
写在前面
深信服面试起来感觉有点偏向应用,没有涉及高并发等等内容,想想也确实,深信服更多偏向B端。业务能力扎实也是应该的。深信服挺好的,但我想找toc的,就拒掉了。。
一面
了解过切片和数组吗?有什么区别?
切片的底层其实是数组,数组是不可变长度的,而切片是可变长度的。
那这样初始化可以吗?有什么问题?
make去创建语法糖 array:=[]int{}用过map吧?怎么遍历map?
那遍历 map 是有序的吗?
无序的
为什么是无序的?
随机值序号随机的 cell 按序遍历 bucket扩容用过chan吧?怎么声明一个chan呢?
chan是引用类型,一般我们应该用make去创建一个chan
怎么发消息给chan呢?
给一个关闭的chan发消息会怎么样?
会引起panic
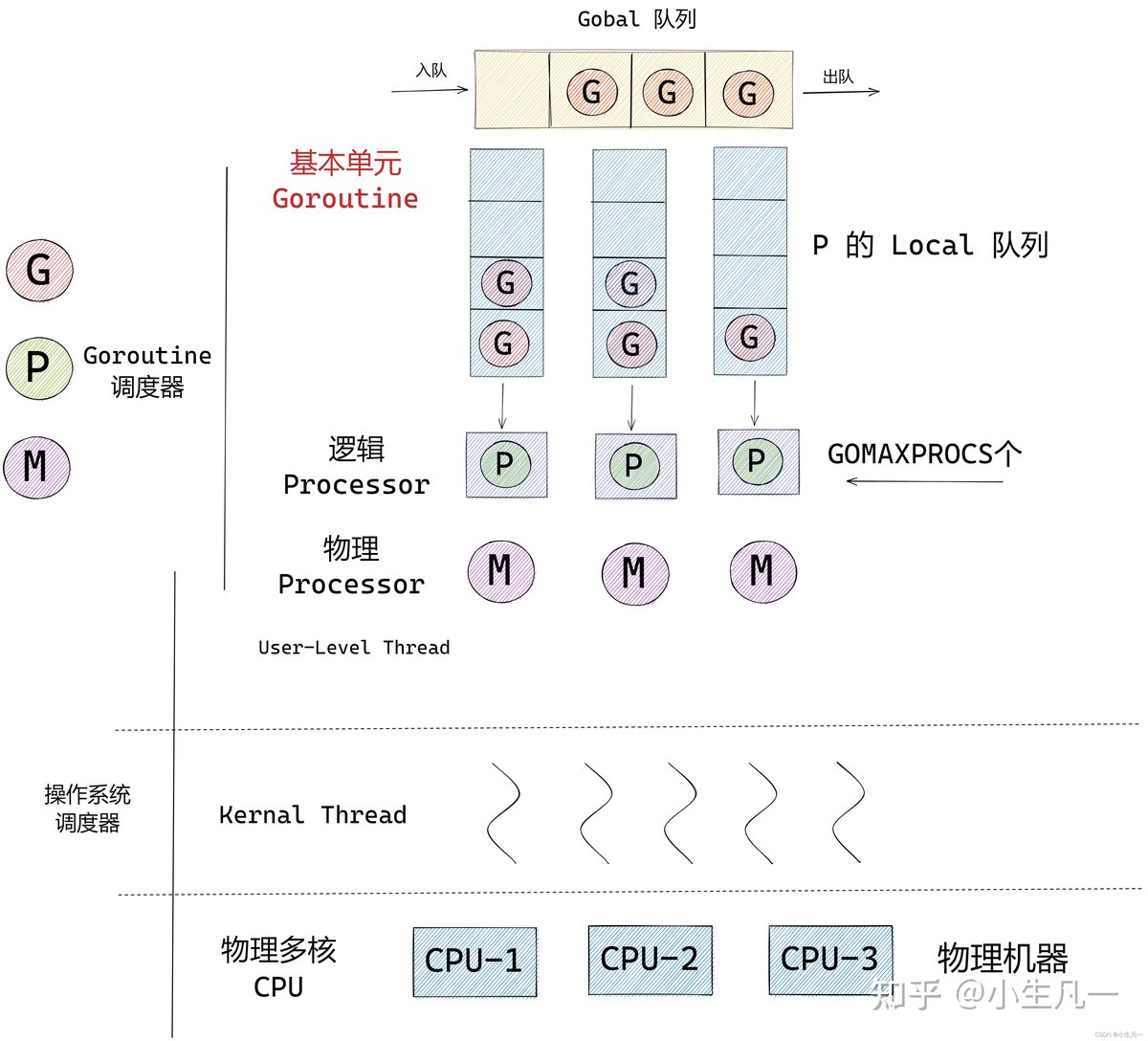
讲讲 GMP 吧
可以重用逻辑处理单元P 和 M 的这种关系就相当于 Linux 系统中的用户层面的线程和内核的线程是一样的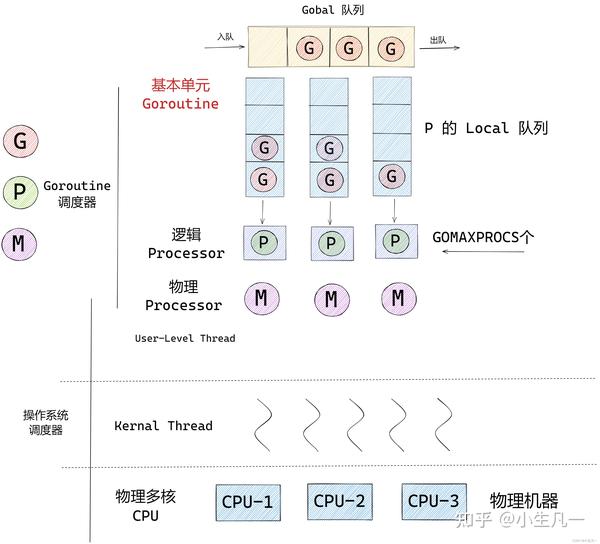
那GC有了解过吗?
on-the-fly原理如下
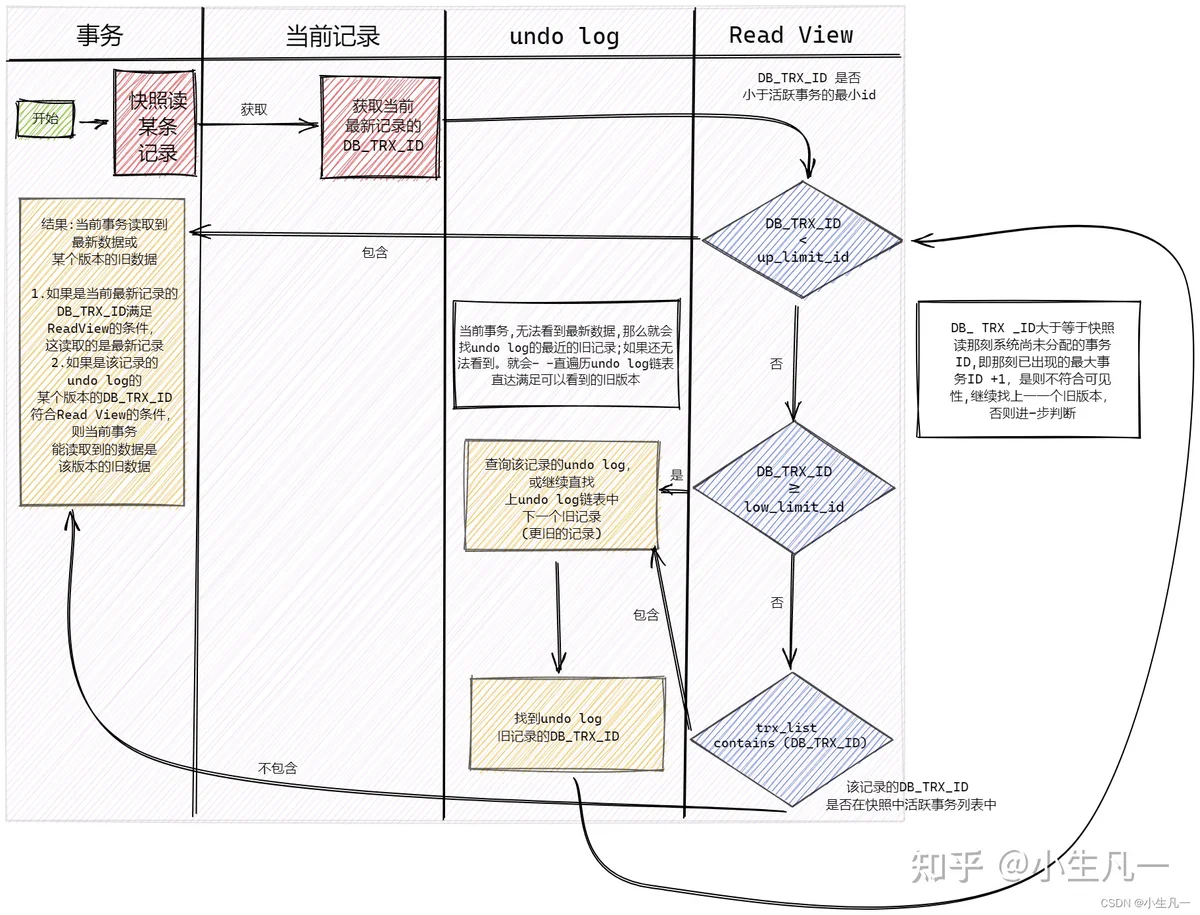
stop the worldstop the worldwritebarrieron-the-flymysql 有用过吧?MVCC 是怎么实现的?
