
在并发编程,尤其是Golang中多协程编程中,数据的一致性和安全性是一个必须要解决的难度。这里面最重要的是通过锁机制来解决这些问题,锁包括CAS,互斥锁,消息队列,分布式锁来解决。但是对于锁的底层实现,知之甚少,这里就是来探讨锁机制的底层实现。
一.锁的场景实例我们在使用Golang的过程中,经常会使用到并发处理问题的情况。在网络编程中处理消息,或者在应用层面通过并发处理提高解决问题的能力,并行处理多个任务。但是在实际使用中,并发处理有很多问题。
全局共享数据的问题,我们可以看以下示例:
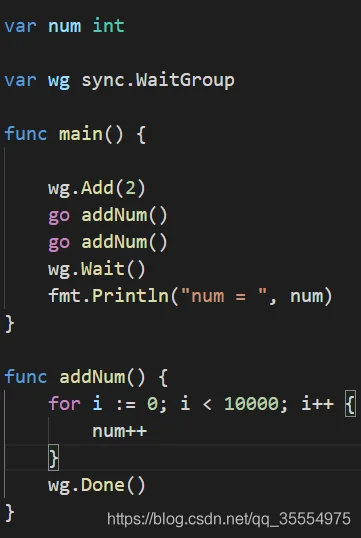
这是很典型的数据冲突的问题。因为两个协程并发执行,并不能保证num的一致性,导致结果如下:
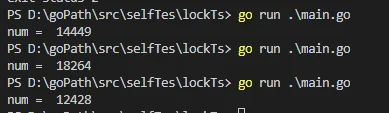
预期值:20000 实际结果: 不确定
简单理解如下
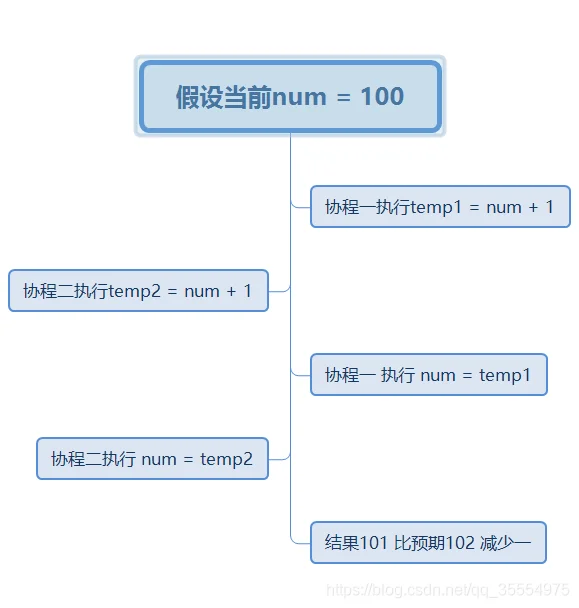
由此可见 数据一致性出现了问题 解决方式如下
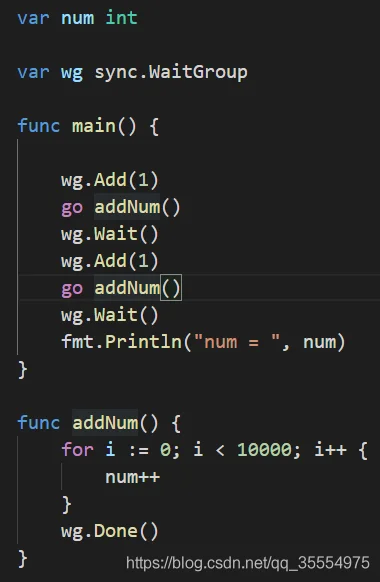
输出结果为:
![]()
![]()
通过锁让协程并发执行,解决数据一致性的问题
另外一个问题:
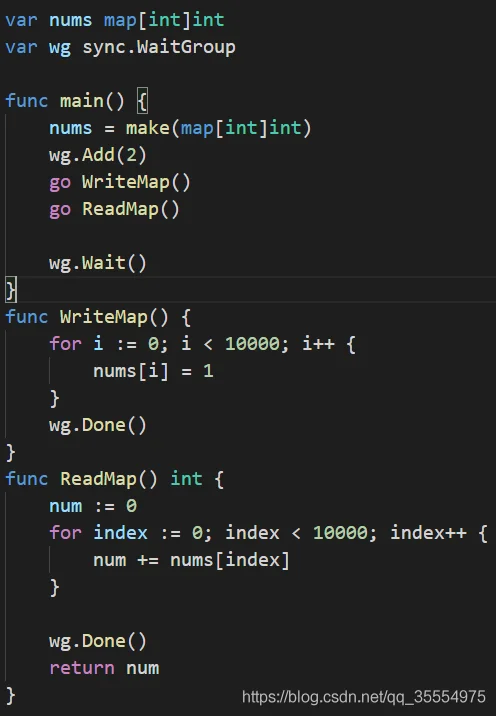
代码中可以看到,我们对map进行的同时读写操作
运行结果如下:

结果就是map 不是线程安全的。如果同时读写map,map本身是桶 + 树的结果,导致读写不安全。造成数据错误。
正确的处理是读写使用锁,如下:
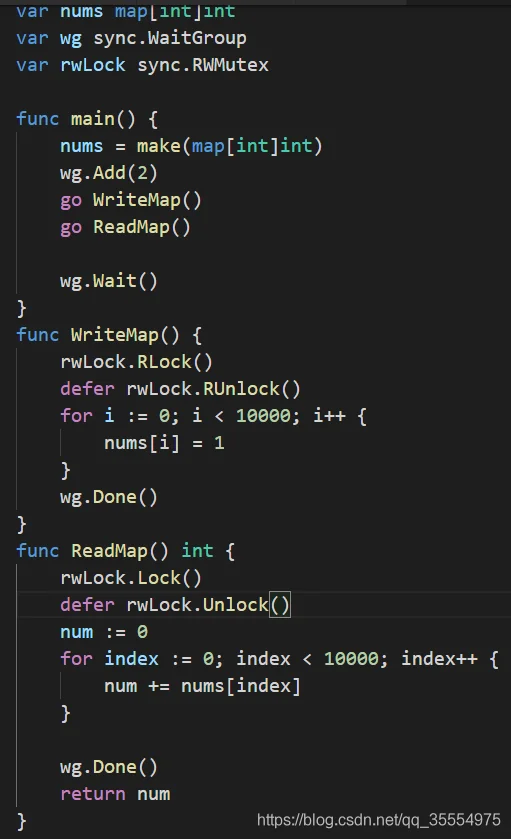
使用读写锁,保证读的性能,又能读写互斥。
锁的作用
-
避免并行运算中,共享数据读写的安全性问题。
-
并行执行中,在锁的位置,同时只能有一个程序可以获得锁,其他程序不能获得锁。
-
锁的出现,使得并行执行的程序在锁的位置串行化执行。
-
多核、分布式运算、并发执行,才会需要锁。
锁的底层实现类型
锁内存总线,针对内存的读写操作,在总线上控制,限制程序的内存访问
锁缓存行,同一个缓存行的内容读写操作,CPU内部的高速缓存保证一致性
