在日常开发中,基准测试是必不可少的,基准测试主要是通过测试CPU和内存的效率问题,来评估被测试代码的性能,进而找到更好的解决方案。
而Go语言中自带的benchmark则是一件非常神奇的测试利器。有了它,开发者可以方便快捷地在测试一个函数方法在串行或并行环境下的基准表现。指定一个时间(默认是1秒),看测试对象在达到或超过时间上限时,最多能被执行多少次和在此期间测试对象内存分配情况。
1 benchmark的常见用法1.1 如何写一个benchmark的基准测试
import ( "fmt" "testing" ) func BenchmarkSprint(b *testing.B) { b.ResetTimer() for i := 0; i < b.N; i++ { fmt.Sprint(i) } } 复制代码对以上代码做如下说明:
基准测试代码文件必须是_test.go结尾,和单元测试一样;
基准测试的函数以Benchmark开头;
参数须为 *testing.B;
基准测试函数不能有返回值;
b.ResetTimer是重置计时器,这样可以避免for循环之前的初始化代码的干扰;
b.N是基准测试框架提供的,Go会根据系统情况生成,不用用户设定,表示循环的次数,因为需要反复调用测试的代码,才可以评估性能;
运行:go test -bench=. -run=none 命令得到以下结果
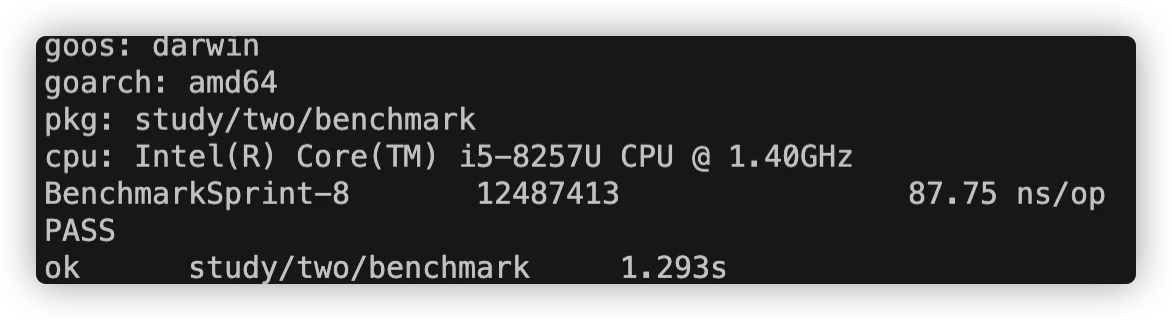
运行benchmark基准测试也要用到 go test 命令,不过我们后面需要加上-bench=参数,接受一个表达式作为参数,匹配基准测试的函数,"."一个点表示运行所有的基准测试。
因为默认情况下 go test 会运行单元测试,为了防止单元测试的输出影响我们查看基准测试的结果,可以使用-run=匹配一个从来没有的单元测试方法,过滤掉单元测试的输出,我们这里使用none,因为我们基本上不会创建这个名字的单元测试方法。
接下来再解释下输出的结果:
函数名后面的-8,表示运行时对应的 GOMAXPROCS 的值;
接着的 1230048 表示运行 for 循环的次数,也就是调用被测试代码的次数,也就是在b.N的范围内执行的次数;
最后的 112.9 ns/op表示每次需要花费 112.9 纳秒;
以上是测试时间默认是1秒,也就是1秒的时间,调用 1230048 次,每次调用花费 112.9 纳秒。如果想让测试运行的时间更长,可以通过 -benchtime= 指定,比如-benchtime=3s,表示执行3秒。
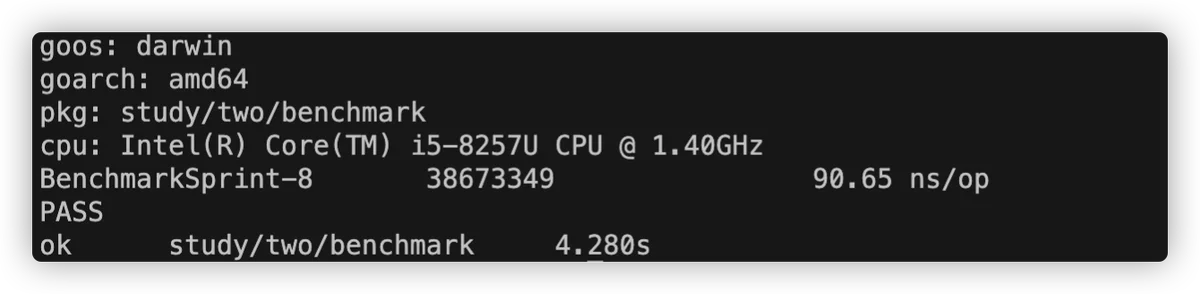
但是我们经过测试发现,测试1s和3s好像没啥明显区别,实际上最终性能并没有多大变化。一般来说不需要太长,常用1s、3s、5s即可,也可忙根据业务场景来判断。
1.2 并行用法
func BenchmarkSprints(b *testing.B) { b.RunParallel(func(pb *testing.PB) { for pb.Next() { // do something fmt.Sprint("代码轶事") } }) } 复制代码b.SetParallelism(p int)numProcs := b.parallelism * runtime.GOMAXPROCS(0) 复制代码
