
Donald E.Knuth说过一句非常著名的话,过早的优化是万恶之源。原文如下:
We should forget about small efficiencies, say about 97% of the time; premature optimization is the root of all evil.
我是十分赞同这句话的,并且在开发过程中也深有体会。什么叫做过早的优化呢?即不需要考虑优化的时候你在考虑优化。这绝对不意味着可以任性地写代码,随意地选择数据结构和算法。这句话是告诉我们,在程序开发的早期阶段,程序员应该专注在程序的逻辑实现上,而不是专注在程序的性能优化上。用正确的数据结构和算法,优美合理的语句实现你要的功能。而不是满脑子在想:“这个函数是不是可以优化一下?”。
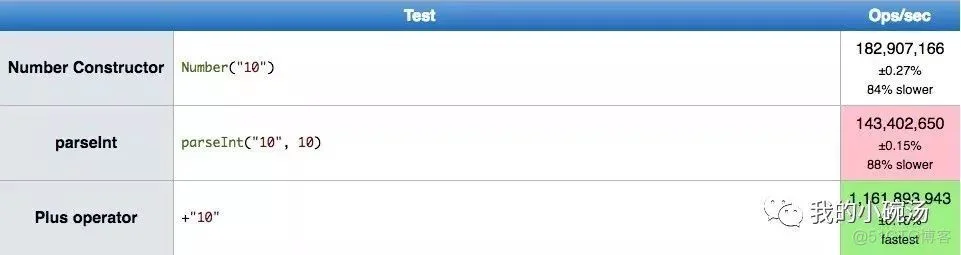
我们都知道,性能最好的代码往往并不是优美直观的代码,往往看起来非常晦涩。下图是 JS 转换字符串到数字的三个方法在 Chrome 下的性能对比。可以看出, + 是最快的方法。但是 +str 这种写法明显是不如 parseInt(str) 或者是 Number(str) 容易理解。Donald E.Knuth 的那句话,我的理解就是在提醒我们,不用使用+str,而应该使用更加语义化的 parseInt(str)。
不应该过早的优化,那么应该做的就是在适当的时候进行优化。程序在功能开发完毕并且测试好以后,就可以进入优化环节了。所有的优化都应该基于性能分析(Profiling),凭空想象进行优化是一件很危险并且没有效率的事情。很多你觉得可以优化的点说不定编译器早替你做了,很多你觉得很慢的地方说不定非常快。
Golang提供了非常棒的Profiling工具,可以很容易地得到CPU和内存的Profiling数据。更加赞的是,Golang还提供了工具来可视化这些数据,一眼就可以看出程序的性能瓶颈在哪儿。调优从未如此轻松。
go中有pprof包来做代码的性能监控,分别有包:
net/http/pprof
runtime/pprof
其实net/http/pprof中只是使用runtime/pprof包来进行封装了一下,并在http端口上暴露出来。
Package runtime/pprof
如果你的go程序只是一个应用程序,比如计算 fabonacci 数列,我们就需要使用到runtime/pprof,具体做法就是用到 pprof.StartCPUProfile 和pprof.StopCPUProfile。比如下面的例子:
func main() {
//create prof file
f, err := os.Create("cpu-profile.prof")
if err != nil {
log.Fatal(err)
}
pprof.StartCPUProfile(f)
//... this is program you want to profile
pprof.StopCPUProfile()
}
程序运行后,pprof会将Profiling数据写到指定的文件当中,然后通过 go tool pprof 就可以查看。
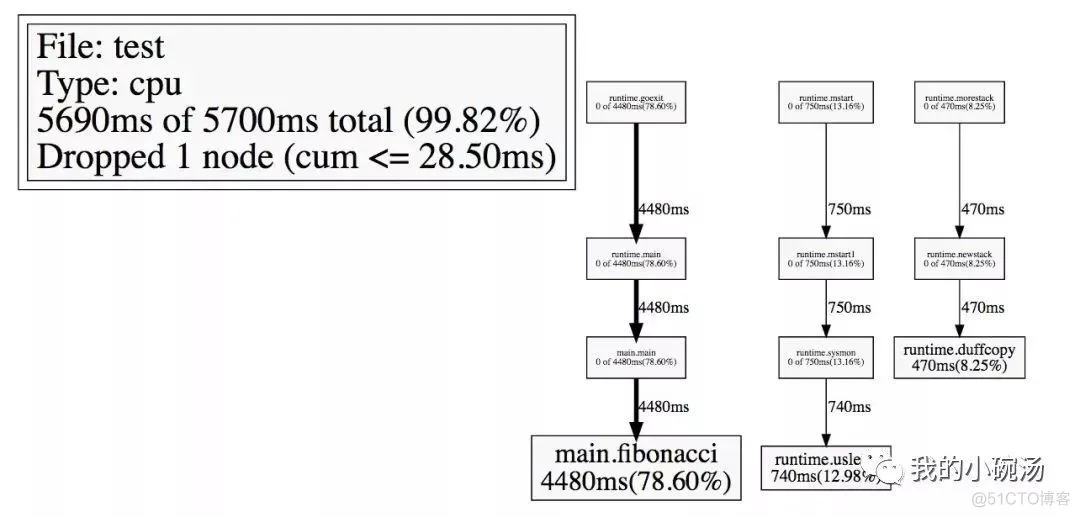
我们来Profiling一个简单的Fibonacci程序。
package main
import (
"fmt"
"log"
"os"
"runtime/pprof"
)
func main() {
