
在前面的文章中介绍了pprof的用法(golang性能分析工具指南--pprof),pprof属于相对宏观的工具,能够知道哪个函数耗费了多少CPU,分配了多少内存。如果想要知道程序中更加细节的指标,比如一共有多少goroutine,每个goroutine执行了多长时间,gc的时间线,程序cpu使用率的时间线等等等等,pprof都是无能为力的,更加细节的就要通过今天讲的trace工具了。
本文会从下面几个方面讲:
1、 如何开启trace:也是分为web服务和非web服务
2、如何分析程序轨迹:带你看懂界面上显示的指标
3、 对goroutine的分析:看懂各个goroutine上耗时
4、 go tool trace 的一些额外功能
本文准备了一些代码,有兴趣的可以看(不看一点也不影响看下文):
https://github.com/helios741/myblog/tree/new/learn_go/go_stace

web端需要开启在程序中开启pprof,代码如下:
import _ "net/http/pprof"go func() {log.Println(http.ListenAndServe(":6060", nil))}()
然后将trace生成的trace文件下载到本地:
curl http://172.26.42.228:6060/debug/pprof/trace -o trace.out
在通过go tool trace trace.out就能看到后续要分析的界面了。
非web端需要加一些额外的代码,如下:
import ("runtime/trace")// trace 的输出路径f, _ := os.Create("trace.out")defer f.Close()trace.Start(f)defer trace.Stop()