锁,作用在一个对象或者变量上。现代CPU会优先在高速缓存查找,如果存在这个对象、变量的缓存行数据,会使用锁缓存行的方式。否则,才使用锁总线的方式。
速度,加锁、解锁的速度,理论上就是高速缓存、内存总线的读写速度,它的效率是非常高的。而出现效率问题,是在产生冲突时的串行化等待时间,再加上线程的上下文切换,让多核的并发能力直线下降。
缓存和一致性协议MESI
英文首字母缩写,也就是英文环境下的术语、俚语、成语,新人理解和学习有难度,但是,掌握好了既可以省事,又可以缩小文化差距。
另外就是对英文的异形化,也类似汉字的变形体,“表酱紫”,“蓝瘦香菇”,老外是很难懂得,反之一样。
-
M: modify 被修改,数据有效,cache和内存不一致
-
E: exclusive 独享,数据有效,cache与内存一致
-
S: shared 共享,数据有效,cache与内存一致,多核同时存在
-
I: invalid 数据无效
-
F: forward 向前(intel),特殊的共享状态,多个S状态,只有一个F状态,从F高速缓存接受副本
当内核需要某份数据时,而其它核有这份数据的备份时,本cache既可以从内存中导入数据,也可以从其它cache中导入数据(Forward状态的cache)。
四种状态的更新路线图
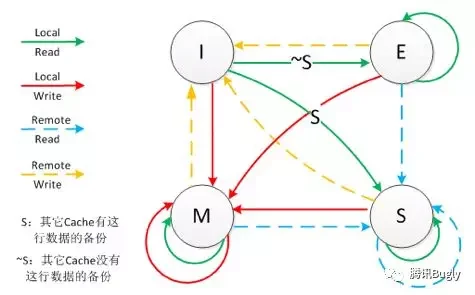
高效的状态: E, S
低效的状态: I, M
这四种状态,保证CPU内部的缓存数据是一致的,但是,并不能保证是强一致性。
每个cache的控制器不仅知道自己的读写操作,而且也要监听其它cache的读写操作。
缓存的意义
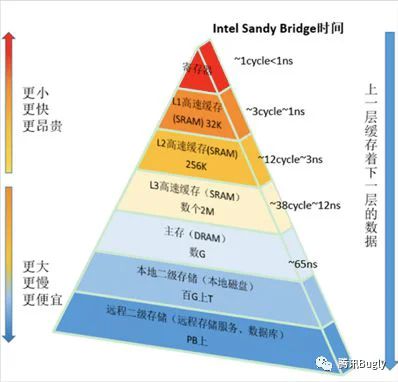
1 时间局部性:如果某个数据被访问,那么不久还会被访问
2 空间局部性:如果某个数据被访问,那么相邻的数据也很快可能被访问
局限性:空间、速度、成本
更大的缓存容量,需要更大的成本。更快的速度,需要更大的成本。均衡缓存的空间、速度、成本,才能更有市场竞争力,也是现在我们看到的情况。当然,随着技术的升级,成本下降,空间、速度也就能继续稳步提高了。
缓存行,64Byte的内容
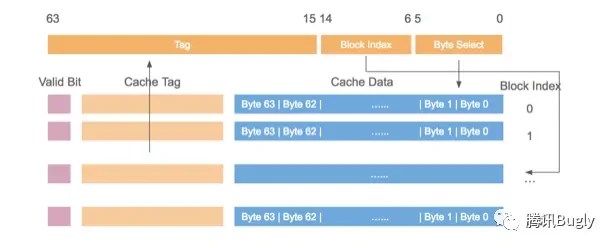
缓存行的存储空间是64Byte(字节),也就是可以放64个英文字母,或者8个int64变量。
