
golang在1.1版本之后引入了任务窃取调度器,效率比之前有了较大提升。本文通过分析golang的任务调度过程提取调度器的设计灵感。
数据结构
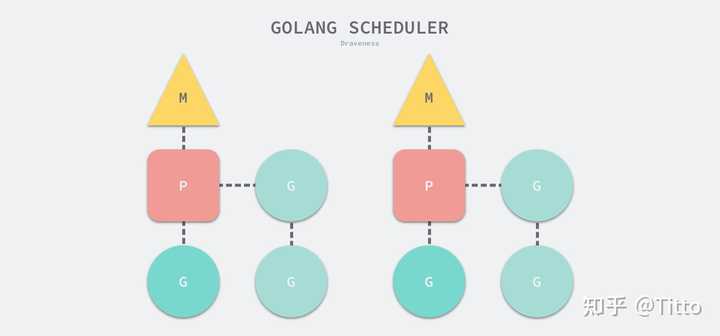
- G — 表示 Goroutine,它是一个待执行的任务;
- M — 表示操作系统的线程,它由操作系统的调度器调度和管理;
- P — 表示处理器,它可以被看做运行在线程上的本地调度器;
任务调度
调度代码见proc.go文件
func schedule() {
_g_ := getg()
if _g_.m.locks != 0 {
throw("schedule: holding locks")
}
...
top:
pp := _g_.m.p.ptr()
pp.preempt = false
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
...
var gp *g
var inheritTime bool
...
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
// 偶尔检查一下全局任务队列以确保公平性,防止两个任务相互唤醒占据本地的任务队列
// 偶尔体现在 _g_.m.p.ptr().schedtick%61 == 0
// 每执行 60 次任务就试着从全局任务队列获取任务(?猜测)
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
// 从全局队列中获取 1 个任务
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
// 从本地队列获取任务
gp, inheritTime = runqget(_g_.m.p.ptr())
// We can see gp != nil here even if the M is spinning,
// if checkTimers added a local goroutine via goready.
}
if gp == nil {
// 阻塞式地获取任务
// 可能会从全局队列、网络、任务窃取等多个方面获取任务
gp, inheritTime = findrunnable() // blocks until work is available
}
// This thread is going to run a goroutine and is not spinning anymore,
// so if it was marked as spinning we need to reset it now and potentially
// start a new spinning M.
if _g_.m.spinning {
resetspinning()
}
...
// 执行任务
execute(gp, inheritTime)
}
从全局队列中获取任务
// 第 36 行代码处
gp = globrunqget(_g_.m.p.ptr(), 1)
// Try get a batch of G's from the global runnable queue.
// sched.lock must be held.
func globrunqget(_p_ *p, max int32) *g {
assertLockHeld(&sched.lock)
if sched.runqsize == 0 {
return nil
}
n := sched.runqsize/gomaxprocs + 1
if n > sched.runqsize {
n = sched.runqsize
}
if max > 0 && n > max {
n = max
}
// 最多只能从全局队列取一半的任务
if n > int32(len(_p_.runq))/2 {
n = int32(len(_p_.runq)) / 2
}
// 更新还剩下的全局队列任务数量
sched.runqsize -= n
// 从全局队列弹出需要执行的任务
gp := sched.runq.pop()
n--
for ; n > 0; n-- {
// 其他从全局队列拿到的任务放到当前调度器的本地队列中
gp1 := sched.runq.pop()
runqput(_p_, gp1, false)
}
return gp
}
向本地队列添加任务
// 第 33 行代码
// runqput tries to put g on the local runnable queue.
// If next is false, runqput adds g to the tail of the runnable queue.
// If next is true, runqput puts g in the _p_.runnext slot.
// If the run queue is full, runnext puts g on the global queue.
// Executed only by the owner P.
// 如果 next 为 false,将任务添加到本地队列队尾
// 如果 next 为 true,将任务添加到 _p_.runnext,作为下一个执行的任务,缓存作用
// 如果本地队列已满,则添加到全局队列
func runqput(_p_ *p, gp *g, next bool) {
// randomizeScheduler 为是否随机调度
// 即使 next 为真,仍然有一定概率不缓存
if randomizeScheduler && next && fastrandn(2) == 0 {
next = false
}
if next {
retryNext:
oldnext := _p_.runnext
if !_p_.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) {
goto retryNext
}
if oldnext == 0 {
return
}
// Kick the old runnext out to the regular run queue.
gp = oldnext.ptr()
}
retry:
// 队头
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
// 队尾
t := _p_.runqtail
// 本地队列未满
if t-h < uint32(len(_p_.runq)) {
// 任务添加到队尾
_p_.runq[t%uint32(len(_p_.runq))].set(gp)
// 队尾更新
atomic.StoreRel(&_p_.runqtail, t+1) // store-release, makes the item available for consumption
return
}
// 本地队列已满,添加到全局队列中
if runqputslow(_p_, gp, h, t) {
return
}
// the queue is not full, now the put above must succeed
goto retry
}
向全局队列添加任务
// Put g and a batch of work from local runnable queue on global queue.
