
Crawler4U 一句话简介:十年磨一剑 - Crawler4U 专注通用爬虫。一下被吸引了,文档很少,想略过,但一看使用该爬虫的用户。

震惊了!于是看一下代码。发现太专业了👍相见恨晚😄
如果下次需要做爬虫,肯定会选择 Crawler4U
使用入门
下载或编译
下载二进制文件或下载源码来编译。
1 2 3
go get -d crawler.club/crawler
cd $GOPATH/src/crawler.club/crawler
make配置
conf/seeds.json1 2 3 4 5 6 7 8 9 10
[
{
"parser_name": "section",
"url": "http://www.newsmth.net/nForum/section/1"
},
{
"parser_name": "section",
"url": "http://www.newsmth.net/nForum/section/2"
}
]parser_name1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
{
"name": "section",
"example_url": "http://www.newsmth.net/nForum/section/1",
"default_fields": true,
"rules": {
"root": [
{
"type": "url",
"key": "section",
"xpath": "//tr[contains(td[2]/text(),'[二级目录]')]/td[1]/a"
},
{
"type": "url",
"key": "board",
"xpath": "//tr[not(contains(td[2]/text(),'[二级目录]'))]/td[1]/a"
}
]
},
"js": ""
}rules["root"]["key"]sectionboard1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
{
"name": "board",
"example_url": "http://www.newsmth.net/nForum/board/Universal",
"default_fields": true,
"rules": {
"root": [
{
"type": "url",
"key": "article",
"xpath": "//tr[not(contains(@class, 'top ad'))]/td[2]/a"
},
{
"type": "url",
"key": "board",
"xpath": "//div[@class='t-pre']//li[@class='page-select']/following-sibling::li[1]/a"
},
{
"type": "text",
"key": "time_",
"xpath": "//tr[not(contains(@class, 'top'))][1]/td[8]"
}
]
},
"js": ""
}
article.json1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46
{
"name": "article",
"example_url": "http://www.newsmth.net/nForum/article/AI/65703",
"default_fields": true,
"rules": {
"root": [
{
"type": "url",
"key": "article",
"xpath": "//div[@class='t-pre']//li/a/@href"
},
{
"type": "dom",
"key": "posts",
"xpath": "//table[contains(concat(' ', @class, ' '), ' article ')]"
}
],
"posts": [
{
"type": "text",
"key": "text",
"xpath": ".//td[contains(concat(' ', @class, ' '), ' a-content ')]"
},
{
"type": "html",
"key": "meta",
"xpath": ".//td[contains(concat(' ', @class, ' '), ' a-content ')]",
"re": [
"发信人:(?P<author>.+?)\\((?P<nick>.*?)\\).*?信区:(?P<board>.+?)<br/>",
"标 题:(?P<title>.+?)<br/>",
"发信站:(?P<site>.+?)\\((?P<time>.+?)\\)",
"\\[FROM: (?P<ip>[\\d\\.\\*]+?)\\]"
]
},
{
"type": "text",
"key": "floor",
"xpath": ".//span[contains(@class, 'a-pos')]",
"re": ["(\\d+|楼主)"],
"js": "function process(s){if(s=='楼主') return '0'; return s;}"
}
]
},
"js": ""
}
等等等……
运行
1 2 3 4 5 6
% ./crawler -logtostderr -api -period 30
Git SHA: Not provided (use make instead of go build)
Go Version: go1.17.1
Go OS/Arch: darwin/amd64
I1102 23:48:54.650103 79334 main.go:133] start worker 0
I1102 23:48:54.650327 79334 web.go:89] rest server listen on:2001data/fsDoc
运行状态
http://localhost:2001/api/status1 2 3 4 5 6 7 8 9 10 11 12 13
{
"status": "OK",
"message": {
"crawl": {
"queue_length": 80527,
"retry_queue_length": 28
},
"store": {
"queue_length": 36880,
"retry_queue_length": 0
}
}
}保存的数据
data/fs/*.dat1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55
"from_parser_": "article"article.jsonboard.jsonarticle.jsonconf/parser/*.json进阶使用
使用 cookie
main.gowork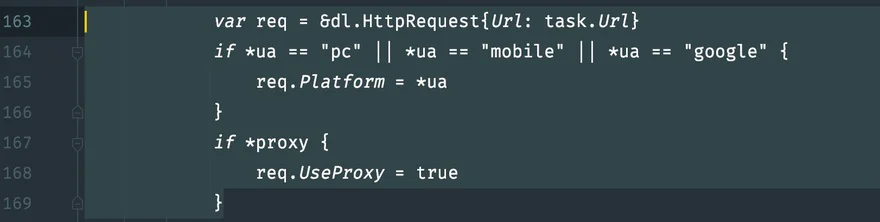
如果同时爬取多个网站就做一个 cookie 字典。
自定义处理结果
可以直接修改这一段
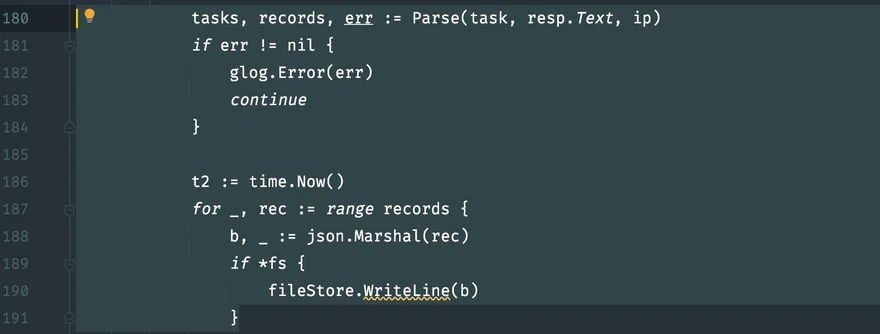
data/fs/*.dat总结
Crawler4U使用 goleveldb 嵌入式数据库保存爬虫状态数据,爬取结果使用 json 文件保存。部署很简单,不需要另配数据库,程序很绿色很环保。
没有 web 配置界面,对初学者来说比较麻烦,但入门后感觉很棒。
参考
本文网址: https://golangnote.com/topic/295.html 转摘请注明来源