注意伪共享的情况——56Byte共享数据不变化,但是8Byte的数据频繁更新,导致56Byte的共享数据也会频繁失效。
解决方法:缓存行的数据对齐,更新频繁的变量独占一个缓存行,只读的变量共享一个缓存行。
锁的底层实现原理,与CPU、高速缓存有着密切的关系,接下来一起看看CPU的内部结构。
CPU与计算机结构
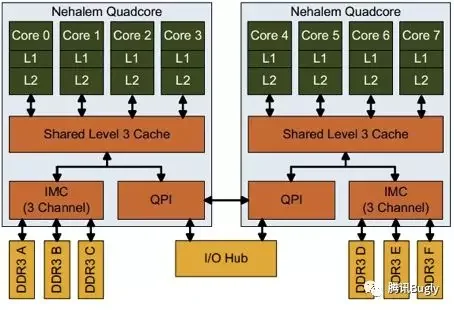
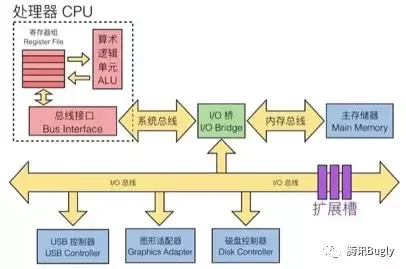
内核独享寄存器、L1/L2,共享L3。在早先时候只有单核CPU,那时只有L1和L2,后来有了多核CPU,为了效率和性能,就增加了共享的L3缓存。
多颗CPU通过QPI连接。再后来,同一个主板上面也可以支持多颗CPU,多颗CPU也需要有通信和控制,才有了QPI。
内存读写都要通过内存总线。CPU与内存、磁盘、网络、外设等通信,都需要通过各种系统提供的系统总线。
CPU流水线
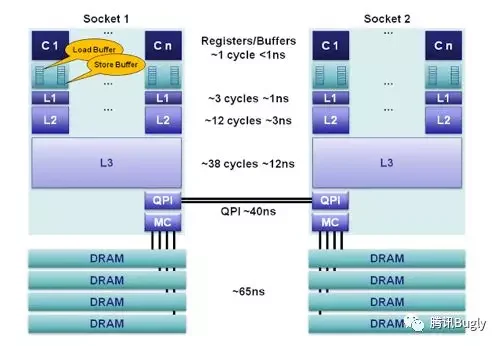

CPU流水线,里面还有异步的LoadBuffer,
Store Buffer, Invalidate Queue。这些缓冲队列的出现,更多的异步处理数据,提高了CPU的数据读写性能。
CPU为了保证性能,默认是宽松的数据一致性。
编译器、CPU优化
-
编译器优化:重排代码顺序,优先读操作(读有更好的性能,因为cache中有共享数据,而写操作,会让共享数据失效)
-
CPU优化:指令执行乱序(多核心协同处理,自动优化和重排指令顺序)
编译器、CPU屏蔽
-
优化屏蔽:禁止编译器优化。按照代码逻辑顺序生成二进制代码,volatile关键词
-
内存屏蔽:禁止CPU优化。防止指令之间的重排序,保证数据的可见性,store barrier, load barrier, full barrier
-
写屏障:阻塞直到把Store Buffer中的数据刷到Cache中
-
读屏障:阻塞直到Invalid Queue中的消息执行完毕
-
全屏障:包括读写屏障,以保证各核的数据一致性
Go语言中的Lock指令就是一个内存全屏障同时禁止了编译器优化。

x86的架构在CPU优化方面做的相对少一些,只是针对“写读”的顺序才可能调序。
加锁,加了些什么?