然后run 一遍程序就能得到trace.out文件了(如果懒的写可以参考,我提供的代码),通过go tool trace trace.out就能看到后续要分析的界面了。
当执行过go tool trace trace.out之后映入眼帘就是下图:

这其实也挺容易理解的:
| 内容 | 含义 |
| View trace | 查看程序轨迹 |
| Goroutine analysis | 对程序goroutine的分析 |
| Network blocking profile (⬇) | 网络阻塞分析 |
| Synchronization blocking profile (⬇) | 同步阻塞分析 |
| Syscall blocking profile (⬇) | 系统调用阻塞分析 |
| Scheduler latency profile (⬇) | go调度器的延时 |
| User-defined tasks | 用户自定义任务 |
| User-defined regions | 用户自定义任务 |
| Minimum mutator utilization | 内存分配器的最小利用率 |
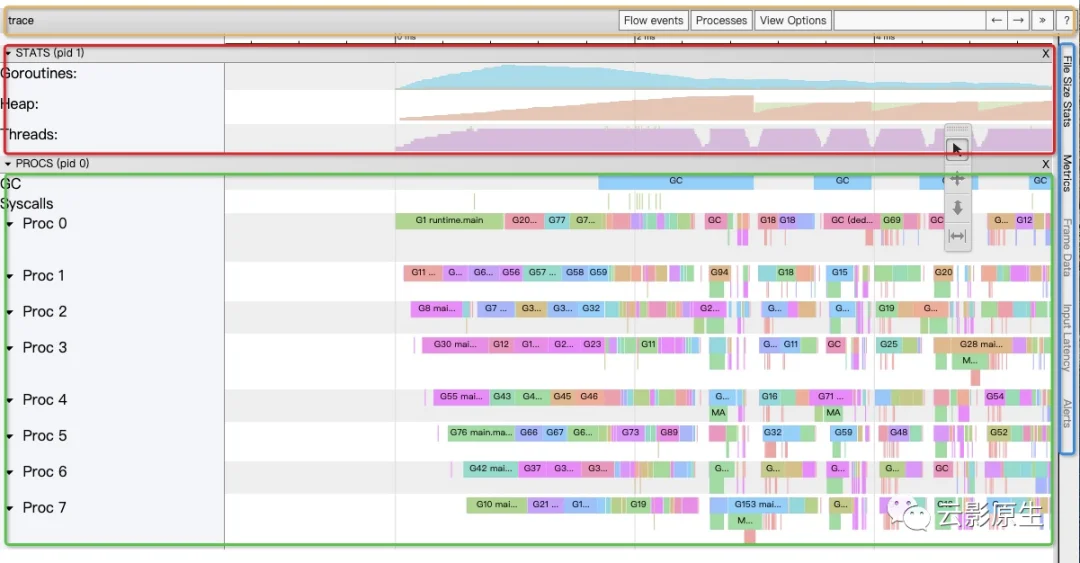
我把这个区域分为了四个部分,我们从上到下依次来看:
1、trace(淡黄色框框)这一列主要是负责筛选和搜索功能。
| 内容 | 含义 | 示例 |
| Flow events | 事件关系,默认不展示,因为展示会比较乱 | 展示出来就拧麻花了
|
| Processes | 控制STATS(红框)和PROCS(绿色框)的展示 | 无 |
| view Options | 暂时没啥用 | |
| 搜索框 | 搜索在PROCS(绿色)看到的内容 | 比如我只想看mark事件
|
| ←/→ | 搜索到的内容前进后退 | |
| ? | 这个面板的帮助功能 |