3个隐式字段,undo日志 ,Read View- 隐式字段
每行记录除了我们自定义的字段外,还有数据库隐式定义的 DB_TRX_ID, DB_ROLL_PTR, DB_ROW_ID 等字段
最近修改(修改/插入)事务 ID回滚指针隐含的自增 ID(隐藏主键)- undo日志
- insert undo log:代表事务在 insert 新记录时产生的 undo log,只在事务回滚时需要,并且在事务提交后可以被立即丢弃。
- update undo log:事务在进行 update 或 delete 时产生的 undo log ,不仅在事务回滚时需要,在快照读时也需要;所以不能随便删除,只有在快速读或事务回滚不涉及该日志时,对应的日志才会被 purge线程统一清除。
- Read View
记录并维护系统当前活跃事务的 ID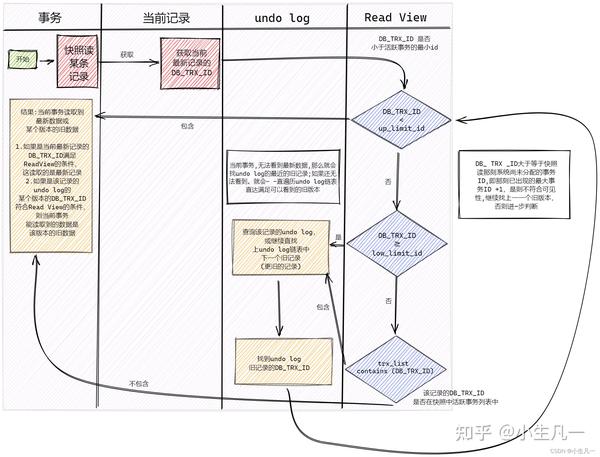
mysql 的锁是怎么实现的?
当时确实没了解如何实现的,只知道如何for update这些,可以看这篇博客,很详细了。
用过gin是吧?gin是怎么处理请求的?
Gin其实是通过一个context来进行上下文的传递,将这个传递参数,参数返回。
如果有一个业务给你,你怎么写这个请求?
首先肯定是传统的MVC模型来进行操作。
controller层来接受请求,service层来进行请求的处理,dao层来写sql语句。
算法:将重复的元素移到最后
二面
二面基本都是跟着项目走。
如果你的系统突然多了10w的访问量,你要怎么处理?
- nginx来进行负载均衡。
- 用户验证的信息的过期时间设置长一点,以免发生缓冲雪崩的问题。
- 设置布尔过滤器。
- 检查sql语句,是否符合要求,是否是慢sql,如果是则解决。
redis用过是吧?说说你在项目里面的排行榜?你说说redis的底层是怎么处理的?