-
禁止编译器做优化(加了优化屏蔽)
-
禁止CPU对指令重排(加了内存屏蔽)
-
针对缓存行、内存总线上的控制
-
冲突时的任务等待队列
自旋锁:通过循环一直检查是否能够加锁,效率低,占用CPU
互斥锁:在Golang 中就是休眠该协程,直到被唤醒。需要上下文切换,操作花销大
互斥锁操作 sync.Mutex.Lock
源码:见%GOROOT%/src/sync/mutex.go
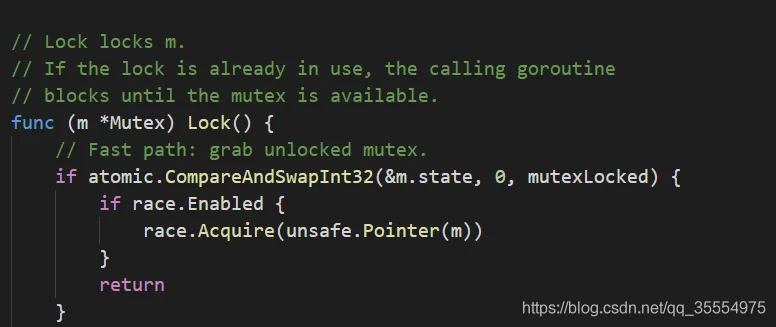
如果锁被占用,则该协程会等待知道该操作有效。通过CAS来操作竞争状态&m.state。如果成功,表明锁生效则返回。
如果操作失败,表明锁被占用。
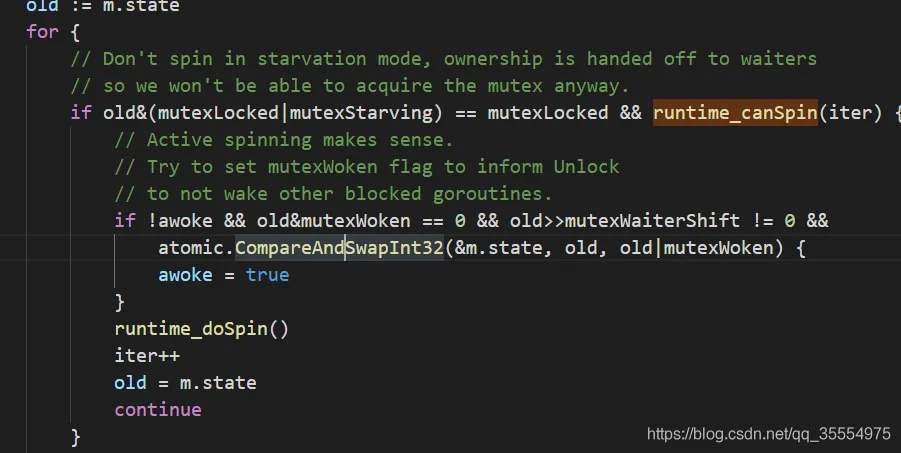
首先通过自选来判断是否可以锁,主要是runtime_canSpin(iter)
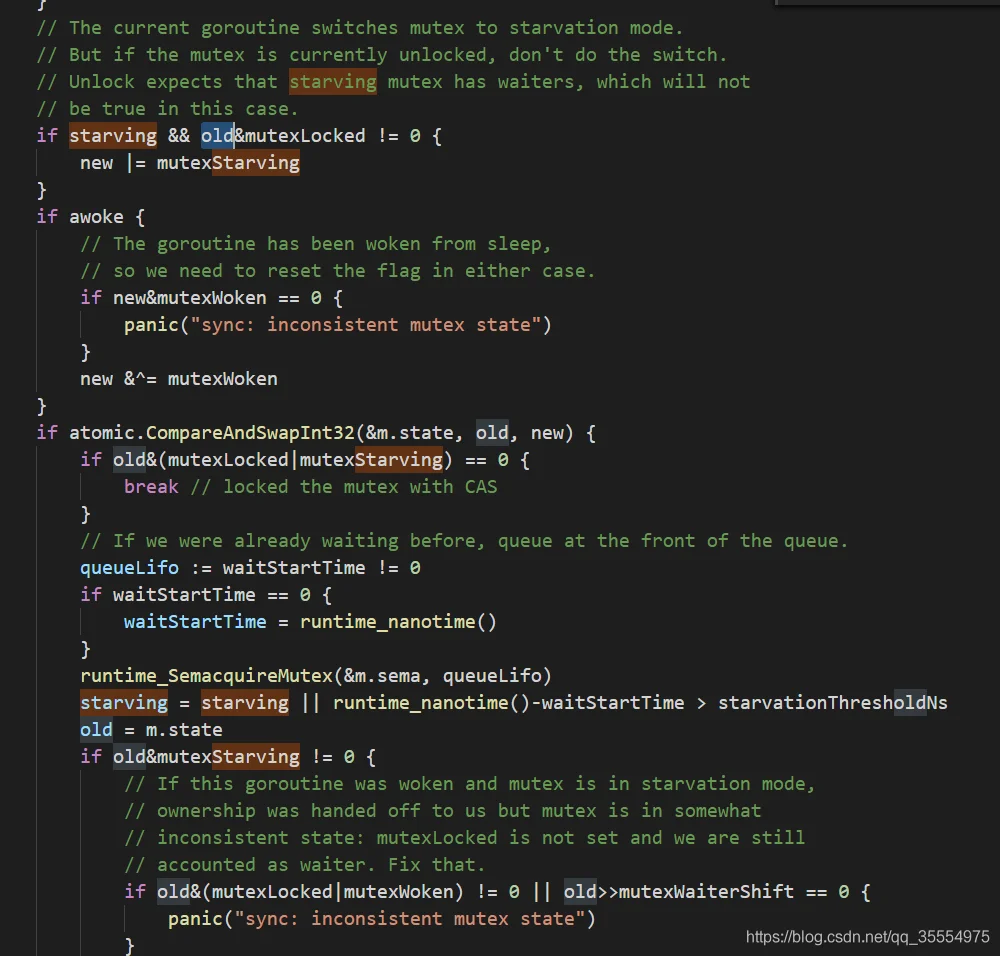
如果失败 则切换当前的协程为饥饿模式。如果当前协程解锁,不用切换。再次通过CAS尝试获取锁。
runtime_SemacquireMutex 锁请求失败,进入休眠状态,等待信号唤醒。
