
非零基础自学Golang
第17章 HTTP编程(上)
17.2 HTTP客户端
17.2.3 发起GET请求
从现在开始我们将会学习如何使用Go语言模拟浏览器发起HTTP请求。
发起请求前需要创建一个请求对象,使用NewRequest创建。
func NewRequest(method, urlStr string, body io.Reader) (*Request, error)
NewRequest使用指定的方法、网址和可选的body创建并返回一个新的*Request。我们先来看如何发起一个GET请求:
[ 动手写 17.2.1 ]
package main
import (
"fmt"
"net/http"
)
func main() {
client := &http.Client{}
request, err := http.NewRequest("GET", "http://www.baidu.com", nil)
if err != nil {
fmt.Println(err)
}
response, err := client.Do(request)
fmt.Println(response.StatusCode)
}
动手写17.2.1对百度网站发起了一次GET请求,程序的主要流程为创建了一个客户端对象client和一个请求对象request,分别对其进行初始化,request初始化需要提供请求方法和请求地址。
这两个对象初始化后,client客户端调用Do方法发起一次请求并获得服务端的响应,最后程序打印出响应的状态码,执行结果如下:
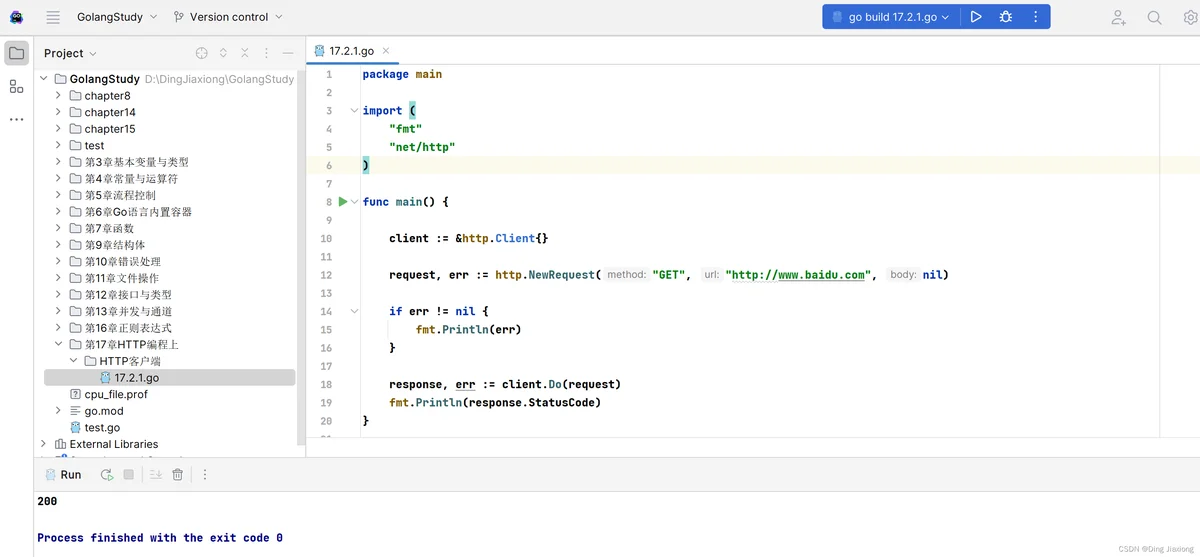
如果想要打印响应的主要内容body,可以使用标准包ioutil中的ReadAll方法来读取响应的流数据。
当然现在 2022年12 月7日,现版本的Go 已经过时了很多 ioutil,用io代替
[ 动手写 17.2.2]
package main
import (
"fmt"
"io"
"net/http"
)
func main() {
client := &http.Client{}
request, err := http.NewRequest("GET", "http://www.baidu.com", nil)
if err != nil {
fmt.Println(err)
}
response, err := client.Do(request)
res, err := io.ReadAll(response.Body)
if err != nil {
fmt.Println(err)
}
// 打印body
fmt.Println(string(res))
}