所以并行的用法比较适合IO密集型的测试对象。
1.3 性能对比
上面是简单写的几个示例,下面使用我前面的文章Go语言几种字符串的拼接方式比较里面关于字符串拼接的例子进行示例:
// 文中全局有一个StrData变量,是一个200长度的字符串slice // 直接使用“+”号拼接 func BenchmarkStringsAdd(b *testing.B) { b.ResetTimer() for i := 0; i < b.N; i++ { var s string for _, v := range StrData { s += v } } b.StopTimer() } // fmt.Sprint拼接 func BenchmarkStringsFmt(b *testing.B) { b.ResetTimer() for i := 0; i < b.N; i++ { var _ string = fmt.Sprint(StrData) } b.StopTimer() } // strings.Join拼接 func BenchmarkStringsJoin(b *testing.B) { b.ResetTimer() for i := 0; i < b.N; i++ { _ = strings.Join(StrData, "") } b.StopTimer() } // StringsBuffer拼接 func BenchmarkStringsBuffer(b *testing.B) { b.ResetTimer() for i := 0; i < b.N; i++ { n := len("") * (len(StrData) - 1) for i := 0; i < len(StrData); i++ { n += len(StrData[i]) } var s bytes.Buffer s.Grow(n) for _, v := range StrData { s.WriteString(v) } _ = s.String() } b.StopTimer() } // 使用strings包里的builder类型拼接 func BenchmarkStringsBuilder(b *testing.B) { b.ResetTimer() for i := 0; i < b.N; i++ { n := len("") * (len(StrData) - 1) for i := 0; i < len(StrData); i++ { n += len(StrData[i]) } var b strings.Builder b.Grow(n) b.WriteString(StrData[0]) for _, s := range StrData[1:] { b.WriteString("") b.WriteString(s) } _ = b.String() } b.StopTimer() } 复制代码这次我们添加-benchmem参数,go test -bench=. -benchmem -run=none,来查看每次操作分配内存的次数,运行后的结果如下:

从测试结果来看,strings包的Builder类型的效率是最高的,单次耗时最低,内存分配的次数最少,每次分配的内存最低。这样我们就能从测试结果看出来是那部分代码最慢、内存分配占用太高,进而想办法对相应的代码进行优化处理。