f, err := os.Create("cpu-profile.prof")
if err != nil {
log.Fatal(err)
}
pprof.StartCPUProfile(f)
fmt.Println(fibonacci(45))
pprof.StopCPUProfile()
}
func fibonacci(n int) int {
if n < 2 {
return n
}
return fibonacci(n-1) + fibonacci(n-2)
}
编译以后,运行程序便可以生成cpu-profile.prof文件。使用
go tool pprof finabocci cpu-profile.prof
进入Profiling控制台,输入web(需要安装graphviz)
Graphviz 下载地址:
http://down2.opdown.com:8181/opdown/graphviz.zip
Package net/http/pprof
如果你的go程序是用http包启动的web服务器,你想查看自己的web服务器的状态。这个时候就可以选择net/http/pprof。你只需要引入包_"net/http/pprof",然后就可以在浏览器中使用http://localhost:port/debug/pprof/直接看到当前web服务的状态,包括CPU占用情况和内存使用情况等。具体使用情况你可以看godoc的说明。
如果你的go程序不是web服务器,而是一个服务进程,那么你也可以选择使用net/http/pprof包,同样引入包net/http/pprof,然后在开启另外一个goroutine来开启端口监听。
比如:
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
运行程序后,我们可以通过下面的命令采集30s的数据并生成SVG调用图:
go tool pprof -web http://10.75.25.126:9091/debug/pprof/profile
Benchmark Test
每一次都手动引入pprof包比较麻烦,也没有必要。一般Golang的性能测试我们会使用Golang提供的Benchmark功能,Golang提供了命令行参数我们可以直接得到测试文件中Benchmark的Profiling数据。不需要添加任何代码。
下面我们来写一个Benchmark测试一下Golang的标准库函数rand.Intn 的性能如何。
package main
import (
"math/rand"
"testing"
)
func BenchmarkRandom(b *testing.B) {
for i := 0; i < b.N; i++ {
random()
}
}
func random() int {
return rand.Intn(100)
}
因为pprof需要编译好的二进制文件以及prof文件一起才可以分析。所以先要编译这一段测试程序。
$ go test -c go_test.go
$ ./main.test -test.bench=. -test.cpuprofile=cpu-profile.prof
testing: warning: no tests to run
BenchmarkRandom-8 50000000 30.5 ns/op
可以看出Go标准库的 rand.Intn 性能很好。测试运行完毕以后,我们也得到了相应的CPU Profiling数据。使用go tool pprof打开以后,使用top 5指令得到开销排名前五的函数。五个里面有两个是sync/atomic包的函数,保证了原子操作。很明显,rant.Intn 是并发安全的。
