
golang正则表达式描述了一种字符串匹配的规则,结合编程语言封装的正则表达式函数,可以实现查找、替换、分割出子串。不同编程语言的正则匹配可能在小范围有些写法区别,大体的语法定义规则是一致的。
golangregexp正则表达式的语法
正则表达式的语法逻辑主要包括:
- 非打印字符;
- 特殊字符;
- 重复(菜鸟教程中称为限定符);
- 定位符;
- 选择与分组;
- 非分组构造;
非打印字符
换行符\n回车符\r任何空白字符\s\S任何非空白字符制表符\t特殊字符
特殊字符具有特殊的意义,匹配本身字符需要用转义符号。


重复
重复的逻辑意义是指用正则表达符号来表示某一类具有相同意义的子字符串。
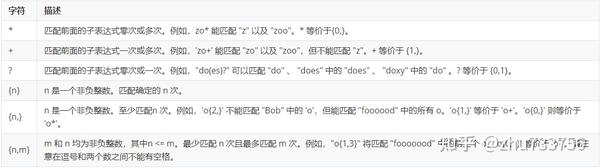

.*.*?.+.+?*+?.定位符


选择与分
选择的逻辑可以理解为从多个元素集合中匹配一个字符。
选择可以分为正向选择和反向选择;
正向选择中:
x|yxy[ABC][]A/B/C[A-Z]AZ[\s\S]\s\S\w而反向选择中:
[^ABC]ABC分组的逻辑有:


非分组构造
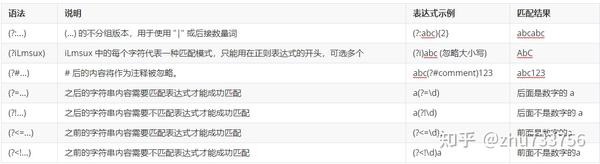
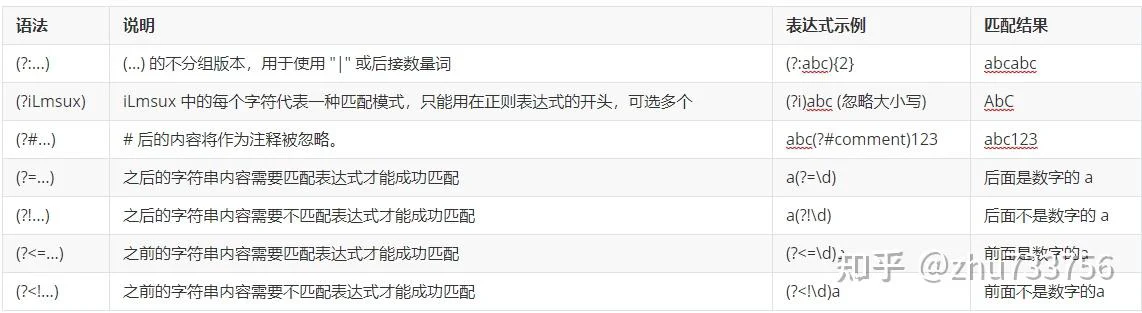
regexp详解
golangregexpcomplieMustCompilefunc Compile(expr string) (*Regexp, error)
func MustCompile(str string) *RegexpcompileMustCompileCompilepanicRegexp查找子字符串
func (re *Regexp) Find(b []byte) []byte
func (re *Regexp) FindAll(b []byte, n int) [][]byte(b []byte, n int) [][]byte
func (re *Regexp) FindString(s string) string
func (re *Regexp) FindAllString(s string, n int) []string # n=-1表示查询所有FindAStringFindAllStringpackage main
import(
"fmt"
"regexp"
)
func main() {
re := regexp.MustCompile("n.")
fmt.Println(re.FindString("none", -1)) // ["no"]
fmt.Println(re.FindAllString("none", -1)) //["no" "ne"]
}查找索引
func (re *Regexp) FindIndex(b []byte) (loc []int)
func (re *Regexp) FindStringIndex(s string) (loc []int)
func (re *Regexp) FindAllIndex(b []byte, n int) [][]int
func (re *Regexp) FindAllStringIndex(s string, n int) [][]int分组匹配
func (re *Regexp) FindSubmatch(b []byte) [][]byte
func (re *Regexp) FindStringSubmatch(s string) []string
func (re *Regexp) FindAllStringSubmatch(s string, n int) [][]string
package main
import(
"fmt"
"regexp"
)
func main() {
re := regexp.MustCompile("a(x*)b(y|z)c")
fmt.Printf("%q\n", re.FindSubmatch([]byte("-axxxbyc-"))) //["axxxbyc" "xxx" "y"]
fmt.Printf("%q\n", re.FindSubmatch([]byte("-abzc-"))) //["abzc" "" "z"]
fmt.Printf("%q\n", re.FindSubmatch([]byte("-aczc-"))) //[],整个都不匹配,更没有分组匹配,将返回空数组
fmt.Printf("%q\n", re.FindStringSubmatch("-axxxbyc-")) //["axxxbyc" "xxx" "y"]
fmt.Printf("%q\n", re.FindStringSubmatch("-abzc-")) //["abzc" "" "z"]
fmt.Printf("%q\n", re.FindStringSubmatch("-aczc-")) //[],整个都不匹配,更没有分组匹配,将返回空数组
fmt.Printf("%q\n", re.FindAllStringSubmatch("-axxxbyc-axxbyc-axbyc-", -1)) //[["axxxbyc" "xxx" "y"] ["axxbyc" "xx" "y"] ["axbyc" "x" "y"]]
fmt.Printf("%q\n", re.FindAllStringSubmatch("-axxxbyc-axxbyc-axbyc-", 2)) //[["axxxbyc" "xxx" "y"] ["axxbyc" "xx" "y"]]
fmt.Printf("%q\n", re.FindAllStringSubmatch("-axxxbyc-axxbyc-axbyc-", 1)) //[["axxxbyc" "xxx" "y"]]
}替换
func (re *Regexp) ReplaceAllLiteralString(src, repl string) string
func (re *Regexp) ReplaceAllString(src, repl string) string
func (re *Regexp) ReplaceAllFunc(src []byte, repl func([]byte) []byte) []byte
package main
import(
"fmt"
"regexp"
)
func main() {
re := regexp.MustCompile("a(x*)b")
fmt.Println(re.ReplaceAllLiteralString("-ab-axxb-", "T")) //-T-T-
fmt.Println(re.ReplaceAllLiteralString("-ab-axxb-", "$1")) // -$1-$1-
fmt.Println(re.ReplaceAllLiteralString("-ab-axxb-", "${1}")) // -${1}-${1}-
//这里$1表示的是每一个匹配的第一个分组匹配结果
//这里第一个匹配的第一个分组匹配为空,即将匹配的ab换为空值;
//第二个匹配的第一个分组匹配为xx,即将匹配的axxb换为xx
fmt.Println(re.ReplaceAllString("-ab-axxb-", "$1")) //--xx-
fmt.Println(re.ReplaceAllString("-ab-axxb-", "${1}w"))//-w-xxw
}分割
func (re *Regexp) Split(s string, n int) []string实战
实战部分,将分享两个例子,来源于实际的需求。
已知,有如下字符串:
messages := "1 alert for alertname=test rule_id=d556b8d429c631f8 \nAlerts Firing:\nLabels:\n- alertname = test\n- alerttype = metric\n- cluster = default\n- host_ip = 192.168.88.6\n- node = node1\n- role = master\n- rule_id = d556b8d429c631f8\n- severity = critical\nAnnotations:\n- kind = Node\n- message = 这是个测试消息\n- resources = [\"node1\"]\n- rule_update_time = 2021-07-27T13:48:32Z\n- rules = [{\"_metricType\":\"node:node_memory_utilisation:{$1}\",\"condition_type\":\">=\",\"thresholds\":\"10\",\"unit\":\"%\"}]\n- summary = 节点 node1 内存利用率 >= 10%\""需要提取指定字段的值。
分组匹配
alertnamealerttypepackage main
import (
"fmt"
"regexp"
)
func main() {
messages := "1 alert for alertname=test rule_id=d556b8d429c631f8 \nAlerts Firing:\nLabels:\n- alertname = test\n- alerttype = metric\n- cluster = default\n- host_ip = 192.168.88.6\n- node = node1\n- role = master\n- rule_id = d556b8d429c631f8\n- severity = critical\nAnnotations:\n- kind = Node\n- message = 这是个测试消息\n- resources = [\"node1\"]\n- rule_update_time = 2021-07-27T13:48:32Z\n- rules = [{\"_metricType\":\"node:node_memory_utilisation:{$1}\",\"condition_type\":\">=\",\"thresholds\":\"10\",\"unit\":\"%\"}]\n- summary = 节点 node1 内存利用率 >= 10%\""
messagePat := `alertname=(?P<alertname>.*?)\s+(?s).*alerttype\s?=\s?(?P<alerttype>[a-zA-Z]+)\s+(?s).*severity\s?=\s?(?P<severity>[a-zA-Z]+)\s+(?s).*message\s?=\s?(?P<message>.*?)\s+(?s).*summary\s?=\s?(?P<summary>.*[^\"])`
re := regexp.MustCompile(messagePat)
matches := re.FindStringSubmatch(messages)
for i, m := range matches {
// 过滤掉第一个元素
if i > 0 {
fmt.Println(m)
}
}
}
---
test
metric
critical
这是个测试消息
节点 node1 内存利用率 >= 10%(?P.*?)(?s).*FindStringSubmatch 分割
keyvalue以下是一个参考:
package main
import (
"fmt"
"regexp"
)
var (
allowKeys = []string{"alertname", "alerttype", "node", "namespace", "pod", "cluster", "deployment", "daemonset", "statefulset", "severity", "messages", "summary"}
)
func main() {
messages := "1 alert for alertname=test rule_id=d556b8d429c631f8 \nAlerts Firing:\nLabels:\n- alertname = test\n- alerttype = metric\n- cluster = default\n- host_ip = 192.168.88.6\n- node = node1\n- role = master\n- rule_id = d556b8d429c631f8\n- severity = critical\nAnnotations:\n- kind = Node\n- message = 这是个测试消息\n- resources = [\"node1\"]\n- rule_update_time = 2021-07-27T13:48:32Z\n- rules = [{\"_metricType\":\"node:node_memory_utilisation:{$1}\",\"condition_type\":\">=\",\"thresholds\":\"10\",\"unit\":\"%\"}]\n- summary = 节点 node1 内存利用率 >= 10%\""
messagePat := `[a-zA-Z0-9_]+\s+=\s+.*?[^\n]+`
re := regexp.MustCompile(messagePat)
matches := re.FindAllString(messages, -1)
sepRe := regexp.MustCompile(`\s+=\s+`)
extractedKeys := make(map[string]string)
for _, m := range matches {
mn := sepRe.Split(m, -1)
if len(mn) > 0 {
extractedKeys[mn[0]] = mn[1]
}
}
for _, key := range allowKeys {
v := ""
if val, ok := extractedKeys[key]; ok {
v = val
}
fmt.Println(key + "= "+ v)
}
}
----
alertname= test
alerttype= metric
node= node1
namespace=
pod=
cluster= default
deployment=
daemonset=
statefulset=
severity= critical
messages=
summary= 节点 node1 内存利用率 >= 10%本章就这么多了,如果对你有所帮助,请帮忙三连吧~