
协程(Goroutine)
- G(Goroutine): 即Go协程,每个go关键字都会创建一个协程。
- M(Machine): 工作线程,在Go中称为Machine。
- P(Processor): 处理器(Go中定义的一个摡念,不是指CPU),包含运行Go代码的必要资源,也有调度goroutine的能力。
调度策略
- M要有P才能执行
- p下面会挂着G的队列,p会一直从挂着的队列中拿G运行,或者从其他队列中偷,或者从全局队列中取
- M的数量比P多,因为有些M是当系统调用的时候放弃P,让P给其他M
- 当从系统调用出来,m获取不到p就会把G放入全局队列中
- GOMAXPROCS可以设置p的数量,当io操作比较多的时候可以适当配置多一点
golang函数调用协议
golang调用c语言
add.go
package add
func Add(a, b uint64) uint64
复制代码add.c
#include "runtime.h"
void ·Add(uint64 a, uint64 b, uint64 ret) {
ret = a + b;
FLUSH(&ret);
}
复制代码其中FLUSH是在pkg/runtime/runtime.h中定义为USED(x),这个定义是Go的C编译器自带的primitive,作用是抑制编译器优化掉对*x的赋值的,其实就是go编译器要实现直接修改调用函数的栈,而不是c编译器的修改寄存器的值
多值返回
void f(int arg1, int arg2, int *ret1, int *ret2);
复制代码MOVQ BX,ret1+16(FP)
...
MOVQ BX,ret2+24(FP)
复制代码- golang的多值返回不是像C那样传递多个指针参数进来(修改寄存器中指向值来修改返回参数)
- golang的多值返回汇编层面是直接修改原函数的栈来进行返回,调用函数会预先空置2个内存空位
go关键字
go f(1, 2, 3)
复制代码MOVL $1, 0(SP)
MOVL $2, 4(SP)
MOVL $3, 8(SP)
CALL f(SB)
复制代码MOVL $1, 0(SP)
MOVL $2, 4(SP)
MOVL $3, 8(SP)
PUSHQ $f(SB)
PUSHQ $12
CALL runtime.newproc(SB)
POPQ AX
POPQ AX
复制代码runtime.newprocruntime.newproc(size, f, args)PUSHQPUSHdefer的实现
