
关于protobuf的使用、编码原理、编码原理应用 可以分别参见以下文章。
另外,陈硕大神的 这篇 非常值得参考。
这篇文章主要是介绍下protobuf的反射机制、pb反射机制涉及到的几个类、pb反射实现步骤、反射在pb↔json互转的应用。
首先解决一个问题,反射是什么?可以干什么用?
1、反射是什么。给定一个pb对象,如何自动遍历该对象的所有字段?换句话说 是否有一个通用的方法可以遍历任意pb对象的所有字段,而不用关心具体对象类型。为了加深理解这里引用下陈硕文章的一段话。“这里要解决的问题是:在接收到protobuf数据之后,如何自动创建具体的Protobuf Message对象,再做反序列化。‘自动’的意思是:当程序中新增一个protobuf message类型时,这部分代码不需要修改,不需要自己注册消息类型。”
这里我在明确一下:其实就是如何用type name 自动创建Message对象;然后再对序列化后的二进制流反序列化即可还原出原数据。
举个例子:对于如下pb message类型Person实例,我们能否将对象自动转换为json字符串{"name":"waitingzhuo","age":26}。对于这个问题很多同学会说这不简单,把Person解析出来然后取出各个字段再创建json就好了呀。 注意:这里的“自动”二字。比如说如果我们又在pb中添加了新的字段 person.set_email("izualzhy@163.com") ,你得到json能否自动的新增这个字段?亦或是你需要通过手动修改的pb2json的代码才能实现。
#有如下proto文件
syntax = "proto2";
package tencent;
message Person
{
required string name = 1;
required uint32 age = 2;
optional uint64 email = 3;
}Person person;
person.set_name("yingshin");
person.set_age(21);答案就是protobuf的反射功能。实际上protobuf自身的反序列化过程就是利用反射实现的。
2、使用场景。前面已经说了pb与json格式的相互转换,其实很多pb2json的底层库就是利用protobuf的反射能力来实现的。另外pb到xml的转换、pb直接写数据库(如不同字段写到hbase的不同列)、基于pb的自动化测试工具等都是pb反射机制的应用场景。一句话:反射只是一种机制,有着什么样的应用场景要看你的想象力了。
3、反射实现的关键点。
反射实现的关键点是获取系统的元(meta)信息。
原信息:即系统字描述信息,用于描述系统本身。举例来说,即系统有哪些类?每个类中有哪些字段、哪些方法?字段属于什么类型、方法又又着怎样的参数及返回值?………
对于java而言,其能够提供反射能力的关键是在编译阶段将程序的meta信息编译进了.class文件,在程序运行事JVM将会把.class文件加载到JVM内存模型中的方法区。此后程序运行时将有能力获取关于自身的元信息。除了java外,JS、python、GO、PHP等语言也在语言层面实现了程序的反射。
那么protobuf反射所需的元信息在哪?——其实就在.proto文件中。用户在.proto文件中定义我们所需的数据结构,这个过程同事也是为protobuf提供数据元信息的过程。即 这些元信息包括数据由哪些字段构成,字段又属于什么类型一级字段之间的组合关系等。
反射的两种主要用途:
(1)通过proto对象的名字来创建一个对象(json→pb)
#include <iostream>
#include <string>
#include "person.pb.h"
using namespace std;
/*
Descriptor/FieldDescriptor位于descriptor.h文件;
Message/Reflection 位于message.h文件
以上四个类都位于 namespace google::protobuf下.