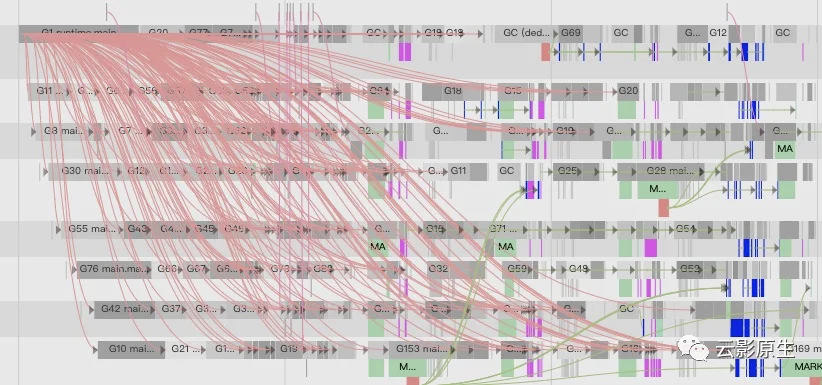

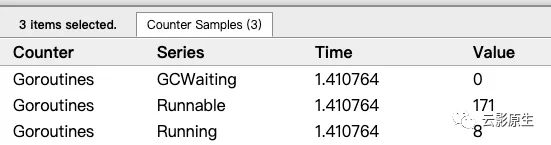

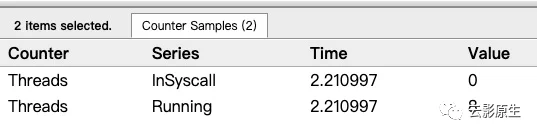
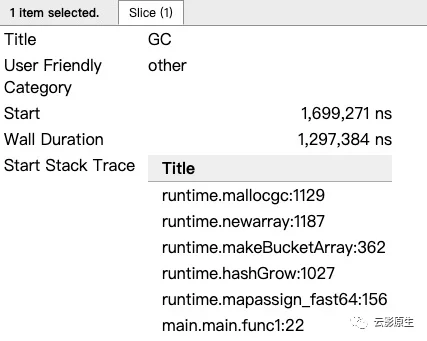
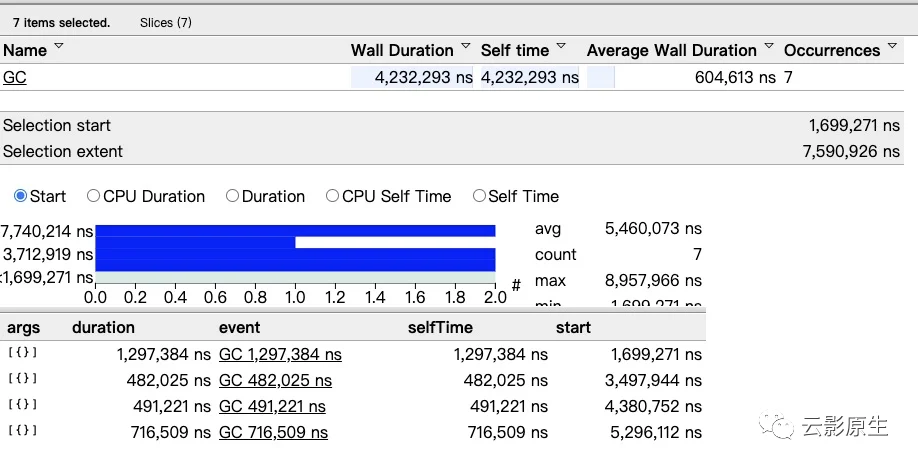

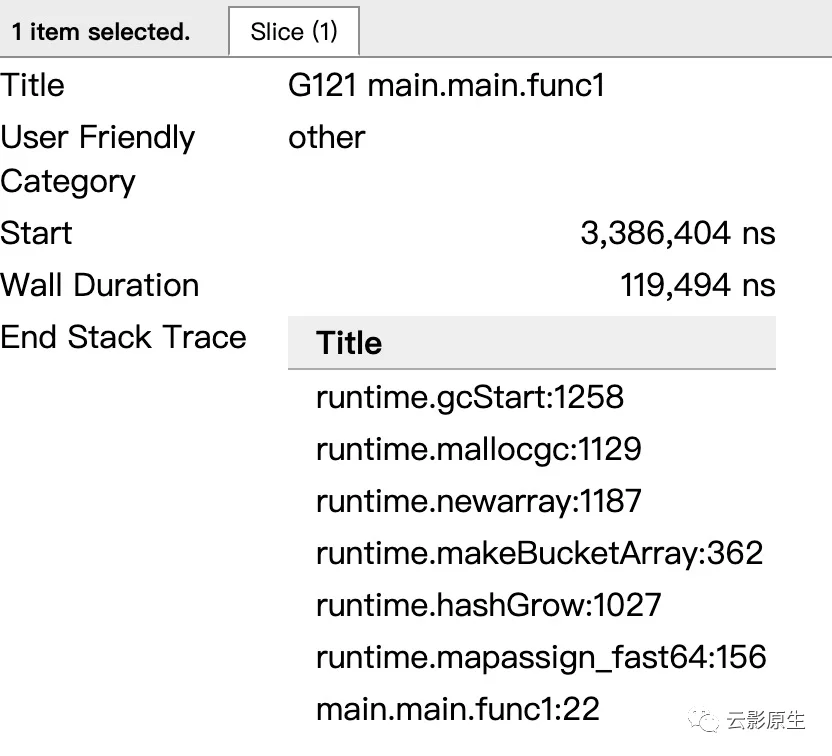
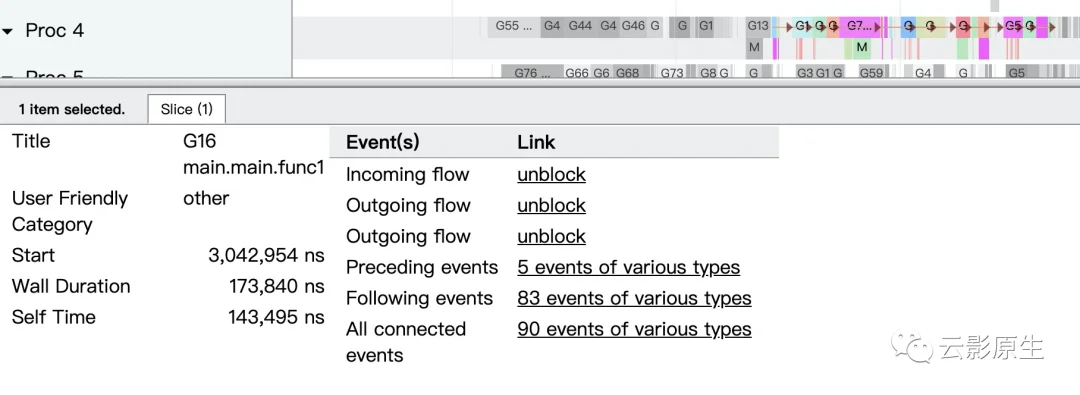
对程序的goroutine分析
现在我们回到最开始打开的界面
点开第二个就是本节需要分析的重点,首先看到的是有多少种类的goroutine

我们主要分析main.mian.func1就行,因为那是我们的程序执行的(runtime.gcBgMarkWorker表示GC的标记阶段、runtime.bgsweep表示GC的清扫阶段、runtime.bgscavenge表示内存分配阶段)。
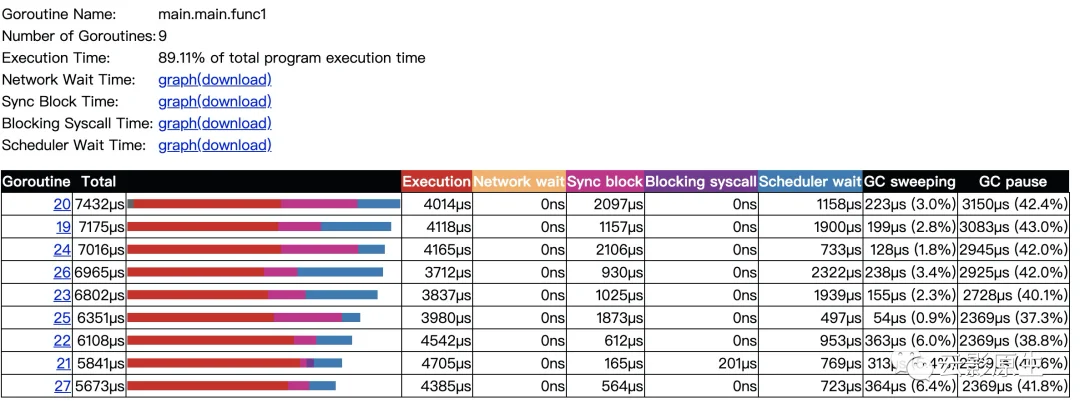
这个图可以说是,简洁又清晰呀。基本都不用多说什么,把表格中的字段信息说一下,按照第一行为例:
| 内容 | 含义 | 解释 |
| Goroutine | 第20个goroutine. | 点开之后针对这个goroutine的分析 |
| total | 总共耗费了7432µs | |
| Execution | 执行耗时4014µs | |
| Network wait | 网络等待了0µs | |
| Sync block | 同步阻塞了2097µs | |
| Blocking syscall | 系统调用阻塞0µs | |