deferdeferdeferproc()defergoroutinereturnruntime.deferreturndeferreturnruntime.deferreturn连续栈
- goroutine分配固定栈大小, 所以当超出栈大小的时候需要进行扩容
- 每次执行函数调用时Go的runtime都会进行检测,若当前栈的大小不够用,则会触发“中断”,从当前函数进入到Go的运行时库,Go的运行时库会保存此时的函数上下文环境,然后分配一个新的足够大的栈空间,将旧栈的内容拷贝到新栈中,并做一些设置,使得当函数恢复运行时,函数会在新分配的栈中继续执行,仿佛整个过程都没发生过一样,这个函数会觉得自己使用的是一块大小“无限”的栈空间。
Go中的闭包
func f() *Cursor {
var c Cursor
c.X = 500
noinline()
return &c
}
复制代码type Closure struct {
F func()()
i *int
}
复制代码- 原本在函数调用的时候,返回局部变量是不行的,因为是栈上分配,返回后,栈要销毁,但是go语言支持,go会自动地识别出这种情况并在堆上分配c的内存,而不是函数f的栈上
- 闭包是函数和它所引用的环境,闭包在go层面其实是汇编形成的一个结构体
内存管理
内存结构
总结
- golang内存分3部分,arena,bitmap,spans
- 整体内存用heap进行管理,所以heap结构体中有上面3种内存结构,heap中还有central数组进行管理不同类型的span,大小为67*2
- 67代表有67种类型,但是又分有指针和没指针,所以有些数组要*2
- central作为一个全局的内存管理它只管理单个类型的span的列表,分2个一个是空的一个是非空,但是因为多线程防止互相抢锁,所以弄了个线程内的cache来进行给单个线程使用,即而每个线程使用自己内部的cache, 要用从central拿过来不用还回去
- 线程内的cache结构就是134长度的span而已,其实就是代表134种类型的span
- span的意思其实就是管理page,因为每个page都是8kb,然后内部又会细分成多块内存,用来表示不同的类型,但是也不代表一定要内存大小相同才能进行申请内存,然后span本身是个链表就代表着多个page种申请了内存,然后每个span中有地址指向page的开始地址还有span的大小
- arena平分成多个固定大小8kb的page, 然后page内存分割成67种类型的大小, 大小依次按8的倍数增加,然后0代表超过32k大小的对象