唤醒之后再做循环判断。
条件锁:根据条件启动任务。场景较特殊
读写锁:本质上是互斥锁,但是读取优化,在并发读中有良好的性能。在不是读多写少的场景中,效率不如互斥锁。
无锁操作CAS: Compare And Swap 比较并交换,将多个指令合成一个指令,保证操作的原子性。
源码:见%GOROOT%/src/runtime/internal/atomic/asm_amd64.s
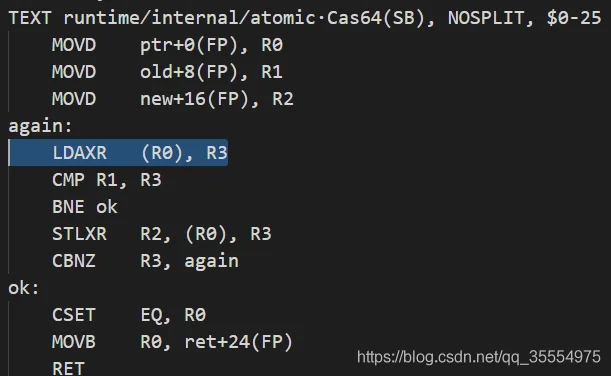
查询ARM 文档:LDAXR是Load-Acquire Exclusive Register. Load-Acquire Exclusive Register derives an address from a base register value, loads a 32-bit word or 64-bit doubleword from memory, and writes it to a register. The memory access is atomic. 从内存中读取32位或者64位数据,并且访问是原子性的,是带锁访问。保证数据的一致性。