
本文参考书籍:<<Go并发编程实战 第二版>>
我们都知道并发有三种情况,进程,线程,协程。其中进程(利用多核)和线程(利用单核)是系统级的调用,也就是说进程和线程是系统级的并发。协程是一些编程语言特有的,程序级的并发,其特点是单线程下,当代码发生阻塞时(如I/O阻塞,网络响应延迟等等),程序并不会傻傻的等待,而是先去执行其他代码,等到阻塞结束时,再回调到阻塞处继续运行。
线程实现模型:
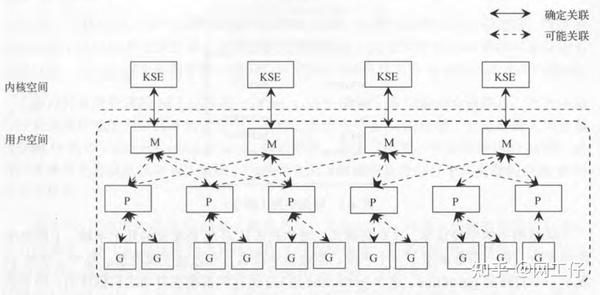
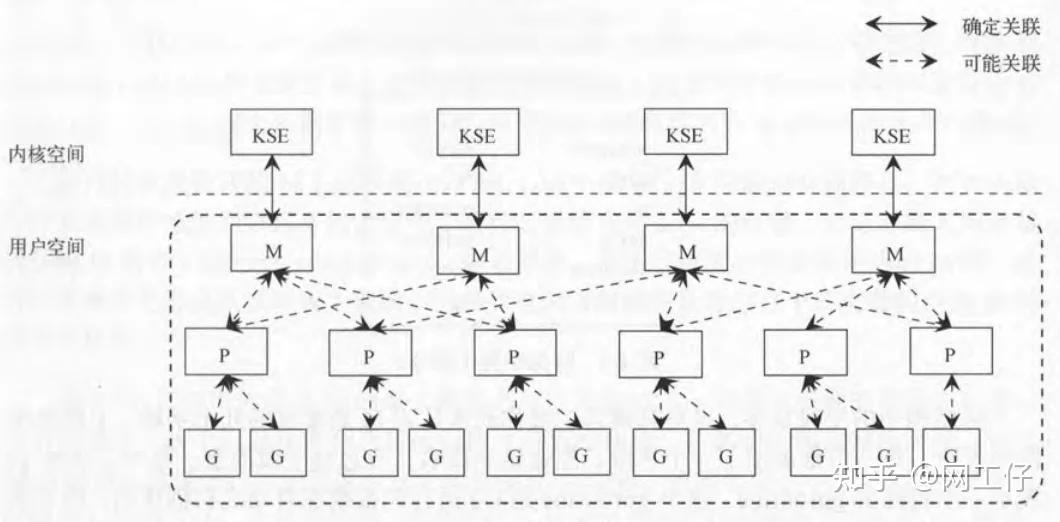
我们用Go创建线程的时候,创建的是用户态的线程,然而系统创建的线程却是内核态。这也就意味着在用户态的线程与内核态的线程之间,存在着一个调度器,来对接用户态的线程与内核态的线程。如下图所示。
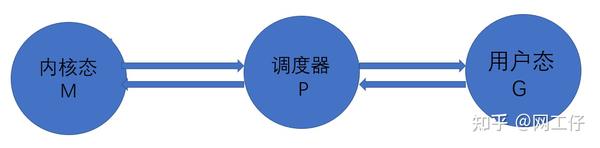
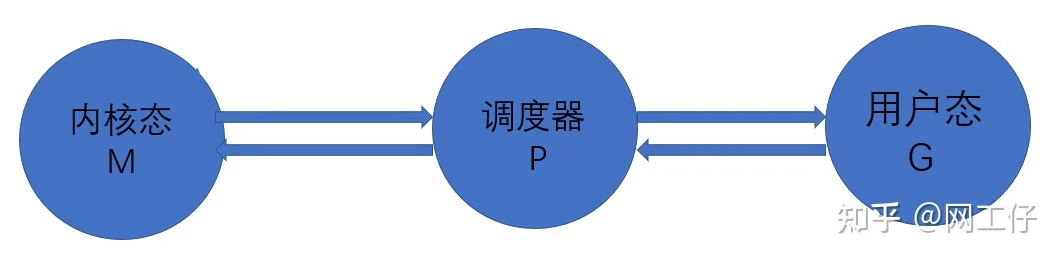
这三个核心元素支撑起了这个线程模型的核心架构。
1)M:machine的缩写,一个M代表着一个内核线程
2)P:processor的缩写,一个P代表着一个上下文管理器
3)G:goroutine的缩写,一个G代表着对一段go代码的封装,也就是说用户态线程
我们不去关心它的具体实现细节,从宏观上来看。一个G的运行,需要P,M的支持(内核线程+上下文)。其中P中含有一个可运行G的队列,该队列中的G会依次与P,M对接,从而获取运行的机会。如下图所示。
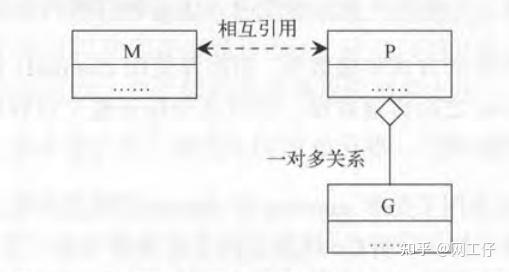
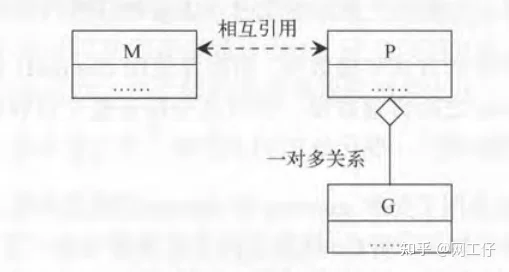
接下来我们把视角再扩大一些,从整个程序的角度去看。
KES即内核调用实体,有兴趣的朋友可以去了解一下。也就是说每个内核线程都有一个且唯一对应的KSE内核调用实体。P与G,M与P之间不存在确定的对应关系。
限于篇幅,线程模型的实现说到这里。
go语句与goroutine:
一条go语句意味着一个函数或者方法并发的执行。
一个有问题的开启线程例子(注:func(){}()代表的是自执行函数)