- 总体流程就是, 单线程分配不同类型内存去不同类型central抢锁获取span放入自己的cache中,然后不同类型的数量其实就是span链表的长度,每个span其实就是对应page中的类型的地址,而heap就是启动时初始化好的,里面各个结构都是初始化好的,当需要扩容或者缩容的时候就对heap进行操作
内存分布情况
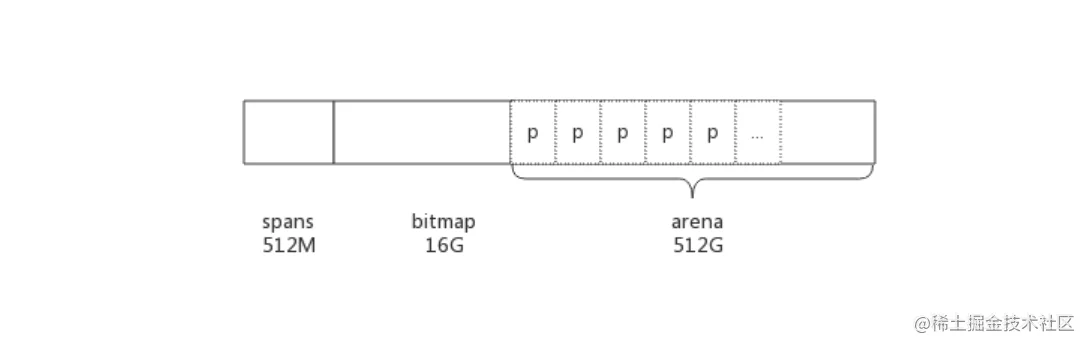
- arena的大小为512G,为了方便管理把arena区域划分成一个个的page,每个page为8KB,一共有512GB/8KB个页;
- spans区域存放span的指针,每个指针对应一个或多个page,所以span区域的大小为(512GB/8KB)*指针大小8byte = 512M
- bitmap区域大小也是通过arena计算出来,不过主要用于GC
class
根据对象大小,划分了一系列class,每个class都代表一个固定大小的对象,以及每个span的大小
span
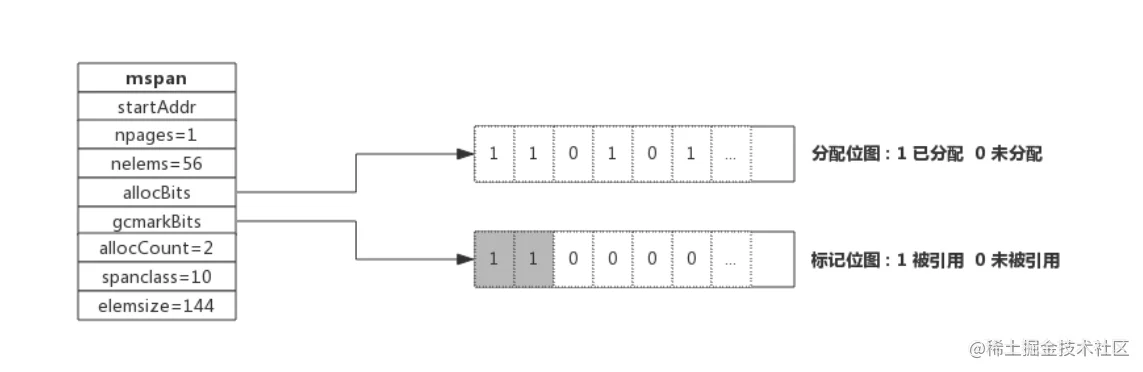
type mspan struct {
next *mspan //链表前向指针,用于将span链接起来
prev *mspan //链表前向指针,用于将span链接起来
startAddr uintptr // 起始地址,也即所管理页的地址
npages uintptr // 管理的页数
nelems uintptr // 块个数,也即有多少个块可供分配
allocBits *gcBits //分配位图,每一位代表一个块是否已分配
allocCount uint16 // 已分配块的个数
spanclass spanClass // class表中的class ID
elemsize uintptr // class表中的对象大小,也即块大小
}
复制代码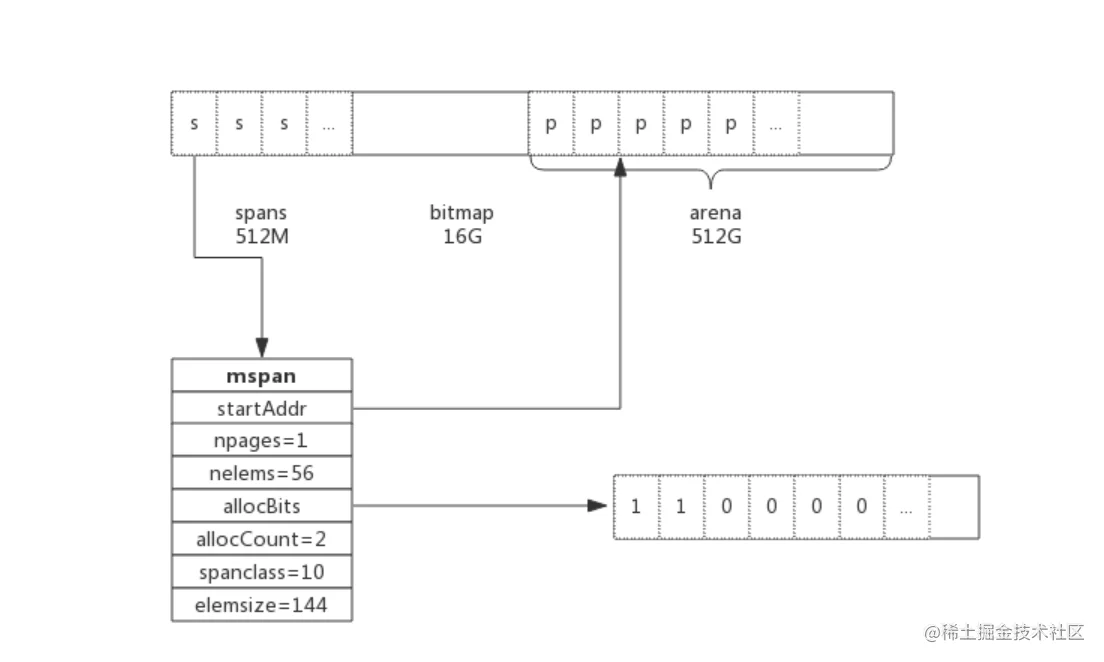
span是用于管理arena页的关键数据结构,每个span中包含1个或多个连续页,为了满足小对象分配,span中的一页会划分更小的粒度,而对于大对象比如超过页大小,则通过多页实现
cache
type mcache struct {
alloc [67*2]*mspan // 按class分组的mspan列表
}
复制代码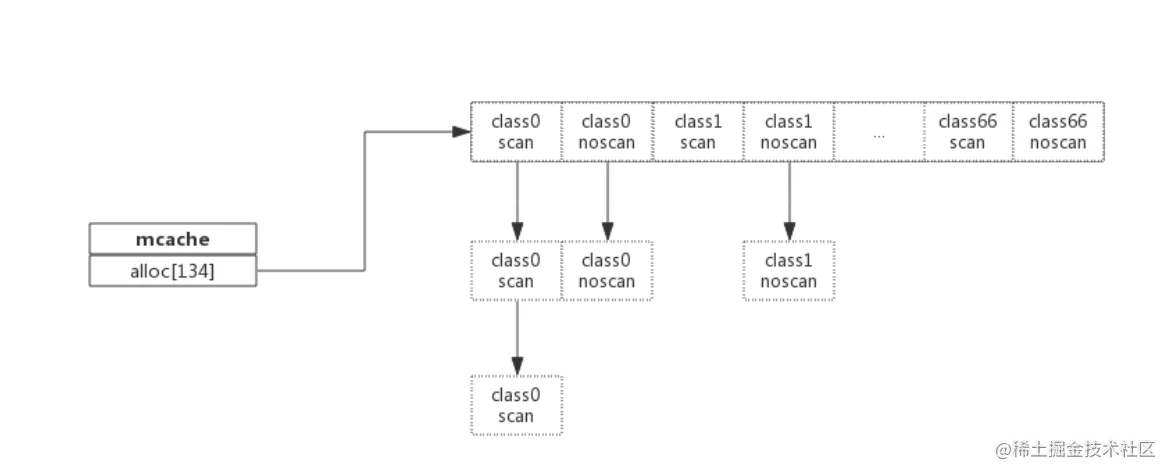
- 有了管理内存的基本单位span,还要有个数据结构来管理span,这个数据结构叫mcentral,各线程需要内存时从mcentral管理的span中申请内存,为了避免多线程申请内存时不断地加锁,Golang为每个线程分配了span的缓存,这个缓存即是cache