// Executed only by the owner P.
// 将本地队列任务取出并打包之后再放到全局队列上
func runqputslow(_p_ *p, gp *g, h, t uint32) bool {
var batch [len(_p_.runq)/2 + 1]*g
// First, grab a batch from local queue.
// 从本地队列取出一半任务并打包
n := t - h
n = n / 2
if n != uint32(len(_p_.runq)/2) {
throw("runqputslow: queue is not full")
}
for i := uint32(0); i < n; i++ {
batch[i] = _p_.runq[(h+i)%uint32(len(_p_.runq))].ptr()
}
if !atomic.CasRel(&_p_.runqhead, h, h+n) { // cas-release, commits consume
return false
}
batch[n] = gp
// 是否需要随机调度,即打乱顺序来
if randomizeScheduler {
for i := uint32(1); i <= n; i++ {
j := fastrandn(i + 1)
batch[i], batch[j] = batch[j], batch[i]
}
}
// Link the goroutines.
// 像链表一样通过 schedlink 前后链接起来
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}
var q gQueue
q.head.set(batch[0])
q.tail.set(batch[n])
// Now put the batch on global queue.
lock(&sched.lock)
// 将打包的任务添加到全局队列
globrunqputbatch(&q, int32(n+1))
unlock(&sched.lock)
return true
}
从本地队列获取任务
// 第 42 行代码处
gp, inheritTime = runqget(_g_.m.p.ptr())
// Get g from local runnable queue.
// If inheritTime is true, gp should inherit the remaining time in the
// current time slice. Otherwise, it should start a new time slice.
// Executed only by the owner P.
func runqget(_p_ *p) (gp *g, inheritTime bool) {
// _p_.runnext 缓存了下一个需要执行的任务
next := _p_.runnext
// If the runnext is non-0 and the CAS fails, it could only have been stolen by another P,
// because other Ps can race to set runnext to 0, but only the current P can set it to non-0.
// Hence, there's no need to retry this CAS if it falls.
if next != 0 && _p_.runnext.cas(next, 0) {
return next.ptr(), true
}
for {
// 队头
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with other consumers
// 队尾
t := _p_.runqtail
// 队列为空
if t == h {
return nil, false
}
// 从本地队列头部取出一个任务
gp := _p_.runq[h%uint32(len(_p_.runq))].ptr()
// 队头更新
if atomic.CasRel(&_p_.runqhead, h, h+1) { // cas-release, commits consume
return gp, false
}
}
}
从多个地方获取任务
// 第 49 行
// 可能会从全局队列、网络、任务窃取等多个方面获取任务
gp, inheritTime = findrunnable() // blocks until work is available
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from local or global queue, poll network.
func findrunnable() (gp *g, inheritTime bool) {
...
// local runq
// 从本地队列获取任务
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// 从全局队列获取任务
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
// 从网络中获取任务
// Poll network.
// This netpoll is only an optimization before we resort to stealing.
// We can safely skip it if there are no waiters or a thread is blocked
// in netpoll already. If there is any kind of logical race with that
// blocked thread (e.g. it has already returned from netpoll, but does
// not set lastpoll yet), this thread will do blocking netpoll below
// anyway.
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Load64(&sched.lastpoll) != 0 {
if list := netpoll(0); !list.empty() { // non-blocking
gp := list.pop()
// 下方有对此函数的具体功能描述
injectglist(&list)
...
return gp, false
}
}
// 任务窃取
// Spinning Ms: steal work from other Ps.
//
// Limit the number of spinning Ms to half the number of busy Ps.
// This is necessary to prevent excessive CPU consumption when
// GOMAXPROCS>>1 but the program parallelism is low.
procs := uint32(gomaxprocs)
if _g_.m.spinning || 2*atomic.Load(&sched.nmspinning) < procs-atomic.Load(&sched.npidle) {
if !_g_.m.spinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
gp, inheritTime, tnow, w, newWork := stealWork(now)
now = tnow
if gp != nil {
// Successfully stole.
return gp, inheritTime
}
if newWork {
// There may be new timer or GC work; restart to
// discover.
goto top
}
if w != 0 && (pollUntil == 0 || w < pollUntil) {
// Earlier timer to wait for.
pollUntil = w
}
}
}
// injectglist adds each runnable G on the list to some run queue,
// and clears glist. If there is no current P, they are added to the
// global queue, and up to npidle M's are started to run them.
// Otherwise, for each idle P, this adds a G to the global queue
// and starts an M. Any remaining G's are added to the current P's
// local run queue.
