goroutine数目。每次来新的job时,从工作池里取出一个可用的worker来执行job。这样一来即保障了goroutine的可控性,也尽可能大的提高了并发处理能力。
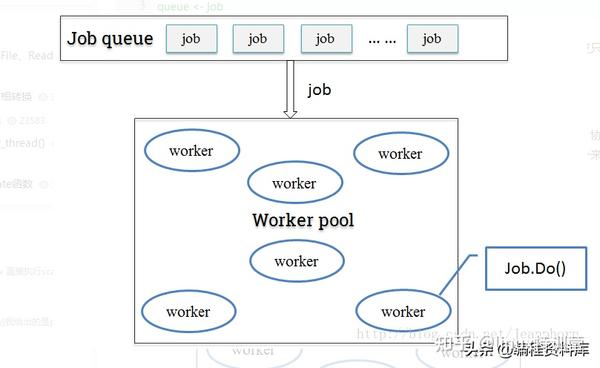
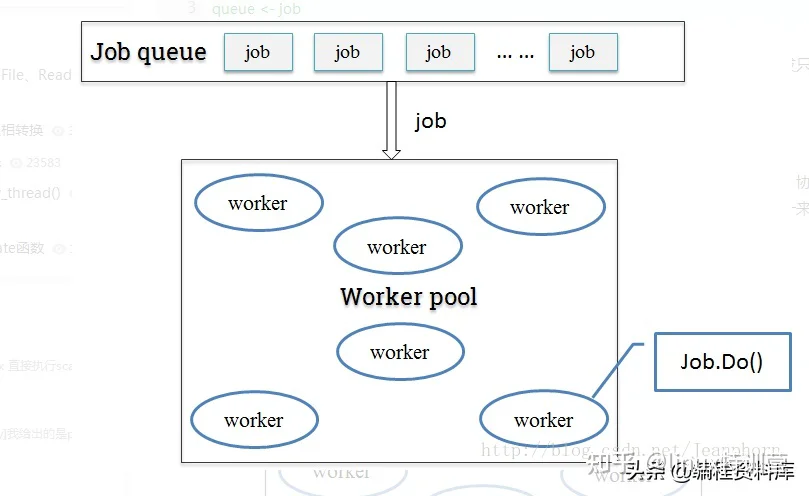
工作池实现
一.sync.Pool定义
我们通常用golang来构建高并发场景下的应用,但是由于golang内建的GC机制会影响应用的性能,为了减少GC,golang提供了对象重用的机制,也就是sync.Pool对象池。 sync.Pool是可伸缩的,并发安全的。其大小仅受限于内存的大小,可以被看作是一个存放可重用对象的值的容器。 设计的目的是存放已经分配的但是暂时不用的对象,在需要用到的时候直接从pool中取。
官方的解释:临时对象池是一些可以分别存储和取出的临时对象,池中的对象会在没有任何通知的情况下移出(释放或重新使用)。pool在多协程的环境下是安全的,在fmt包中有一个使用pool的例子,它维护了一个动态大小的输出buffer。另外,一些短生命周期的对象不适合使用pool来维护,这种情况使用go自己的free list更高效。
二.sync.Pool的实现
2.1使对象池高效
获取对象的过程:
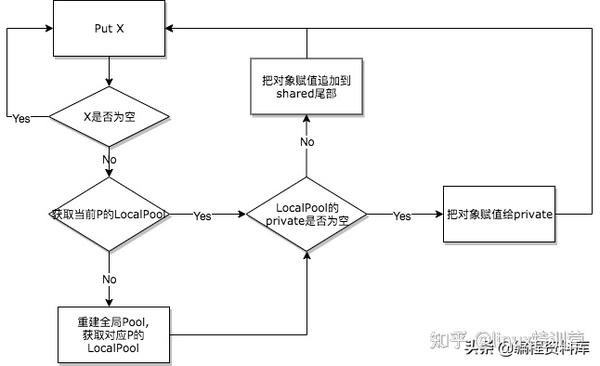
归还对象的过程:
2.2 对象池的详细实现
2.2.1 对象池结构
type Pool struct {
noCopy noCopy //防止copy
local unsafe.Pointer //本地p缓存池指针
localSize uintptr //本地p缓存池大小
//当池中没有对象时,会调用New函数调用一个对象
New func() interface{}
2.2.2 获取对象池中的对象
func (p *Pool) Get() interface{} {
if race.Enabled {
race.Disable()
}
//获取本地的poolLocal对象
l := p.pin()
//先获取private池中的私有变量
x := l.private
l.private = nil
runtime_procUnpin()
if x == nil {
//查找本地的共享池,因为本地的共享池可能被其他p访问,所以要加锁
l.Lock()
last := len(l.shared) - 1
if last >= 0 {
//如果本地共享池有对象,取走最后一个
x = l.shared[last]
l.shared = l.shared[:last]
}
l.Unlock()
//查找其他p的共享池
if x == nil {
x = p.getSlow()
}
}
if race.Enabled {
race.Enable()
if x != nil {
race.Acquire(poolRaceAddr(x))
}
}
//未找到其他可用元素,则调用New生成
if x == nil && p.New != nil {
x = p.New()
}
return x
}
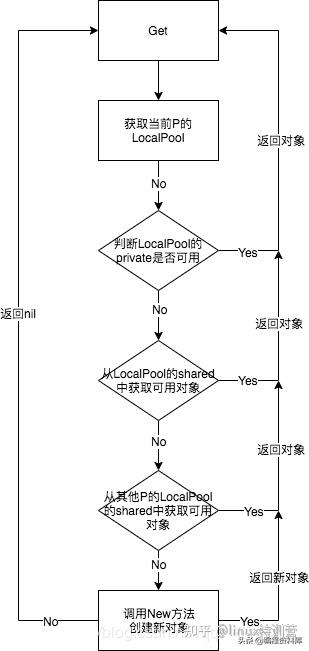
从共享池中获取可用元素:
func (p *Pool) getSlow() (x interface{}) {
// See the comment in pin regarding ordering of the loads.
size := atomic.LoadUintptr(&p.localSize) // load-acquire