- alloc为mspan的指针数组,数组大小为class总数的2倍。数组中每个元素代表了一种class类型的span列表,每种class类型都有两组span列表,第一组列表中所表示的对象中包含了指针,第二组列表中所表示的对象不含有指针,这么做是为了提高GC扫描性能,对于不包含指针的span列表,没必要去扫描。
- 根据对象是否包含指针,将对象分为noscan和scan两类,其中noscan代表没有指针,而scan则代表有指针,需要GC进行扫描
central
type mcentral struct {
lock mutex //互斥锁
spanclass spanClass // span class ID
nonempty mSpanList // non-empty 指还有空闲块的span列表
empty mSpanList // 指没有空闲块的span列表
nmalloc uint64 // 已累计分配的对象个数
}
复制代码cache作为线程的私有资源为单个线程服务,而central则是全局资源,为多个线程服务,当某个线程内存不足时会向central申请,当某个线程释放内存时又会回收进central
heap
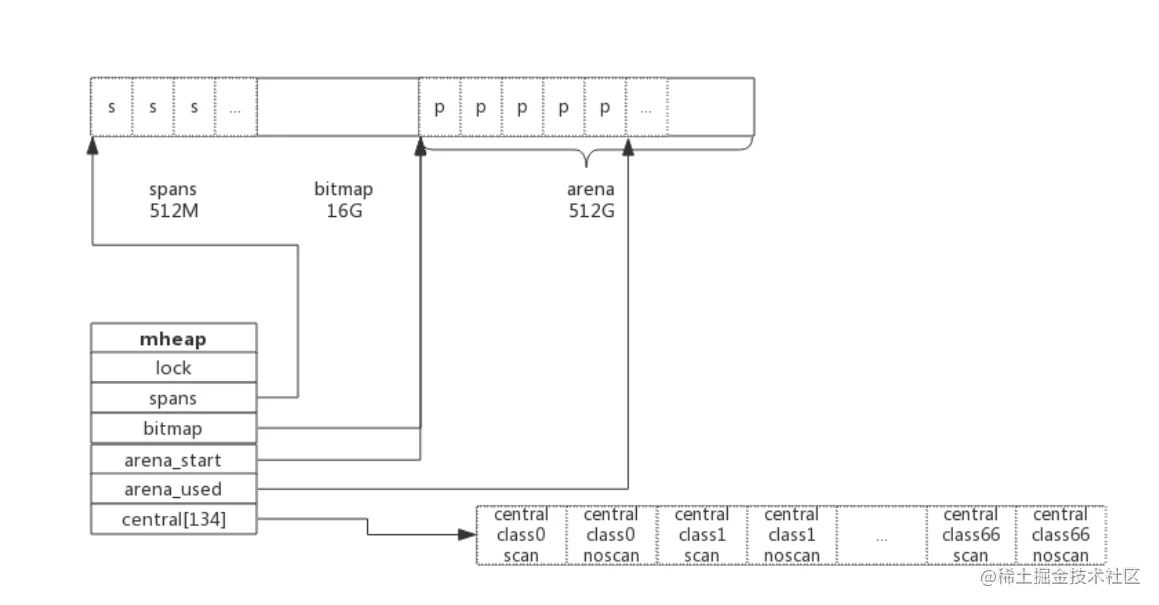
type mheap struct {
lock mutex
spans []*mspan
bitmap uintptr //指向bitmap首地址,bitmap是从高地址向低地址增长的
arena_start uintptr //指示arena区首地址
arena_used uintptr //指示arena区已使用地址位置
central [67*2]struct {
mcentral mcentral
pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte
}
}
复制代码从mcentral数据结构可见,每个mcentral对象只管理特定的class规格的span。事实上每种class都会对应一个mcentral,这个mcentral的集合存放于mheap数据结构中
垃圾回收
垃圾回收算法
- 引用计数:对每个对象维护一个引用计数,当引用该对象的对象被销毁时,引用计数减1,当引用计数器为0时回收该对象。
优点:对象可以很快地被回收,不会出现内存耗尽或达到某个阀值时才回收。
缺点:不能很好地处理循环引用,而且实时维护引用计数,也有一定的代价。