在代码开发中,我们很多时候是不需要太在乎性能的,但绝大部分时候是需要要求性能很高的,因此编写基准测试就变得非常重要。这能帮助我们开发出高性能、高效率的代码。
1.4 结合pprof和火焰图查看代码性能
我们还是以1.3节的例子,以及Go语言几种字符串的拼接方式比较里的例子来说明一下benchmark结合pprof和火焰图查看代码性能的问题。
需要先采集数据,生成文件,然后用pprof打开文件并已http的方式查看,可以分别采集内存维度和CPU维度的数据,具体命令如下:
# 使用benchmark采集3秒的内存维度的数据,并生成文件 go test -bench=. -benchmem -benchtime=3s -memprofile=mem_profile.out # 采集CPU维度的数据 go test -bench=. -benchmem -benchtime=3s -cpuprofile=cpu_profile.out # 查看pprof文件,指定http方式查看 go tool pprof -http="127.0.0.1:8080" mem_profile.out go tool pprof -http="127.0.0.1:8080" cpu_profile.out # 查看pprof文件,直接在命令行查看 go tool pprof mem_profile.out 复制代码
我们执行go tool pprof -http="127.0.0.1:8080" cpu_profile.out命令后,会自动使用我们电脑的默认浏览器打开:http://127.0.0.1:8080/ui/地址,会显示默认的Graph选项卡,显示各方法间的调用关系:
图片不清楚,主要表达意思,具体内容可根据自己的测试情况进行查看分析。
然后我们选择左上角的菜单 VIEW->Flame Graph即可显示火焰图:
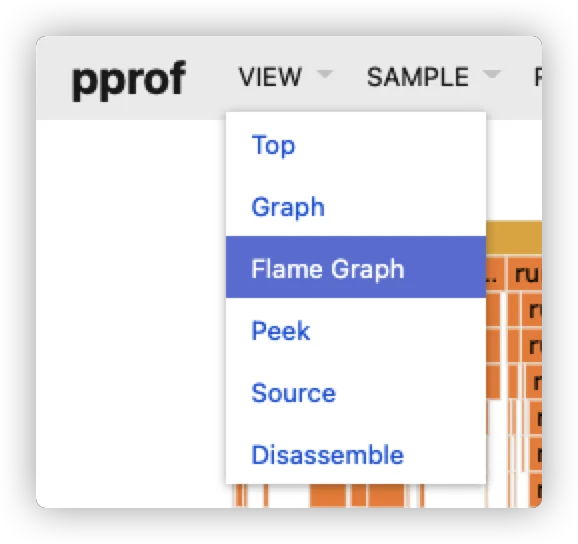

这里如果有的小伙伴没有提前安装好gvedit,可能会报错提示需要安装graphviz。Mac或Linux用户可直接使用brew进行安装:
# Mac 安装 brew install graphviz # Ubuntu apt-get 安装 sudo apt-get install graphviz # yum 安装 sudo yum install graphviz 复制代码
Windows用户去官网下载www.graphviz.org/download/
我们也可以直接在命令行使用go tool pprof cpu_profile.out命令进行查看,
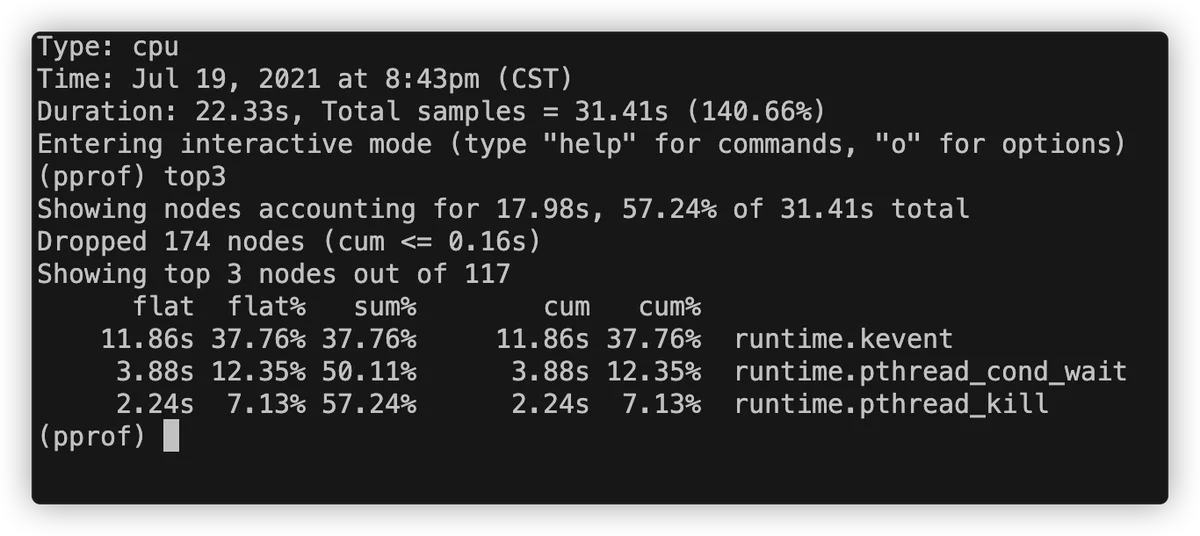
比如上图就是用命令行打开,然后输入top3命令来返回消耗资源最多的3个函数,然后你也可以输入help命令来查看支持的功能。
还有其它各种维度的指标和命令就不在此处多说了,后面也会出pprof的文章。
2 深入研究benchmark上面介绍了使用benchmark进行一个基准测试的一些基础用法, 当然了,如果你比较卷,还是可以继续往下看,我们来介绍一些进阶的用法。
下面的内容,将会对一些不常用但是很深入的内容做一些说明,有很多方法我也几乎用不到,如有不对的地方还请留言指正,感谢!