*/
using namespace google::protobuf;
typedef tencent::Person T;
Message* createMessage(const std::string& typeName);
int main()
{
//通过Descriptor类的full_name函数获取相应结构的type_name
std::string type_name = T::descriptor()->full_name();
cout << "type_name:" << type_name << endl;
//根据type name创建相应的message对象 new_person
Message* new_person = createMessage(type_name);
assert(new_person != NULL);//指针为null向stderr打印一条信息
assert(typeid(*new_person) == typeid(tencent::Person::default_instance()));
cout << "new_person:" << new_person->DebugString() << endl;
//接下来使用DescriptorPool类的FindMessageTypeByName方法通过type_name查到元信息Descriptor*
const Descriptor* descriptor = google::protobuf::DescriptorPool::generated_pool()->FindMessageTypeByName(type_name);
cout << "FindMessageTypeByName() = " << descriptor << endl;
cout << "T::descriptor() = " << T::descriptor() << endl;
cout << endl;
// 再用MessageFactory::generated_factory() 找到 MessageFactory 对象
const Message* prototype = MessageFactory::generated_factory()->GetPrototype(descriptor);
cout << "GetPrototype() = " << prototype << endl;
cout << "T::default_instance() = " << &T::default_instance() << endl;
cout << endl;
//再然后我们实例化出一个实例
//dynamic_cast:将基类的指针或引用安全第一转换成派生类的指针或引用,并用派生类的指针或引用调用非虚函数。
T* new_obj = dynamic_cast<T*>(prototype->New());
cout << "prototype->New() = " << new_obj << endl;
cout << endl;
/*--------接下来看看反射接口怎么用--------*/
//获取这个message的反射接口指针
const Reflection* reflecter = new_obj->GetReflection();
//通过name查找filed
const FieldDescriptor* field = descriptor->FindFieldByName("name");
//设置这个field的字段值
std::string str1 = "shuozhuo";
reflecter->SetString(new_obj, field, str1);
//取出这个field的值
std::cout << "\"name\" field is:" << reflecter->GetString(*new_obj,field)<< std::endl;
}
/*
本函数的作用就是根据type name 自动创建具体的protobuf message对象;
*/
Message* createMessage(const std::string& typeName)
{
Message* message = NULL;
const Descriptor* descriptor = DescriptorPool::generated_pool()->FindMessageTypeByName(typeName);
if (descriptor)
{
const Message* prototype = MessageFactory::generated_factory()->GetPrototype(descriptor);
if (prototype)
{
message = prototype->New();
}
}
return message;
}
1)获取元信息DescriptorPool。通过DescriptorPool的FindMessageTypeByName获得元信息Descriptor(即Descriptor类)。
其中DescriptorPool为元信息池,对外提供FindMessageTypeByName、FindMessageTypeByName等各类接口以便外部查询所需的原信息。
DescriptorDatabase 可从硬编码或磁盘中查询对应名称的 .proto 文件内容,解析后返回查询需要的元信息。DescriptorPool 相当于缓存了文件的 Descriptor(底层使用 Map),查询时将先到缓存中查询,如果未能找到再进一步到 DB 中(即 DescriptorDatabase)查询,此时可能需要从磁盘中读取文件内容,然后再解析成 Descriptor 返回,这里需要消耗一定的时间。从上面的描述不难看出,DescriptorPool 和 DescriptorDatabase 通过缓存机制提高了反射运行效率,但这只是反射工程实现上的一种优化,我们更感兴趣的应该是 Descriptor 的来源。