代表语言:Python、PHP、Swift - 标记-清除:从根变量开始遍历所有引用的对象,引用的对象标记为"被引用",没有被标记的进行回收。
优点:解决了引用计数的缺点。
缺点:需要STW,即要暂时停掉程序运行。
代表语言:Golang(其采用三色标记法) - 分代收集:按照对象生命周期长短划分不同的代空间,生命周期长的放入老年代,而短的放入新生代,不同代有不同的回收算法和回收频率。
优点:回收性能好
缺点:算法复杂
代表语言: JAVA
回收标记
三色标记法
- 灰色:对象还在标记队列中等待
- 黑色:对象已被标记,gcmarkBits对应的位为1(该对象不会在本次GC中被清理)
- 白色:对象未被标记,gcmarkBits对应的位为0(该对象将会在本次GC中被清理)
- 其实就是在gc的时候就会从根对象上进行扫描,一般根对象就是栈中的对象
- 刚开始所有对象都是白色,也就是gcmarkBits刚初始化好
- 当被根对象引用的时候,对象就会标记为灰色
- 然后再从被引用对象进行扫描,如果该对象没有引用其他对象或者引用了其他对象都会移入黑色(也即标记gcmarkBits为1),但是引入的其他对象要放入灰色中,本质其实就是扫描各个对象,连带的被根引用最终还是黑色,只是中间扫描阶段是灰色,一旦确定有引用其他对象或者没有引用立马转到黑色中
STW
Golang中的STW(Stop The World)就是停掉所有的goroutine,专心做垃圾回收,待垃圾回收结束后再恢复goroutine,因为类似这种标记清除的算法是要将要内存锁住,要不然一直变化是会出大问题的
辅助GC和
为了防止内存分配过快,在GC执行过程中,如果goroutine需要分配内存,那么这个goroutine会参与一部分GC的工作,即帮助GC做一部分工作
写屏障
写屏障类似一种开关,在GC的特定时机开启,开启后指针传递时会把指针标记,即本轮不回收,下次GC时再确定。 GC过程中新分配的内存会被立即标记,用的并不是写屏障技术,也即GC过程中分配的内存不会在本轮GC中回收
逃逸
逃逸的几种场景
指针逃逸
函数返回值是指针,然后返回的是局部变量的地址,这时候会出现逃逸
栈空间不足逃逸
实际上当栈空间不足以存放当前对象时或无法判断当前切片长度时会将对象分配到堆中
动态类型逃逸
很多函数参数为interface类型,比如fmt.Println(a ...interface{}),编译期间很难确定其参数的具体类型,也会产生逃逸
闭包引用对象逃逸
也就是返回的函数使用了局部变量,该变量成为返回函数的环境变量,这时候该局部变量会逃逸