redis.h/zskiplistNoderedis.h/zskiplistzskiplistNodezskiplist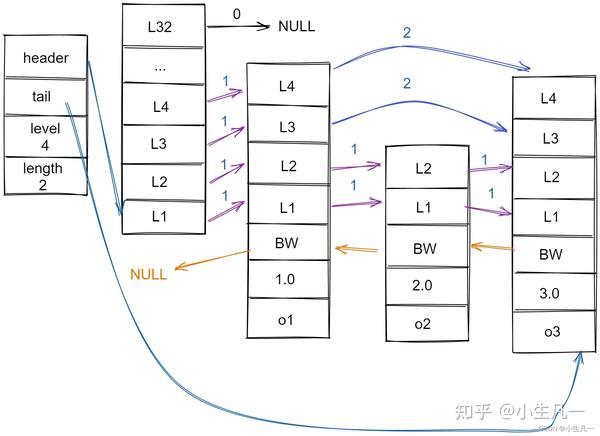
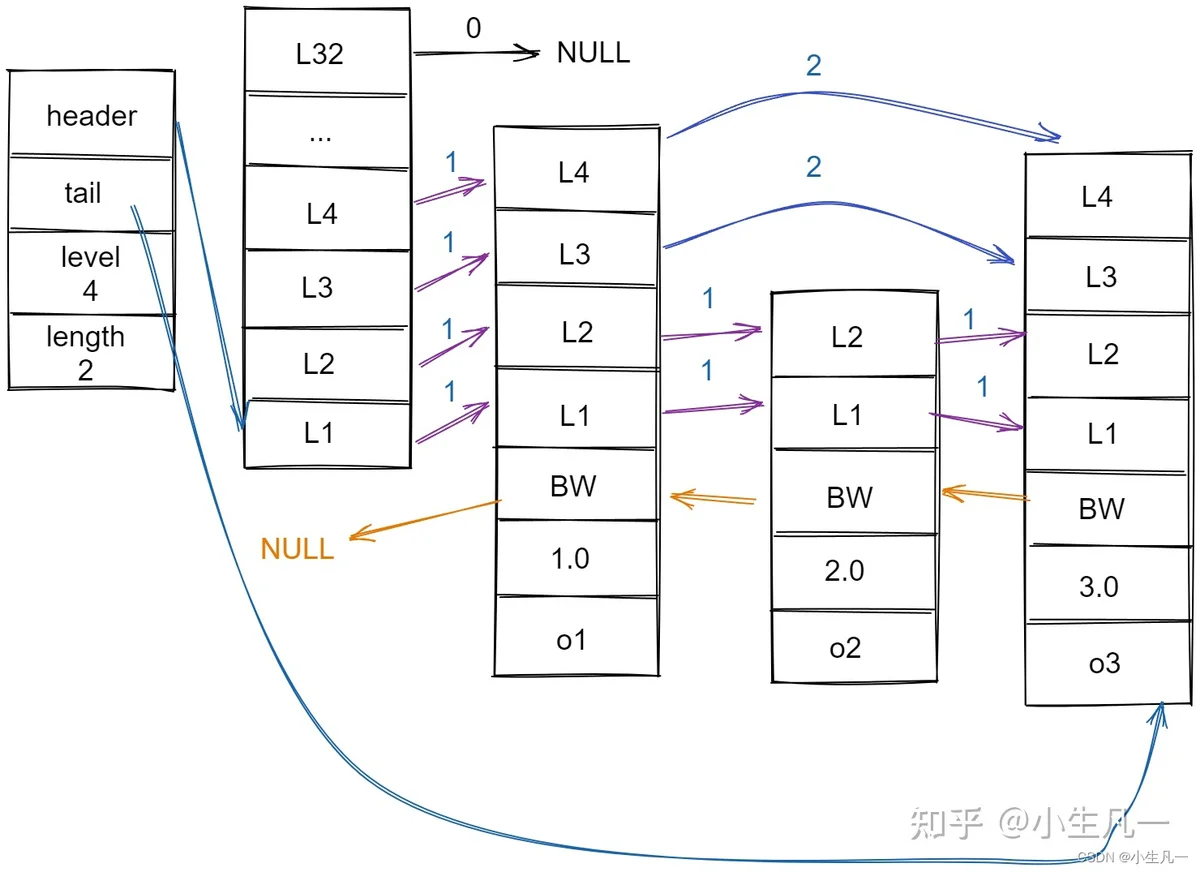
上图中展示了一个跳跃表示例,最左边的就是 zskiplist 结构。
最大的那个节点的层数前进指针和跨度节点中用BW字样标记的后退指针,他指向当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。