$ go tool pprof main.test cpu-profile.prof
(pprof) top 5
780ms of 1370ms total (56.93%)
Showing top 5 nodes out of 35 (cum >= 610ms)
flat flat% sum% cum cum%
270ms 19.71% 19.71% 270ms 19.71% runtime.usleep
170ms 12.41% 32.12% 840ms 61.31% math/rand.(*Rand).Int31n
150ms 10.95% 43.07% 150ms 10.95% sync/atomic.AddUint32
110ms 8.03% 51.09% 110ms 8.03% sync/atomic.CompareAndSwapUint32
80ms 5.84% 56.93% 610ms 44.53% math/rand.(*Rand).Int63
Example Sudoku
下面我用Godoku这个项目为例,看看怎么具体优化一个程序。Godoku是一个Go编写的暴力破解数独的程序,逻辑比较简单,从上到下从左到右扫描每一个空格,从1到9开始填写数字,一旦数字无效(行冲突,列冲突或者9宫格冲突),那么就换一个数字,如果所有数字都换了还无效,那么就退回上一个格子。继续这个过程。
Step1
程序自带了测试和Benchmark,所以我们先来生成一个Profiling文件,看看哪个地方开销最大。
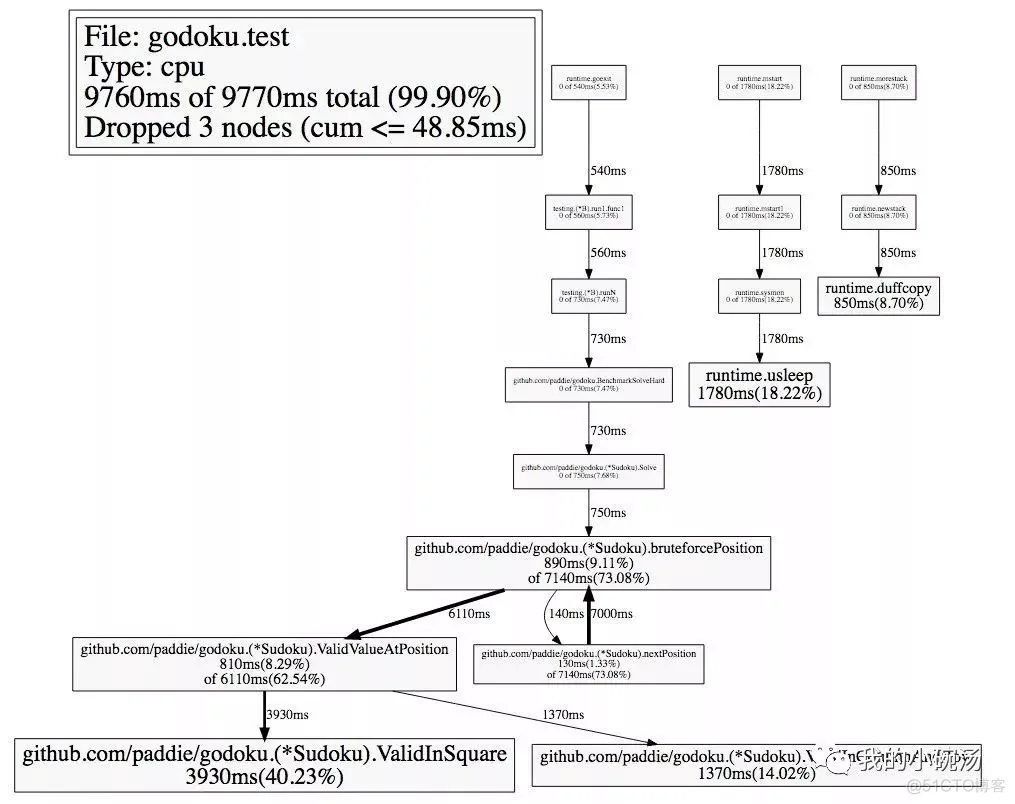
很明显,ValidInSquare 这个函数开销很大。这个函数是检测一个数字在九宫格里面存不存在。作者的实现如下。
func (s *Sudoku) ValidInSquare(row, col, val int) bool {
row, col = int(row/3)*3, int(col/3)*3
for i := row; i < row+3; i++ {
for j := col; j < col+3; j++ {
//fmt.Printf("row, col = %v, %v
", i, j)
if s.board[i][j] == val {
return false
}
}
}
return true
}
循环判断有没有这个数。逻辑很简单,但是Profiling告诉我们,这里成了性能瓶颈。每一次测试数字都要调用这个方法,而这个方法内部是一个循环,调用如此频繁的方法采用循环肯定是不行的。
Step2
这里我们采用经典的空间换时间思路,使用另外一个结构存储九宫格内的状态信息,使得查询一个数字在九宫格内有没有可以通过简单的数组访问得到。
s.regionInfo = make([]int, s.dim * s.dim / 9)
func (s *Sudoku) updateRegion(row, col, val, delta int) {
region := (row/3)*3 + col/3
key := region*9 + val - 1
s.regionInfo[key] += delta
}
func (s *Sudoku) checkRegion(row, col, val int) bool {
region := (row/3)*3 + col/3