逃逸总结
- 栈上分配内存比在堆中分配内存有更高的效率
- 栈上分配的内存不需要GC处理
- 堆上分配的内存使用完毕会交给GC处理
- 逃逸分析目的是决定内分配地址是栈还是堆
- 逃逸分析在编译阶段完成
WaitGroup
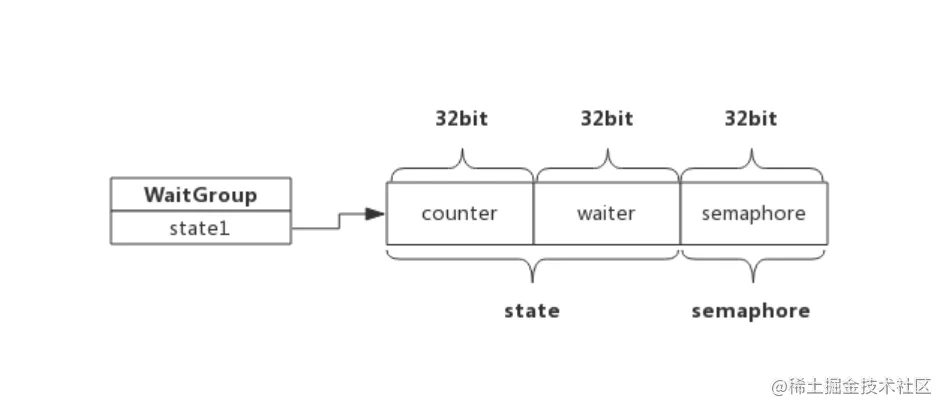
type WaitGroup struct {
state1 [3]uint32
}
复制代码- counter: 当前还未执行结束的goroutine计数器
- waiter count: 等待goroutine-group结束的goroutine数量,即有多少个等候者
- semaphore: 信号量
WaitGroup提供了一下3个方法
- Add(delta int): 将delta值加到counter中
- Wait(): waiter递增1,并阻塞等待信号量semaphore
- Done(): counter递减1,按照waiter数值释放相应次数信号量
总结: 整体的WaitGroup实现很简单,就是add进行添加数量,添加可以是正和负,然后当为0或者为负数的时候然后判定wait数量,对应的就会释放信号量也就是唤醒正在等待的协程,然后wait进行cas等待信号量唤醒,done减去个数
Context
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
复制代码emptyCtxcancelCtxtimerCtxvalueCtx总结: 每种context的构造的时候都是需要父context,context用来代表全局的环境变量,像cancel自己关闭了会递归把子也关闭,然后构建的时候会把自己放入父类的child种,当父类没有child属性就会用协程等待父类done触发,然后timerCtx差不多只是有个定时去关闭的任务,valueCtx从父类找不到会去父类找
反射
- 反射是一种检查interface变量的底层类型和值的机制
- interface类型有个(value,type)对
- 反射有2个方法reflect.Type和reflect.Value分别是获取interface的value和type
- 反射分别有2个对象reflect.Type和reflect.Value是用来接收interface的value和type
- 反射可以将interface类型变量转换成反射对象
- 反射可以将反射对象还原成interface对象
- 反射对象可修改,value值必须是可设置的(不是值对象,因为传值只会是一份拷贝)