动手写17.2.2发起请求并打印输出了响应内容body,由于Body的类型为io.ReadCloser,不能直接读取其中的内容,需要通过io.ReadAll读取,返回字节数组,最后转化成字符串进行输出。
运行结果如下:
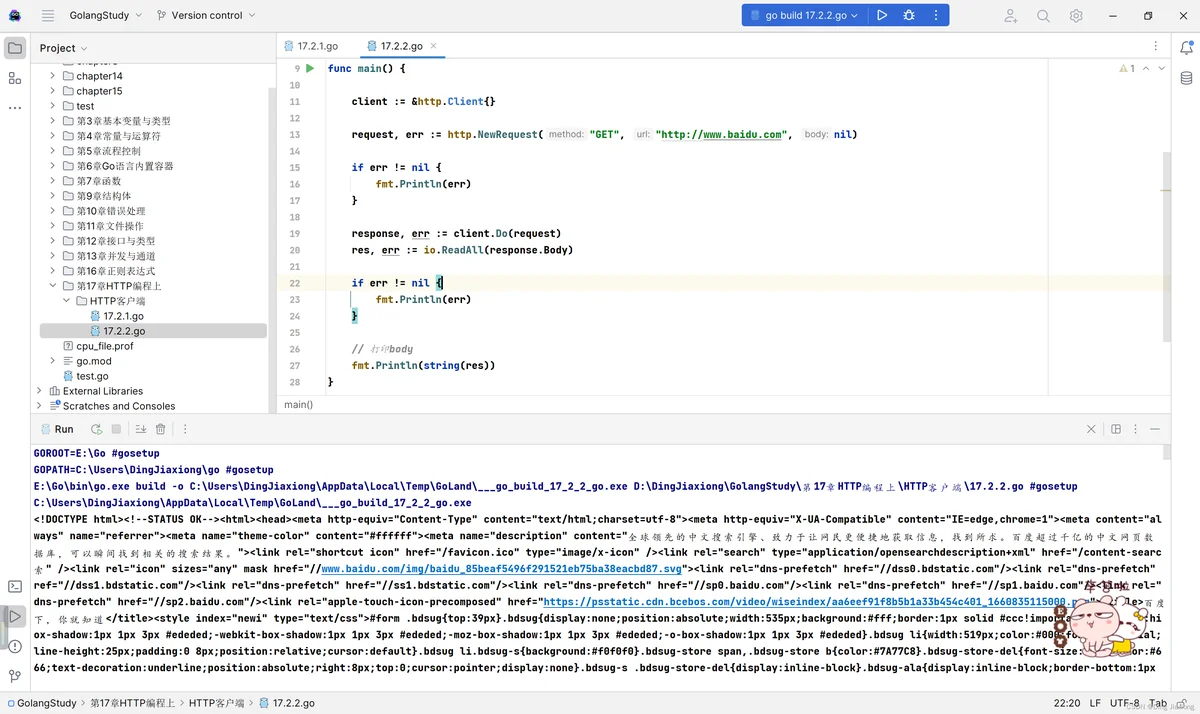
反正就是 一堆,没毛病
当一个网站有一些资源需要登录后才能访问时,我们希望能够通过Go语言实现批量自动化爬取这些内容,那如何让服务器知道我们用Go编写的爬虫客户端是已登录状态?这就需要设置使用Cookie,Cookie通常用来标识客户端的登录状态。
Request实例可以使用AddCookie方法给请求添加Cookie。
[ 动手写 17.2.3]
package main
import (
"fmt"
"net/http"
"strconv"
)
func main() {
client := &http.Client{}
request, err := http.NewRequest("GET", "http://www.baidu.com", nil)
if err != nil {
fmt.Println(err)
}
// 使用http.Cookie 结构体初始化一个 cookie 键值对
cookie := &http.Cookie{Name: "userId", Value: strconv.Itoa(12345)}
// 使用前面构建的 request 方法AddCookie 往请求中添加Cookie
request.AddCookie(cookie)
request.AddCookie(&http.Cookie{Name: "session", Value: "YWRtaW4="})
response, err := client.Do(request)
fmt.Println(response.Request.Cookies())
}
动手写17.2.3使用AddCookie添加了userId和session两个Cookie,通常服务端使用session来判断客户端是否为登录用户,运行结果如下:
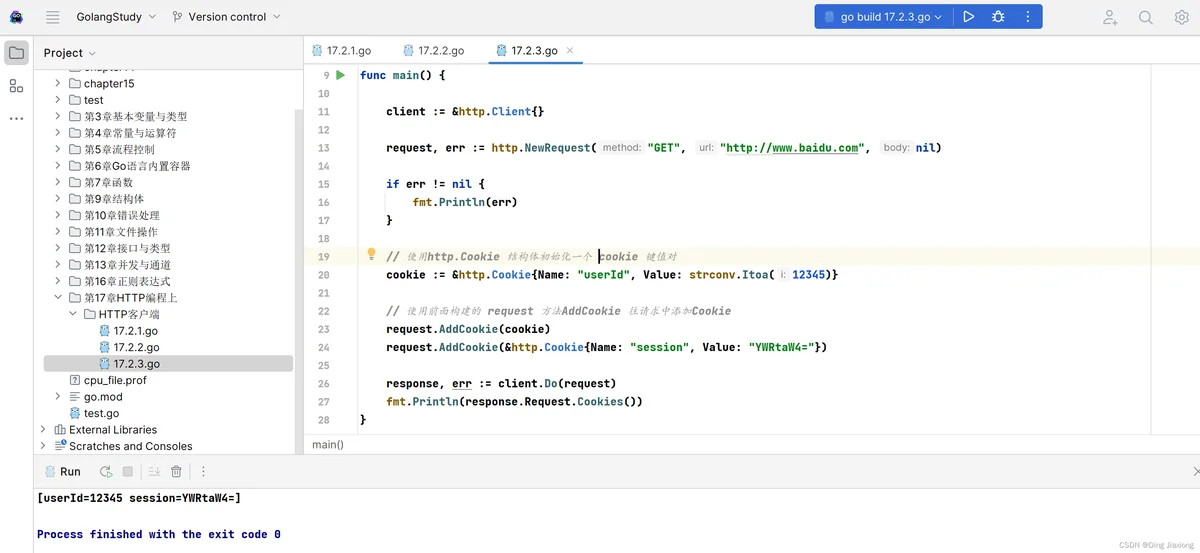
做了反爬策略的网站,一般都会根据Header头中的User-Agent的值解析判断是浏览器还是爬虫,这时我们需要设置成浏览器的UA来绕过这类反爬策略。
Request可以直接使用request.Header.Set(key,value)来设置Header。
[ 动手写 17.2.4]
package main
import (
"fmt"
"net/http"
)
func main() {
client := &http.Client{}