2.1 Start/Stop/ResetTimer()
这三个方法都是针对计时统计器和内存统计器操作的。
因为有些情况我们在做benchmark测试的时候,是不想将一些不关心的工作耗时计算进benchmark结果中的。
比如我在1.3节中做出的示例,其实我在最开始的init()函数里设置了一个较大的slice:StrData。以便在全局使用同一个slice进行测试,但是我在设置这个较大的slice的时候也会内存的消耗和工作耗时,但是我并不关心它的资源消耗,因此我也不希望会对benchmark的测试结果产生影响,所以在每个被测单元里都执行了b.ResetTimer()。
而且需要注意的是,在并行的情况下,**b.ResetTimer()需要在b.RunParallel()**之前调用,如:
func BenchmarkSprints(b *testing.B) { b.ResetTimer() b.RunParallel(func(pb *testing.PB) { for pb.Next() { // do something fmt.Sprint("代码轶事") } }) } 复制代码**StopTimer()和StartTimer()**的用法如下:
init(); b.ResetTimer() for i := 0; i < b.N; i++ { flag := func1() if flag { // 需要计时 b.StartTimer() }else { // 不需要计时 b.StopTimer() } } 复制代码总结来说
StartTimer:开始计时测试,该函数会被自动调用,也可用于在调用了StopTimer后恢复计时;
StopTimer:停止对测试计时,也可用于在执行复杂的初始化时暂停计时;
ResetTimer:将已用的基准时间和内存分配计数器置零,并删除相关指标,但不影响计时器是否在运行;
2.2 benchmark的输出项目含义解释
我们先尝试执行go test -bench=. -benchmem得到下图的输出结果:

接下来分别介绍每一项的含义;
第一项是现实的被测试的方法名,后面跟的“-8”表示P的个数,通过在命令后面追加参数“-cpu 4,8” 来指定;
第二项是指在b.N周期内迭代的总次数,即b.N的执行上限,通常程序执行效率越高,耗时越低,内存分配和消耗越小,迭代次数就越大;
b.N每次迭代耗时,单位是ns,即每次迭代消耗多少ns,是一个被平均后的均值;
b.N每次迭代的内存分配,即在每次迭代中分配了多少字节的内存;
b.N每次迭代所触发的内存分配次数,触发的内存分配次数越大,耗时多大,效率也就越低;
2.3 进阶参数
2.3.1 -benchtime t