| Scheduler wait | 调度阻塞1158µs | |
| GC sweeping | GC清扫了223µs | |
| GC pause | GC暂停了3150µs |

我们上面讲了讲个最重要的,其实下面的也很重要但是很容易懂,比如Network blocking profile、Synchronization blocking profile、Syscall blocking profile、Scheduler latency profile 中都是和golang性能分析工具指南--pprof中的调用图,是一样的。比如我们看一下Scheduler latency profile:
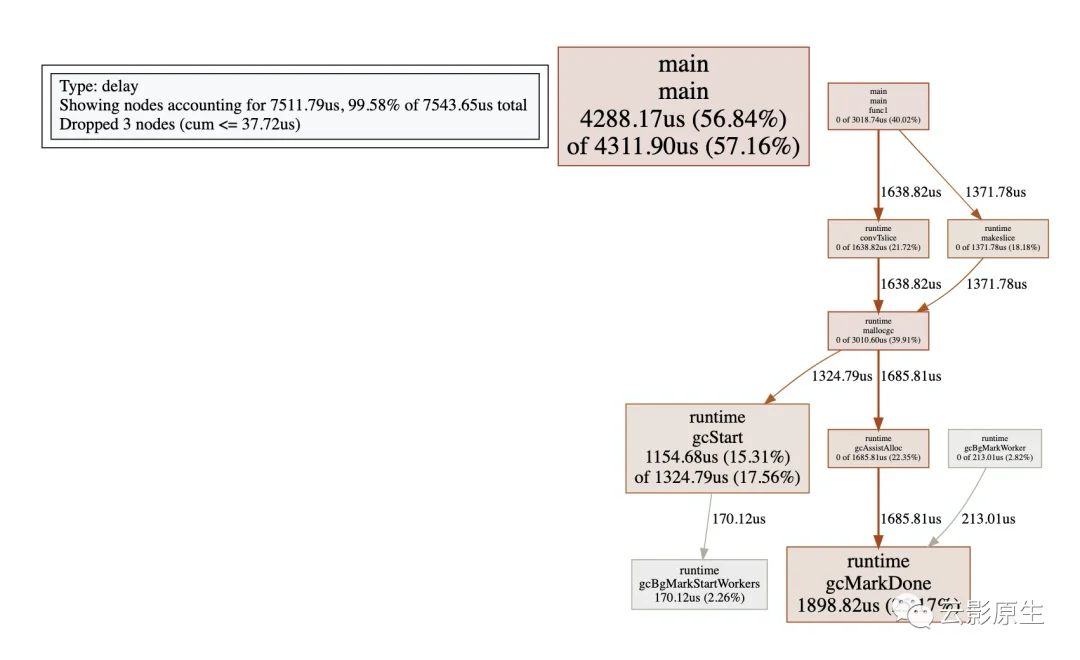
我们其实能够很清晰的看出是哪里的问题。
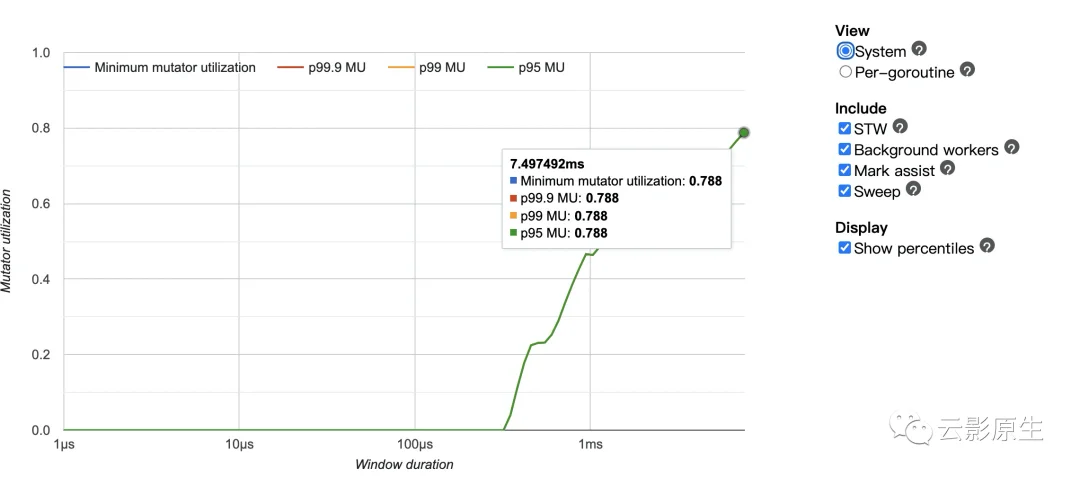
我们能看到MMU是将近80%。这就告诉你的程序在将近80%不会受到GC的影响。
最后介绍一个gctrace的命令:
GODEBUG=gctrace=1 go run easy.go
会输出如下的结果:
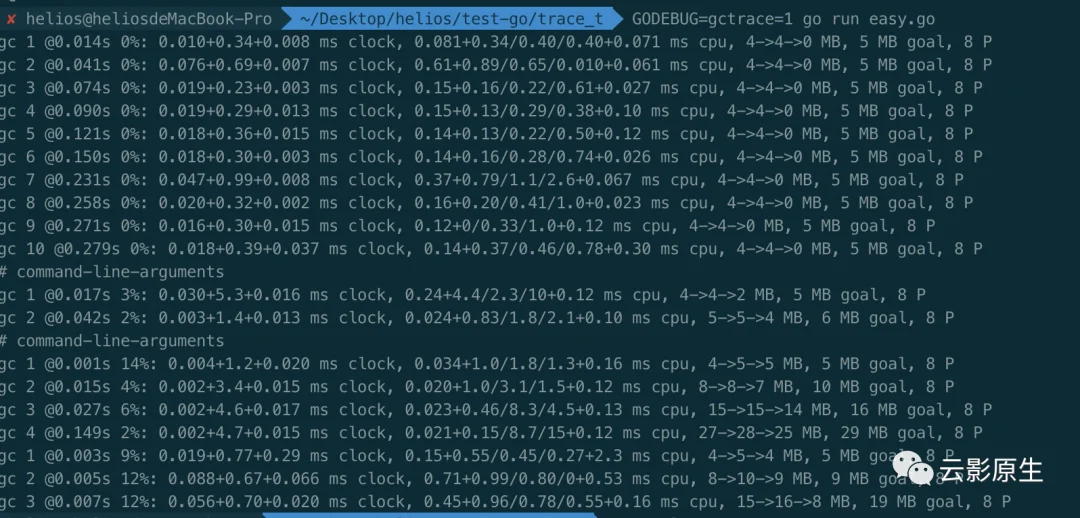
输出的格式如下:
gc # @#s #%: #+#+# ms clock, #+#/#/#+# ms cpu, #->#-># MB, # MB goal, # P
我们以这一条举例来详细说一下:
gc 2 @0.015s 4%: 0.002+3.4+0.015 ms clock, 0.020+1.0/3.1/1.5+0.12 ms cpu, 8->8->7 MB, 10 MB goal, 8 P
| 内容 | 含义 | 输出格式 |
| gc 2 | gc number,递增的 | gc # |
| @0.015s | 发生的时间,开始是0s | @#s |
