
学习了一段时间golang,又参考课程学习了beego开发网站爬虫,项目的目录结构是:
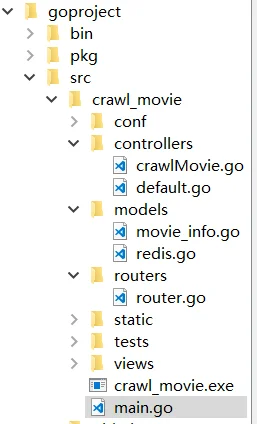
采集的目标是豆瓣网电影,入口地址是:https://movie.douban.com/subject/1900841/?from=subject-page
数据表结构
CREATE TABLE `movie_info` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `movie_id` int(11) unsigned NOT NULL COMMENT '电影id', `movie_name` varchar(100) DEFAULT NULL COMMENT '电影名称', `movie_pic` varchar(200) DEFAULT NULL COMMENT '电影图片', `movie_director` varchar(50) DEFAULT NULL COMMENT '电影导演', `movie_writer` varchar(50) DEFAULT NULL COMMENT '电影编剧', `movie_country` varchar(50) DEFAULT NULL COMMENT '电影产地', `movie_language` varchar(50) DEFAULT NULL COMMENT '电影语言', `movie_main_character` varchar(50) DEFAULT NULL COMMENT '电影主演', `movie_type` varchar(50) DEFAULT NULL COMMENT '电影类型', `movie_on_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '电影上映时间', `movie_span` varchar(20) DEFAULT NULL COMMENT '电影时长', `movie_grade` varchar(5) DEFAULT NULL COMMENT '电影评分', `remark` varchar(500) DEFAULT '' COMMENT '备注', `create_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '创建时间', `modify_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间', `status` tinyint(1) DEFAULT '1', PRIMARY KEY (`id`), KEY `idx_movie_id` (`movie_id`), KEY `idx_create_time` (`create_time`), KEY `idx_modify_time` (`modify_time`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='电影信息表';
路由文件router.go
//router.go文件
package routers
import (
"crawl_movie/controllers"
"github.com/astaxie/beego"
)
func init() {
beego.Router("/", &controllers.MainController{})
beego.Router("/crawl_movie", &controllers.CrawlMovieController{}, "*:CrawlMovie")
}
控制器下文件
//crawlMovie.go 文件
package controllers
import (
"crawl_movie/models"
"fmt"
"runtime"
"time"
"github.com/astaxie/beego"
"github.com/astaxie/beego/httplib"
)
type CrawlMovieController struct {
beego.Controller
}
func PrintErr() {
if err := recover(); err != nil {
fmt.Printf("%v", err)
for i := 0; i < 10; i++ {
funcName, file, line, ok := runtime.Caller(i)
if ok {
fmt.Printf("frame %v:[func:%v,file:%v,line:%v]\n", i, runtime.FuncForPC(funcName).Name(), file, line)
}
}
}
}
func (c *CrawlMovieController) CrawlMovie() {
PrintErr()
var movieInfo models.MovieInfo //先声明电影信息结构
models.ConnectRedis("127.0.0.1:6379") //连接redis
//爬虫入口url
sUrl := "https://movie.douban.com/subject/1900841/?from=subject-page" //这里作为入口
models.PutinQueue(sUrl)
for {
length := models.GetQueueLength()
c.Ctx.WriteString(fmt.Sprintf("---%v---", length))
if length == 0 {
break //如果url队列为空,则退出当前循环
}
sUrl = models.PopfromQueue()
//判断url是否已经被访问过
if models.IsVisit(sUrl) { //访问过则跳过
continue
}
rsp := httplib.Get(sUrl)
//设置User-agent以及cookie是为了防止 豆瓣网的 403
rsp.Header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0")
rsp.Header("Cookie", `bid=gFP9qSgGTfA; __utma=30149280.1124851270.1482153600.1483055851.1483064193.8; __utmz=30149280.1482971588.4.2.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; ll="118221"; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1483064193%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_id.100001.4cf6=5afcf5e5496eab22.1482413017.7.1483066280.1483057909.; __utma=223695111.1636117731.1482413017.1483055857.1483064193.7; __utmz=223695111.1483055857.6.5.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; _vwo_uuid_v2=BDC2DBEDF8958EC838F9D9394CC5D9A0|2cc6ef7952be8c2d5408cb7c8cce2684; ap=1; viewed="1006073"; gr_user_id=e5c932fc-2af6-4861-8a4f-5d696f34570b; __utmc=30149280; __utmc=223695111; _pk_ses.100001.4cf6=*; __utmb=30149280.0.10.1483064193; __utmb=223695111.0.10.1483064193`)
sMovieHtml, err := rsp.String()
if err != nil {
panic(err)
}
//获取电影名称
movieInfo.Movie_name = models.GetMovieName(sMovieHtml)
if movieInfo.Movie_name != "" { //如果为空,则说明不是电影,如果不为空,则是电影
//获取电影导演
movieInfo.Movie_director = models.GetMovieDirector(sMovieHtml)
//获取主演
movieInfo.Movie_main_character = models.GetMovieMainCharacters(sMovieHtml)
//电影类型
movieInfo.Movie_type = models.GetMovieGenre(sMovieHtml)
//上映时间
movieInfo.Movie_on_time = models.GetMovieOnTime(sMovieHtml)
//评分
movieInfo.Movie_grade = models.GetMovieGrade(sMovieHtml)
//时长
movieInfo.Movie_span = models.GetMovieRunningTime(sMovieHtml)
// c.Ctx.WriteString(fmt.Sprintf("%v", movieInfo))
//入库
models.AddMovie(&movieInfo)
// id, _ := models.AddMovie(&movieInfo)