// 这个函数会把任务添加到一些队列中
// 如果没有调度线程,这些任务将会被添加到全局队列中,并且将会唤醒 idle 调度线程
// 如果有调度线程,那么会将与 idle 调度线程相等数量的任务添加到全局队列中,并唤醒这些 idle 调度线程
// 剩下的其他任务会添加到调度线程的本地队列中
func injectglist(glist *gList) {}
以任务窃取方式获取任务
// stealWork attempts to steal a runnable goroutine or timer from any P.
//
// If newWork is true, new work may have been readied.
//
// If now is not 0 it is the current time. stealWork returns the passed time or
// the current time if now was passed as 0.
func stealWork(now int64) (gp *g, inheritTime bool, rnow, pollUntil int64, newWork bool) {
// 当前调度器线程
pp := getg().m.p.ptr()
ranTimer := false
const stealTries = 4
for i := 0; i < stealTries; i++ {
stealTimersOrRunNextG := i == stealTries-1
// 随机选择一个调度器窃取,不能是当前本身
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
if sched.gcwaiting != 0 {
// GC work may be available.
return nil, false, now, pollUntil, true
}
// 随机一个调度器 p2
p2 := allp[enum.position()]
// 不能是当前调度器本身
if pp == p2 {
continue
}
// 窃取定时器任务,这部分不是重点,先不考虑
if stealTimersOrRunNextG && timerpMask.read(enum.position()) {
...
}
// Don't bother to attempt to steal if p2 is idle.
// 不能是 idle 调度器
if !idlepMask.read(enum.position()) {
// 从 p2 窃取任务
if gp := runqsteal(pp, p2, stealTimersOrRunNextG); gp != nil {
return gp, false, now, pollUntil, ranTimer
}
}
}
}
// No goroutines found to steal. Regardless, running a timer may have
// made some goroutine ready that we missed. Indicate the next timer to
// wait for.
return nil, false, now, pollUntil, ranTimer
}
// Steal half of elements from local runnable queue of p2
// and put onto local runnable queue of p.
// Returns one of the stolen elements (or nil if failed).
// 从 p2 的任务队列中窃取一半的任务过来
// 放入到当前调度器的本地队列中
func runqsteal(_p_, p2 *p, stealRunNextG bool) *g {
t := _p_.runqtail
n := runqgrab(p2, &_p_.runq, t, stealRunNextG)
if n == 0 {
return nil
}
n--
gp := _p_.runq[(t+n)%uint32(len(_p_.runq))].ptr()
if n == 0 {
return gp
}
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with consumers
if t-h+n >= uint32(len(_p_.runq)) {
throw("runqsteal: runq overflow")
}
atomic.StoreRel(&_p_.runqtail, t+n) // store-release, makes the item available for consumption
return gp
}
// Grabs a batch of goroutines from _p_'s runnable queue into batch.
// Batch is a ring buffer starting at batchHead.
// Returns number of grabbed goroutines.
// Can be executed by any P.
// _p_ 是被窃取调度器
// batch 是窃取者队列
// batchHead 为窃取者队列的队尾索引
func runqgrab(_p_ *p, batch *[256]guintptr, batchHead uint32, stealRunNextG bool) uint32 {
for {
h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with other consumers
t := atomic.LoadAcq(&_p_.runqtail) // load-acquire, synchronize with the producer
n := t - h
// 一半数量
n = n - n/2
// 队列为空,会尝试获取 被窃取调度器缓存的任务 __runnext__
// __runnext__ 在 runqput() 出现过
if n == 0 {
if stealRunNextG {
// Try to steal from _p_.runnext.
if next := _p_.runnext; next != 0 {
if _p_.status == _Prunning {
// Sleep to ensure that _p_ isn't about to run the g
// we are about to steal.
// The important use case here is when the g running
// on _p_ ready()s another g and then almost
// immediately blocks. Instead of stealing runnext
// in this window, back off to give _p_ a chance to
// schedule runnext. This will avoid thrashing gs
// between different Ps.
// A sync chan send/recv takes ~50ns as of time of
// writing, so 3us gives ~50x overshoot.
if GOOS != "windows" {
usleep(3)
} else {
// On windows system timer granularity is
// 1-15ms, which is way too much for this
// optimization. So just yield.
osyield()
}
}
if !_p_.runnext.cas(next, 0) {
continue
}
// 将窃取任务添加到队尾
batch[batchHead%uint32(len(batch))] = next
return 1
}
}
return 0
}
if n > uint32(len(_p_.runq)/2) { // read inconsistent h and t
continue
}
for i := uint32(0); i < n; i++ {
// 从 _p_ 本地队列取出任务
g := _p_.runq[(h+i)%uint32(len(_p_.runq))]
// 添加到队尾
batch[(batchHead+i)%uint32(len(batch))] = g
}
// 更新 _p_ 的队头,说明任务已被窃取
if atomic.CasRel(&_p_.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}
}