| 4% | GC占总时间的占比 | #% |
| 0.002+3.4+0.015 ms clock | 标记前STW时间(一个P) + 并发标记时间(整个程序) + 标记之后STW时间(一个P) | #+...+# ms clock |
| 0.020+1.0/3.1/1.5+0.12 ms |
| #+#/#/#+# ms cpu 注: GC时候的标记分为三种模式:
|
| 8->8->7 MB | 第一个8表示标记开始前占用堆的大小;第二8代表标记结束后占用的堆的大小;第三个是未被标记对象占用堆的大小 | #->#-># MB |
| 8 P | 共有多少个P | # P |
更多的GODEBUG请参考:
https://golang.org/pkg/runtime/#hdr-Environment_Variables
参考:
https://making.pusher.com/go-tool-trace/
https://golang.org/cmd/trace/
https://docs.google.com/document/d/1FP5apqzBgr7ahCCgFO-yoVhk4YZrNIDNf9RybngBc14/edit
https://making.pusher.com/golangs-real-time-gc-in-theory-and-practice/
https://about.sourcegraph.com/go/an-introduction-to-go-tool-trace-rhys-hiltner/
https://golang.org/pkg/internal/trace/
https://about.sourcegraph.com/go/gophercon-2018-allocator-wrestling/
欢迎长按下面的二维码关注云影原生生公众号