key := region*9 + val - 1
return s.regionInfo[key] == 1
}
我们使用一个额外的 regionInfoslice 来存储九宫格里的情况,每一次设置数独中格子的值时,我们更新一下regionInfo的信息。当要检查某个数在某个九宫格中是否已经存在时,直接查询regionInfo即可。
func (s *Sudoku) ValidInSquare(row, col, val int) bool {
return !s.checkRegion(row, col, val)
}
再运行一次测试,看看性能改善了多少。
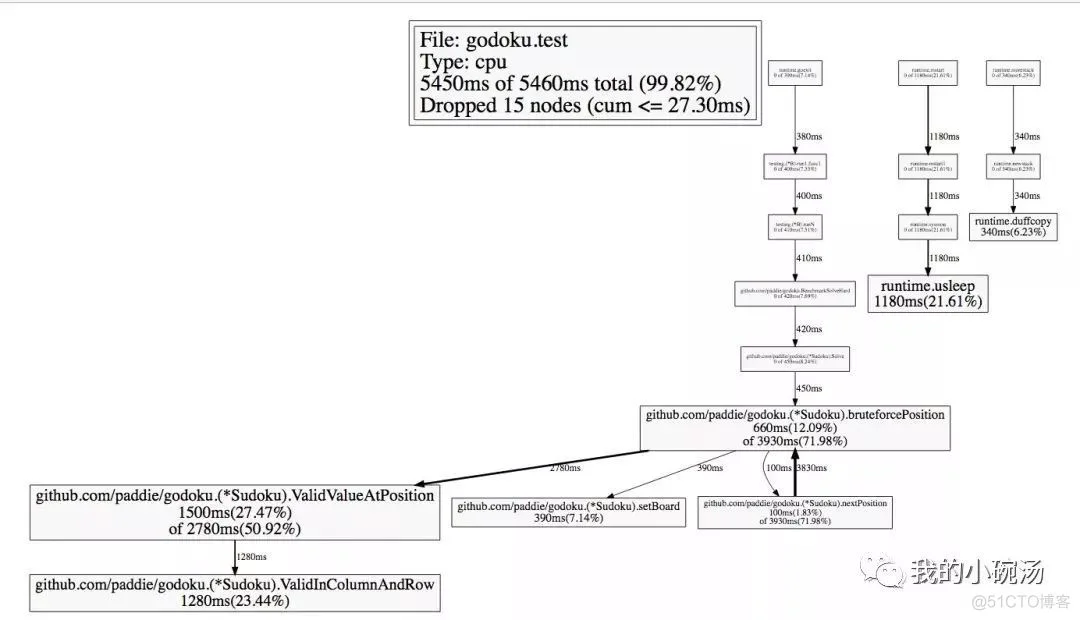
很好!CPU开销已经由9770ms降低到了5460ms,性能提高79%。现在程序的性能瓶颈已经是ValidInColumnAndRow这个函数了。
Step3
作者 ValidInColumnAndRow 函数的实现仍然是直观简单的循环。
func (s *Sudoku) ValidInColumnAndRow(row, col, val int) bool {
for i := 0; i < 9; i++ {
if s.board[row][i] == val ||
s.board[i][col] == val {
return false
}
}
return true
}
我们使用同样的策略来优化ValidInColumnAndRow这个函数,使用额外的数据结构存储每一行和每一列的数字状态信息。这样查询时可以马上返回,而不需要做任何循环比较。
func (s *Sudoku) updateRowAndCol(row, col, val, delta int) {
rowKey := row*9 + val - 1
colKey := col*9 + val - 1
s.rowInfo[rowKey] += delta
s.colInfo[colKey] += delta
}
func (s *Sudoku) checkRowOrCol(row, col, val int) bool {
rowKey := row*9 + val - 1
colKey := col*9 + val - 1
return s.rowInfo[rowKey] == 1 || s.colInfo[colKey] == 1
}
func (s *Sudoku) ValidInColumnAndRow(row, col, val int) bool {
return !s.checkRowOrCol(row, col, val)
}
我们再来看看Profiling数据。

性能再次得到了提升,由5460ms降低到了3610ms。初步看来,已经没有了明显可以优化的地方了。到此为止,我们的程序性能已经得到了170%的提升!我们并没有怎么努力,只不过是生成了Profiling文件,一眼看出问题在哪儿,然后针对性的优化而已。
感谢Golang提供了这套超赞的pprof工具,性能调优变得如此轻松和愉悦。这里我所举的只是pprof功能的冰山一角,pprof的强大功能远不止这些。比如可以使用list指令查看函数的源码中每一行代码的开销以及使用weblist指令查看函数汇编以后每一句汇编指令的开销等等。不仅是CPU Profiling,pprof同样支持Memory Profiling,可以帮助你检查程序中内存的分配情况。总之,在pprof的帮助下,程序的开销信息变得一清二楚,优化自然变得轻而易举。