我们在测试某个函数性能的时候,并不是每次执行都会得到一模一样的效果,我连续执行10次,可能会有10次不一样的结果,这时候我们可能会选择添加一个指定的采样时间,来得出一个平均值,在上文中我们讨论benchmark结合pprof使用的时候就用到了这个参数,但也不是盲目的无限增加采样时间就是好的,通常采用3秒5秒即可。
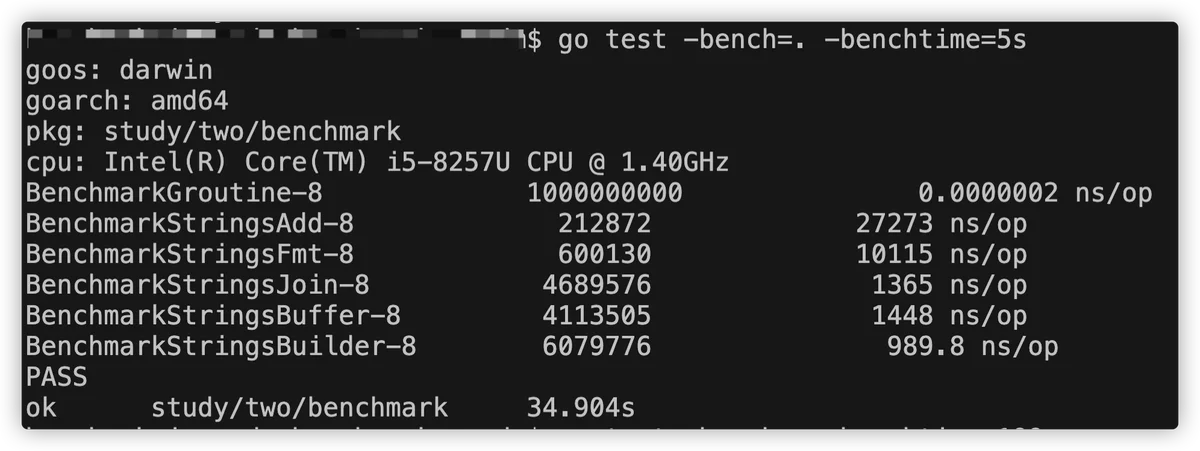
该参数还可支持特殊形式Nx,用来指定被测函数的迭代次数,如:
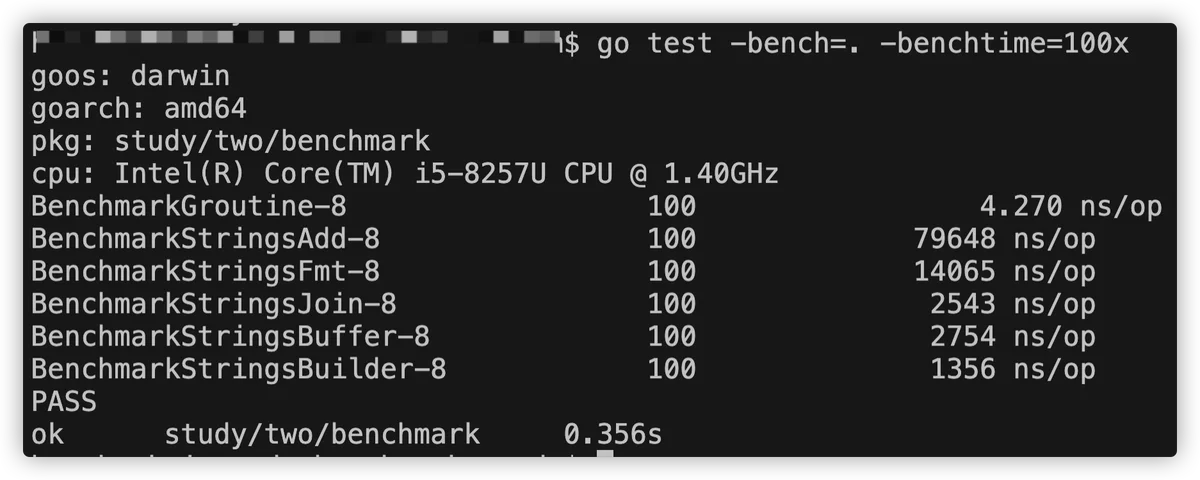
从上图可以看出,指定了迭代100次,则每个函数都会只迭代100次。
2.3.2 -count n
为了我们测试的准确性,可以添加**-count**来指定测试:
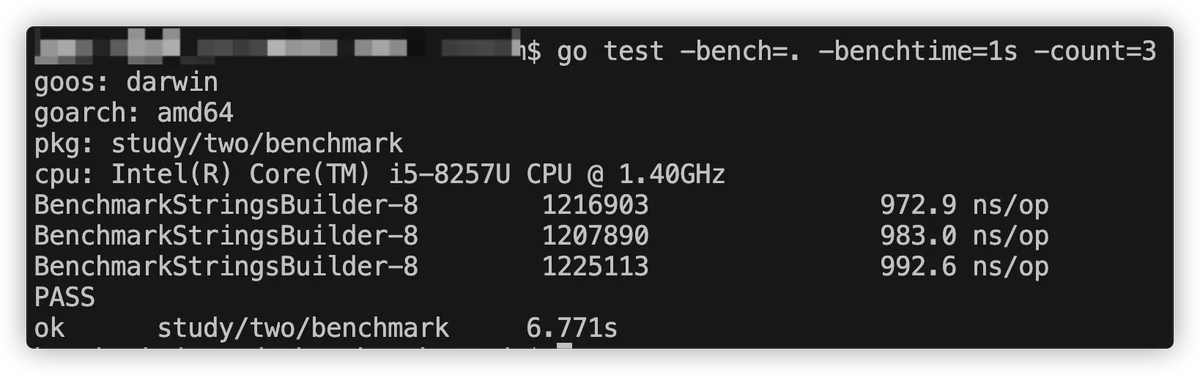
2.3.3 -cpu n
还可以指定cpu的核数,比如我下面的这个例子,使用递归实现一个计算斐波那契数列的方法,然后每次迭代都开启10个goroutine,并且要等这10个goroutine都执行结束后才会进行下一次迭代,代码如下:
func BenchmarkFibonacci(b *testing.B) { b.ResetTimer() for i := 0; i < b.N; i++ { wg := sync.WaitGroup{} wg.Add(10) for i := 0; i < 10; i++ { go func(wg1 *sync.WaitGroup) { defer wg1.Done() arr := [20]int{} for i := 0; i < 20; i++ { arr[i] = fibonacci(i) } }(&wg) } } } func fibonacci(n int) (res int) { if n <= 1 { res = 1 } else { res = fibonacci(n-1) + fibonacci(n-2) } return } 复制代码然后分别指定-cpu=1,2,4,6,8,10来查看测试结果:
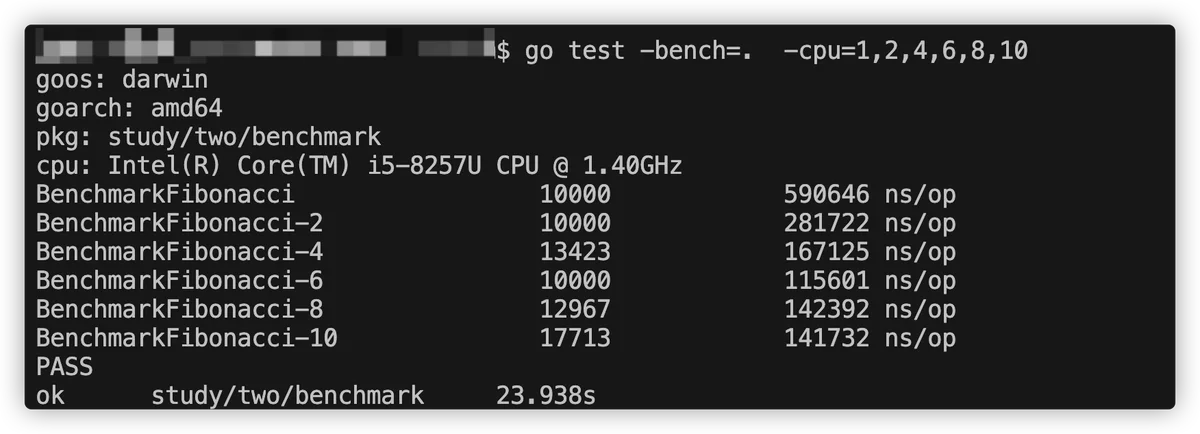
从运行结果来看,CPU核心数提高对性能有一定影响,但也无法一直实现正相关,而且超过一定阈值后反而性能下降了,因为CPU核心的切换也需要成本。因此也不能盲目提高CPU核心数。
2.3.4 -benchmark
除了速度,内存分配也是一个很重要的指标,我在Go语言几种字符串的拼接方式比较一文中做个比较,在使用strings包的builder类型去做字符串拼接的时候,是否合理的预分配内存,测试的结果是不同的,如果我们能合理的预分配内存,那么性能也会有较大的提升。下面我再贴出一个例子来看实际的效果:
// 根据slice的长度,对strings.Builder进行预分配内存 func BenchmarkStringsBuilder1(b *testing.B) { b.ResetTimer() for i := 0; i < b.N; i++ { n := len("") * (len(StrData) - 1) for i := 0; i < len(StrData); i++ { n += len(StrData[i]) } var b strings.Builder b.Grow(n) b.WriteString(StrData[0]) for _, s := range StrData[1:] { b.WriteString("") b.WriteString(s) } _ = b.String() } b.StopTimer() } // 不进行预分配内存 func BenchmarkStringsBuilder2(b *testing.B) { b.ResetTimer() for i := 0; i < b.N; i++ { var b strings.Builder b.WriteString(StrData[0]) for _, s := range StrData[1:] { b.WriteString("") b.WriteString(s) } _ = b.String() } b.StopTimer() } 复制代码然后使用benchmark测试,查看结果:

BenchmarkStringsBuilder1是进行了合理的预分配内存,BenchmarkStringsBuilder2没有进行预分配内存,从测试的结果可以看出,BenchmarkStringsBuilder1的执行效率比BenchmarkStringsBuilder2的执行效率高了特别多。
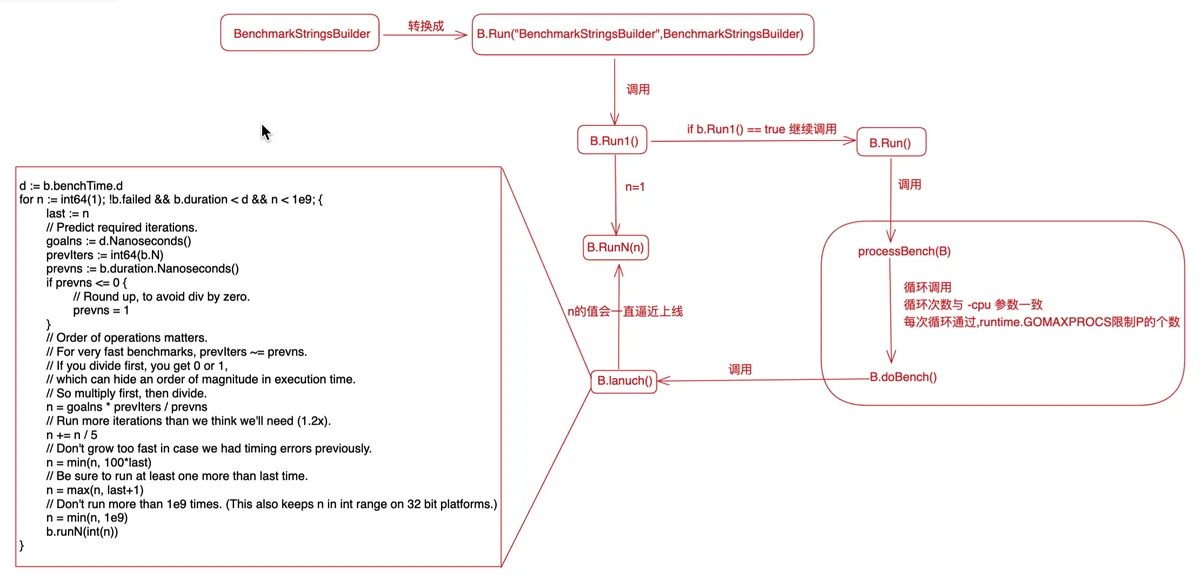
3 benchmark原理要讨论benchmark基准测试的原理,就要讨论testing.B的数据结构,还要分析b.N的值,虽然官方资料中说b.N的值会自动调整,以保证可靠的计时,但仍需分析其实现的机制。
那么我们抛出以下问题:
b.N是如何自动调整的?
内存统计是如何实现的?
SetBytes()其使用场景是什么?
原理部分的讨论参考了【Go专家编程】的一些文章,可以点击关键词去看在线版本。
3.1 testing.B的数据结构
