
一、引言
背景
我们在做系统时,很多时候是处理实时的任务,请求来了马上就处理,然后立刻给用户以反馈。但有时也会遇到非实时的任务,比如确定的时间点发布重要公告。或者需要在用户做了一件事情的X分钟/Y小时后,EG:
“PM:我们需要在这个用户通话开始10分钟后给予提醒给他们发送奖励”
对其特定动作,比如通知、发券等等。一般我接触到的解决方法中在比较小的服务里都会自己维护一个backend,但是随着这种backend和server增多,这种方法很大程度和本身业务耦合在一起,所以这时需要一个延时队列服务。
名词解释
topic_list队列:每一个来的延时请求都应该又一个延时主题参考kafka,在逻辑上划分出一个队列出来每个业务分开处理;
topic_info队列:每一个队列topic都存在一个新的队列里,每次扫描topic信息检测新的topic建立与销毁管理服务协程数量;
offset:当前消费的进度;
new_offset:新消费的进度,预备更迭offset;
topic_offset_lock:分布式锁。
二、设计目标
功能清单
1、延时信息添加接口基于http调用
2、拥有存储队列特性,可保存近3天内的队列消费数据
3、提供消费功能
4、延时通知
性能指标
预计接口的调用量:单秒单类任务数3500,多秒单类任务数1300
压测结果:
简单压测
wrk写入qps:259.3s 写入9000条记录 单线程 无并发
触发性能/准确率:单秒1000,在测试机无延长。单秒3000时,偶尔出现1-2秒延迟。受内存和cpu影响。
三、系统设计
交互流程
时序图

本设计基于http接口调用,当向topic存在的队列中添加消息的时候,消息会被添加到相应topic队列的末尾储存,当添加到不存在的相应topic队列时,首先建立新topic队列,当定时器触发的时候或者分布式锁,抢到锁的实例先获得相应队列的offset,设置新offset,就可以释放锁了让给其他实例争抢,弹出队列头一定数量元素,然后拿到offset段的实例去存储中拿详细信息,在协程中处理,主要协程等待下次触发。然后添加协程去监控触发。
模块划分
1、队列存储模块
1·delay下的delay.base模块,主要负责接收写请求,将队列信息写入存储,不负责backend逻辑,调用存储模块
2、backend模块。delay下的delay.backend模块,负责时间触发扫描对应的topic队列,调用存储模块,主要负责访问读取存储模块,调用callback模块
1·扫描topic添加groutine
2·扫描topic_list消费信息
3·扫描topic_list如果一定时间没有消费到则关闭groutine
3、callback模块,主要负责发送已经到时间的数据,向相应服务通知
3、存储模块
1·分布式锁模块,系统多机部署,保证每次消费的唯一性,对每次topic消费的offset段进行上锁offset到new_offset段单机独享
2·topic管理列表,管理topic数量控制协程数
3·topic_list,消息队列
4·topic_info,消息实体,可能需要回调中会携带一些信息统一处理
4、唯一号生成模块。
五、缓存设计
目前使用全缓存模式
key设计:
topic管理list key: XX:DELAY_TOPIC_LIST type:list
topic_list key: XX:DELAY_SIMPLE_TOPIC_TASK-%s(根据topic分key) type:zset
topic_info key: XX:DELAY_REALL_TOPIC_TASK-%s(根据topic分key) type:hash
topic_offset key: XX:DELAY_TOPIC_OFFSET-%s(根据topic分key) type:string
topic_lock key: xx:DELAY_TOPIC_RELOAD_LOCK-%s(根据topic分key) type:string
六、接口设计
delay.task.addv1 (延时队列添加v1)
请求示例
返回示例
pull回调方式返回(v2不再支持)
请求示例
返回示例
delay.task.addv2 (延时队列添加v2)
请求示例
示例
返回示例
七、MQ设计(v2不再支持)
关于kafka消费方式返回:
八、其他设计
唯一号设计
调用存储模块,利用redis的自增结合逻辑生成唯一号具体逻辑如下:
分布式锁设计
九、设计考虑
健壮性
熔断策略:
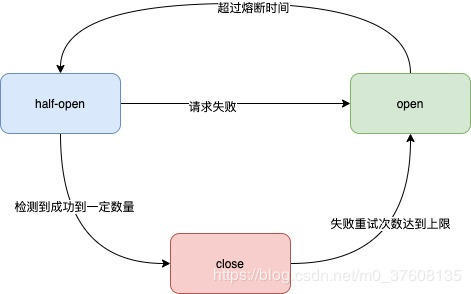
这版设计中有很多不足之处,当redis不可访问时,请求将大量积压给机器或者实例带来压力,导致其他服务不可用,所以采取降级策略(降级策略也有不足);在请求redis时加入重试,当重试次数多于报警次数,会记录一个原子操作atomic.StoreInt32(&stopFlag,1),其中stopFlag为一个全局的变量,在atomic.LoadInt32(&stopFlag)后,stopFlag的值为1则暂时不请求redis,同时记录当前时间,加入定时器,熔断器分为三个级别,开,关,半开,当定时器结束后stopFlag=2第二个定时将为半开状态计时,有概率访问redis,当成功次数到达阈值stopFlag=0,否则stopFlag=1继续计时
不足
1、调用time定时
通常golang 写循环执行的定时任务大概用三种实现方式:
1、time.Sleep方法:
2、time.Tick函数:
3、其中Tick定时任务,也可以先使用time.Ticker函数获取Ticker结构体,然后进行阻塞监听信息,这种方式可以手动选择停止定时任务,在停止任务时,减少对内存的浪费。
在最开始以为sleep是单独处理直接停掉了这个协程,所以第一版用的也是sleep,但是在收集资料后发现这几种方式都创建了timer,并加入了定时任务处理协程。实际上这两个函数产生的timer都放入了同一个timer堆(golang时间轮),都在定时任务处理协程中等待被处理。Tick,Sleep,time.After函数都使用的timer结构体,都会被放在同一个协程中统一处理,这样看起来使用Tick,Sleep并没有什么区别。实际上是有区别的,本文不是讨论golang定时执行任务time.sleep和time.tick的优劣,以后会在后续文章进行探讨。使用channel阻塞协程完成定时任务比较灵活,可以结合select设置超时时间以及默认执行方法,而且可以设置timer的主动关闭,所以,建议使用time.Tick完成定时任务。
2、存储模块问题
目前是全缓存,没有DB参与,首先redis(codis)的高可用是个问题,在熔断之后采取“不作为”的判断也是有问题的,所以对未来展望,首先是:
1·单机的数据结构使用多时间轮。为了减少数据的路程,将load数据的过程异步加载到机器,减少网络io所造成的时间损耗。同时也是减少对redis的依赖
2·引入ZooKeeper或者添加集群备份,leader。保证集群中至少有两台机器load一个topic的数据,leader可以协调消费保证高可用