local := p.local // load-consume
// Try to steal one element from other procs.
pid := runtime_procPin()
runtime_procUnpin()
for i := 0; i < int(size); i++ {
l := indexLocal(local, (pid+i+1)%int(size))
l.Lock()
last := len(l.shared) - 1
if last >= 0 {
x = l.shared[last]
l.shared = l.shared[:last]
l.Unlock()
break
}
l.Unlock()
}
return x
}
2.2.3 归还对象池中的对象
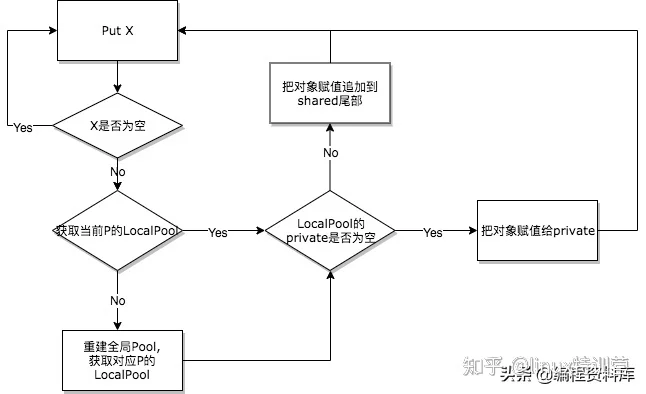
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
if race.Enabled {
if fastrand()%4 == 0 {
//1/4的概率会把该元素扔掉
return
}
race.ReleaseMerge(poolRaceAddr(x))
race.Disable()
}
l := p.pin()
if l.private == nil {
//赋值给私有变量
l.private = x
x = nil
}
runtime_procUnpin()
if x != nil {
//访问共享池加锁
l.Lock()
l.shared = append(l.shared, x)
l.Unlock()
}
if race.Enabled {
race.Enable()
}
}
三.sync.Pool 使用
// 一个[]byte的对象池,每个对象为一个[]byte
var bytePool = sync.Pool{
New: func() interface{} {
b := make([]byte, 512)
return &b
},
}
func main() {
a := time.Now().Unix()
// 不使用对象池
for i := 0; i < 1000000000; i++{
obj := make([]byte,512)
_ = obj
}
b := time.Now().Unix()
// 使用对象池
for i := 0; i < 1000000000; i++{
obj := bytePool.Get().(*[]byte)
_ = obj
bytePool.Put(obj)
}
c := time.Now().Unix()
fmt.Println("without pool ", b - a, "s")
fmt.Println("with pool ", c - b, "s")
}
// without pool 17 s
四.sync.Pool的使用场景
sync.Pool的get方法不会对获取到的对象做任何的保证,因为放入的本地子池中的值可能在任何是由被删除,而且不会通知调用者。放入共享池的值有可能被其他的goroutine偷走。随意临时对象池适合存储一些临时数据,不适合用来存储数据库连接等持久化存储的对象。
总结;关注+私信‘资料’MF分享相关资料。内容包括:C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,ffmpeg流媒体,CDN,P2P,K8S,Docker,Golang,TCP/IP,协程,嵌入式,ARM,DPDK等等。。。