request, err := http.NewRequest("GET", "http://www.baidu.com", nil)
if err != nil {
fmt.Println(err)
}
// 设置request的Header,具体可参考http协议
request.Header.Set("Accept", "text/html, application/xhtml+xml, application/xml;q=0.9, */*;q=0.8")
request.Header.Set("Accept-Charset", "GBK, utf-8;q=0.7, *;q=0.3")
request.Header.Set("Accept-Encoding", "gzip, deflate, sdch")
request.Header.Set("Accept-Language", "zh-CN, zh;q=0.8")
request.Header.Set("Cache-Control", "max-age=0")
request.Header.Set("Connection", "keep-alive")
request.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36")
response, err := client.Do(request)
fmt.Printf("%#v", response.Request.Header)
}
动手写17.2.4使用了自定义的Header来发起请求,运行结果如下:
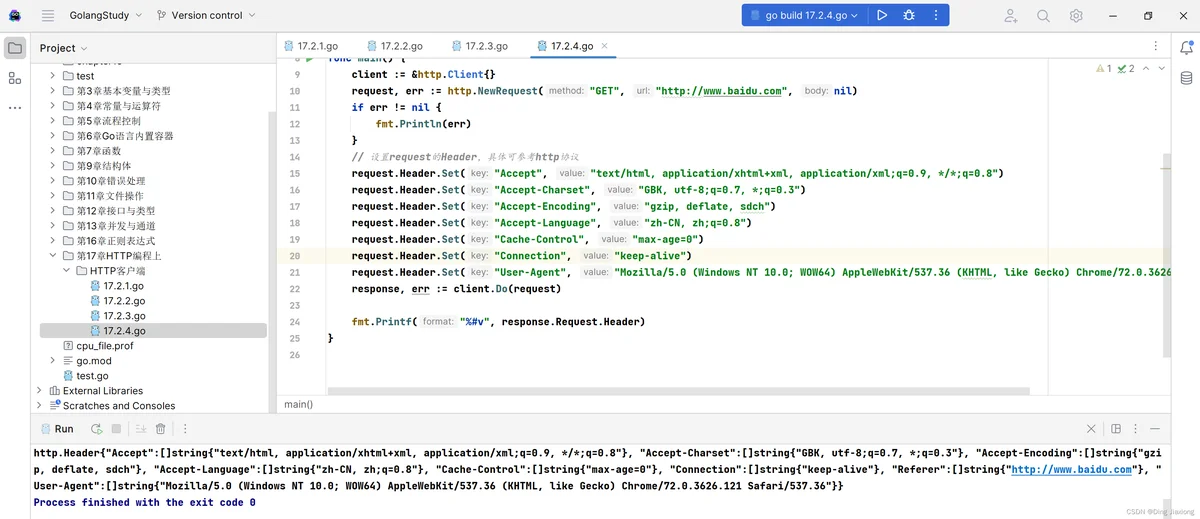
在上一小节中,我们提到了Client类型含有GET方法,而GET方法是对Do方法的封装,使用GET方法可以快速发起一个GET请求。
http包中也有一个叫GET的方法,底层就是调用Client的GET方法。
[ 动手写17.2.5]
package main
import (
"fmt"
"io"
"net/http"
)
func main() {
// http.Get 实际上是DefaultClient.Get(url), Get 函数是高度封装的, 只有一个参数url
// 对于一般的 http Request 是可以使用, 但是不能定制 Request
response, err := http.Get("http://www.baidu.com")
if err != nil {
fmt.Println(err)
}
defer response.Body.Close()
body, _ := io.ReadAll(response.Body)
fmt.Println(string(body))
}
运行结果
OK,没问题