src/testing/benchmark.go:Btype B struct { common // 与testing.T共享的testing.common,负责记录日志、状态等,详情可见src/testing/testing.go文件,在大概385行 importPath string // import path of the package containing the benchmark context *benchContext N int // 目标代码执行次数,会自动调整 previousN int // number of iterations in the previous run previousDuration time.Duration // total duration of the previous run benchFunc func(b *B) // 性能测试函数 benchTime time.Duration // 性能测试函数最少执行的时间,默认为1s,可以通过参数'-benchtime 10s'指定 bytes int64 // 每次迭代处理的字节数 missingBytes bool // one of the subbenchmarks does not have bytes set. timerOn bool // 是否已开始计时 showAllocResult bool result BenchmarkResult // 测试结果 parallelism int // RunParallel creates parallelism*GOMAXPROCS goroutines // The initial states of memStats.Mallocs and memStats.TotalAlloc. startAllocs uint64 // 计时开始时堆中分配的对象总数 startBytes uint64 // 计时开始时时堆中分配的字节总数 // The net total of this test after being run. netAllocs uint64 // 计时结束时,堆中增加的对象总数 netBytes uint64 // 计时结束时,堆中增加的字节总数 extra map[string]float64 // 额外收集的指标 } 复制代码其主要成员如下:
common: 与testing.T共享的testing.common,管理着日志、状态等;
N:每个测试中用户代码执行次数
benchFunc:测试函数
benchTime:性能测试最少执行时间,默认为1s,可以通过能数-benchtime 2s指定
bytes:每次迭代处理的字节数
timerOn:计时启动标志,默认为false,启动计时为true
startAllocs:测试启动时记录堆中分配的对象数
startBytes:测试启动时记录堆中分配的字节数
netAllocs:测试结束后记录堆中新增加的对象数,公式:结束时堆中分配的对象数-
netBytes:测试对事后记录堆中新增加的字节数
流程示意图如下