按理说程序会打印出子线程正在执行,但结果不是这样的。因为主线程和子线程是并行的,子线程还未开启,主线程就已经退出了,无论子线程是否执行完毕,都会退出。在开发中一定要注意这一点。
我们可以使用time.Sleep()显示的阻塞主线程,给子线程留有足够的执行时间。
一个有问题的通过for循环开启多个线程的例子
package main
import (
"fmt"
"time"
)
func main() {
names := []string{"niko","mike","tony"}
for _,name := range names{
go func () {
fmt.Printf("%s\n",name)
}()
}
time.Sleep(time.Second * 2)
}
按理说它输出的结果应该是niko,mike,tony,但是最后它输出了三个tony,这是为什么呢
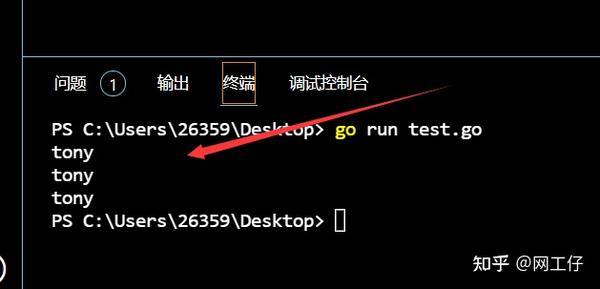
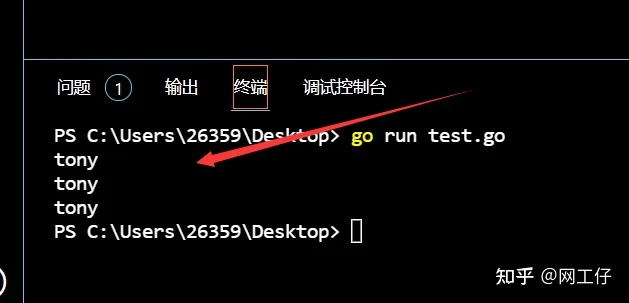
我们来找找原因,子线程内部打印的值,取决于外部变量,for循环的变量name。也就是说当for循环迭代三次完成之后,三个线程才准备开启。此时的name为tony。所以会输出三个tony。我们当然也可以通过每次迭代睡眠一段时间来得到正确结果,可这不是真正意义上的并行。
要解决这个问题,我们只要让子线程打印的值取决于内部变量就好了。
package main
import (
"fmt"
"time"
)
func main() {
names := []string{"niko","mike","tony"}
for _,name := range names{
go func (na string) {
fmt.Printf("%s\n",na)
}(name)
}
time.Sleep(time.Second * 2)
}
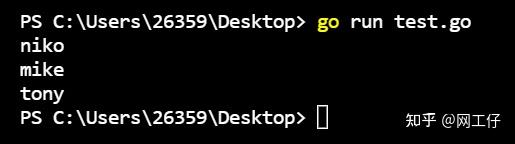
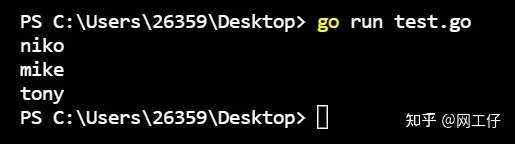
我们通过向自执行函数中添加一个参数,使其成为内部变量,从而得到了正确的结果。需要注意的是,输出的结果是无序的,可以多试几次,自行体会。
限于篇幅,互斥锁,读写锁,原子操作,条件变量等会在下一章进行介绍。