// c.Ctx.WriteString(fmt.Sprintf("%v", id))
}
//提取该页面的所有连接
urls := models.GetMovieUrls(sMovieHtml)
//遍历url
//为了把url写入队列
//同样需要开启一个协程,这个协程专门负责从队列中取,负责get,set,
//第一判断这个url是不是一个电影,是的话加入到数据库,
// 第二是提取这个电影有关的url
//第三把url放入set(集合)里,表明这个url已经访问过
for _, url := range urls {
models.PutinQueue(url)
c.Ctx.WriteString("<br>" + url + "</br>")
}
//sUrl 需要记录到set集合里,表明这个url访问过
models.AddToSet(sUrl)
time.Sleep(time.Second) //适当休息
}
c.Ctx.WriteString("爬虫执行结束")
}
models目录下文件
//movie_info.go 文件
package models
import (
"regexp" //正则包
"strings"
"github.com/astaxie/beego/orm"
_ "github.com/go-sql-driver/mysql"
)
var (
db orm.Ormer
)
type MovieInfo struct {
Id int64
Movie_id int64
Movie_name string
Movie_pic string
Movie_director string
Movie_writer string
Movie_country string
Movie_language string
Movie_main_character string
Movie_type string
Movie_on_time string
Movie_span string
Movie_grade string
Create_time string
}
func init() {
orm.Debug = true //是否开启调试模式,调试模式下会打印sql语句
orm.RegisterDataBase("default", "mysql", "root:root@tcp(127.0.0.1:3306)/beego?charset=utf8")
orm.RegisterModel(new(MovieInfo))
db = orm.NewOrm()
}
//添加电影
func AddMovie(movie_info *MovieInfo) (int64, error) {
id, err := db.Insert(movie_info)
return id, err
}
//获取导演名
func GetMovieDirector(movieHtml string) string {
if movieHtml == "" {
return ""
}
reg := regexp.MustCompile(`<a.*?rel="v:directedBy">(.*)</a>`)
result := reg.FindAllStringSubmatch(movieHtml, -1)
return string(result[0][1])
}
//获取电影名
func GetMovieName(movieHtml string) string {
if movieHtml == "" {
return ""
}
reg := regexp.MustCompile(`<span\s*property="v:itemreviewed">(.*?)</span>`)
result := reg.FindAllStringSubmatch(movieHtml, -1)
if len(result) == 0 {
return ""
}
return string(result[0][1])
}
//获取主演
func GetMovieMainCharacters(movieHtml string) string {
reg := regexp.MustCompile(`<a.*?rel="v:starring">(.*?)</a>`)
result := reg.FindAllStringSubmatch(movieHtml, -1)
mainCharacters := ""
if len(result) == 0 {
return mainCharacters
}
for _, v := range result {
mainCharacters += v[1] + "/"
}
return strings.Trim(mainCharacters, "/")
}
//获取电影主演
func GetMovieGrade(movieHtml string) string {
reg := regexp.MustCompile(`<strong.*?property="v:average">(.*?)</strong>`)
result := reg.FindAllStringSubmatch(movieHtml, -1)
if len(result) == 0 {
return ""
}
return string(result[0][1])
}
//获取电影类型
func GetMovieGenre(movieHtml string) string {
reg := regexp.MustCompile(`<span.*?property="v:genre">(.*?)</span>`)
result := reg.FindAllStringSubmatch(movieHtml, -1)
if len(result) == 0 {
return ""
}
movieGenre := ""
for _, v := range result {
movieGenre += v[1] + "/"
}
return strings.Trim(movieGenre, "/")
}
//获取电影上映时间
func GetMovieOnTime(movieHtml string) string {
reg := regexp.MustCompile(`<span.*?property="v:initialReleaseDate".*?>(.*?)</span>`)
result := reg.FindAllStringSubmatch(movieHtml, -1)
if len(result) == 0 {
return ""
}
return string(result[0][1])
}
//获取电影时长
func GetMovieRunningTime(movieHtml string) string {
reg := regexp.MustCompile(`<span.*?property="v:runtime".*?>(.*?)</span>`)
result := reg.FindAllStringSubmatch(movieHtml, -1)
if len(result) == 0 {
return ""
}
return string(result[0][1])
}
//获取当前电影页下对的所有相关电影url
func GetMovieUrls(movieHtml string) []string {
reg := regexp.MustCompile(`<a.*?href="(https://movie.douban.com/.*?)"`)
result := reg.FindAllStringSubmatch(movieHtml, -1)
var movieSets []string
for _, v := range result {
movieSets = append(movieSets, v[1])
}
return movieSets
}
//redis.go
package models
import (
"github.com/astaxie/goredis"
)
var (
client goredis.Client
)
//定义常量
const (
URL_QUEUE = "url_queue" //作为队列标识
URL_VISIT_SET = "url_visit_set" //记录曾经访问过的url
)
func ConnectRedis(addr string) {
client.Addr = addr
}
//把提取的url放入队列
func PutinQueue(url string) {
client.Lpush(URL_QUEUE, []byte(url))
}
//从队列中取
func PopfromQueue() string {
res, err := client.Rpop(URL_QUEUE)
if err != nil {
panic(err)
}
return string(res)
}
// 把曾经访问过的加入一个集合
func AddToSet(url string) {
client.Sadd(URL_VISIT_SET, []byte(url))
}
//获取队列长度
func GetQueueLength() int {
length, err := client.Llen(URL_QUEUE)
if err != nil {
return 0
}
return length
}
//判断某个URL是否访问过
func IsVisit(url string) bool {
bIsVisit, err := client.Sismember(URL_VISIT_SET, []byte(url))
if err != nil {
return false
}
return bIsVisit
}