
准备爬取内涵段子的几则笑话,先查看网址:http://www.budejie.com/text/
简单分析后发现每页的url呈加1趋势
第一页: http://www.budejie.com/text/1
第二页:http://www.budejie.com/text/2
...
每页的段子:
<a href="/detail-28278217.html"> 内容</a>
<a href="/detail-28270675.html"> 内容</a>
....
所以正则表达式的解释规则是<a href="/detail-\d{8}.html">(?s:(.*?))</a>,第一个分组的内容就是需要的文字。
代码如下:
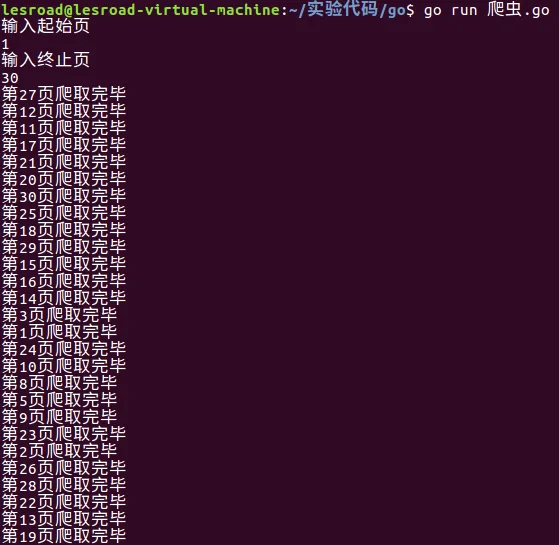
运行截图:
效果截图:
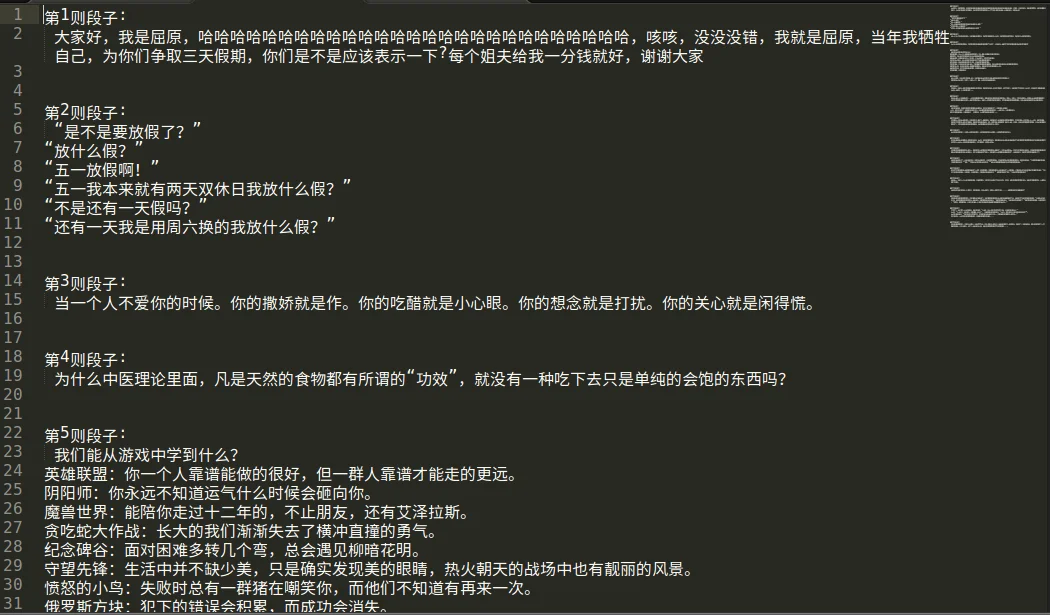
最后我发现第2页之后的段子都是重复的。。。