DescriptorDatabase 从磁盘中读取 .proto 内容并解析成 Descriptor 这一来源很容易理解,但我们大多数时候并不会采用这种方式,反射时也不会去读取 .proto 文件。那么我们的 .proto 内容在哪?实际上我们在使用 protoc 生成 xxx.pb.cc 和 xxx.pb.h 文件时,其中不仅仅包含了读写数据的接口,还包含了 .proto 文件内容。阅读任意一个 xxx.pb.cc 的内容,你可以看到如下类似一坨东西。
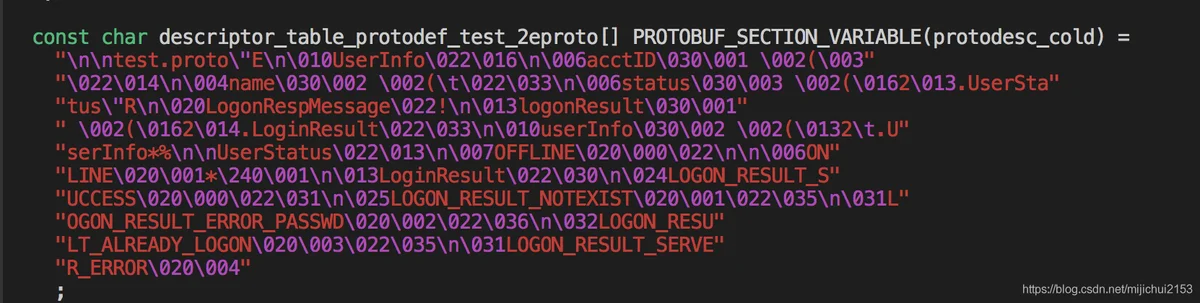
这个数组存的就是.proto内容。当然这里并不是简单的存原始文本字符串,而是经过SerializeToString序列化处理的结果,这个结果以硬编码的方式板寸在xxx.pb.cc中。
硬编码的 .proto 元信息内容将以懒加载的方式(被调用时才触发)被 DescriptorDatabase 加载、解析,并缓存到 DescriptorPool 中。
2)其他语句就不做详解了。
(2)通过Message初始化和获取成员变量的值(pb→json)
看最后的示例即可。
反射相关接口(相关类介绍):
首先看下UML图
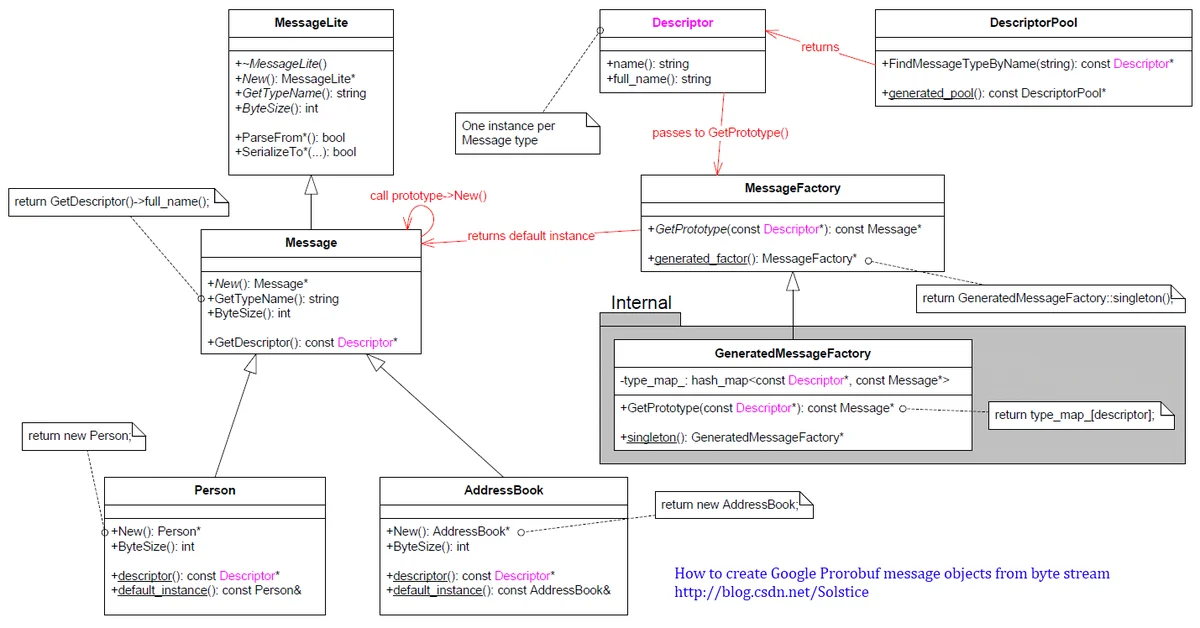
注:下面说的type name 指的是完整的结构名称,例如上面的“tencent.Person”。
1、MessageLite类
所有message的接口类,从名字看就是lite的message,普通的message也是他的子类。
MessageLite是和“轻量级”的message(仅仅提供encoding+序列化,没有reflection和descriptors)。在确定可以使用“轻量级”message的场景下,可以在.proto文件中增加配置(option optimize_for = LITE_RUNTIME;),来让protocol compiler产出MessageLite类型的类,这样可以节省runtime资源。
注:lite 低热量的、淡的、轻量级的。
2、Message类
接口类,在MessageLite类的基础上增加了descriptor和reflection。
3、MessageFactory类
接口类,来找到MessageFactory对象,他能创建程序编译的时候所链接的全部protobuf Message types。其提供的GetPrototype方法可以找到具体的Message Type的default instance。 底层封装了GeneratedMessageFactory类。
4、DescriptorPool类
用 DescriptorPool::generated_pool() 找到一个 DescriptorPool 对象,它包含了程序编译的时候所链接的全部 protobuf Message types。然后通过其提供的 FindMessageTypeByName 方法即可根据type name 查找到Descriptor。
5、GeneratedMessageFactory类
继承自MessageFactory,singleton模式。
6、Descriptor类
描述一种message的meta信息(注意:不是单独的message对象)。构造函数是private类型,必须通过DescriptorPool(friend类)来构造。
const成员如下:
const FileDescriptor* file_: 描述message所在的.proto文件信息
const Descriptor* containing_type_:如果在proto定义中,这个message是被其它message所包含,那么这个字段是上一级message的descriptor*;如果没有被包含,那么是NULL
const MessageOptions* options_: 定义在descriptor.proto,从注释看是用来和老版本proto1中MessageSet做拓展,可以先不去关注涉及extension的部分。非const成员如下:
int field_count_:当前field包含的field的个数
FieldDescriptor* fields_: 以连续数组方式保存的所有的fieds
int nested_type_count_: 嵌套类型数量
Descriptor* nested_types_: message中嵌套message
int enum_type_count_: 内部enum的个数
EnumDescriptor* enum_types_: enum类型的连续内存起始地址7、FileDescriptor类
描述整个.proto文件信息,其中包含:
1、依赖.proto文件信息:
int dependency_count_;
const FileDescriptor** dependencies_;
2、当前.proto文件包含的message信息:
int message_type_count_;
Descriptor* message_types_;
3、当前.proto文件包含的所有symbol(各种discriprot)的tables:
const FileDescriptorTables* tables_;8、FileDescriptor类
描述一个单独的field,构造函数为private,也必须由DescriptorPool(friend类)构造。通过包含这个field的message的descriptor的函数(Descriptor::FindFieldByName())获得。
9、EnumDescriptor类
描述在.proto文件中定义的enum类型。
应用实例:pb↔json相互转换
文件命令为 pb2json.cpp ,代码在个人云服务器 /mystudy/protobuf2json
实例程序可以从 这里 获得!!!!
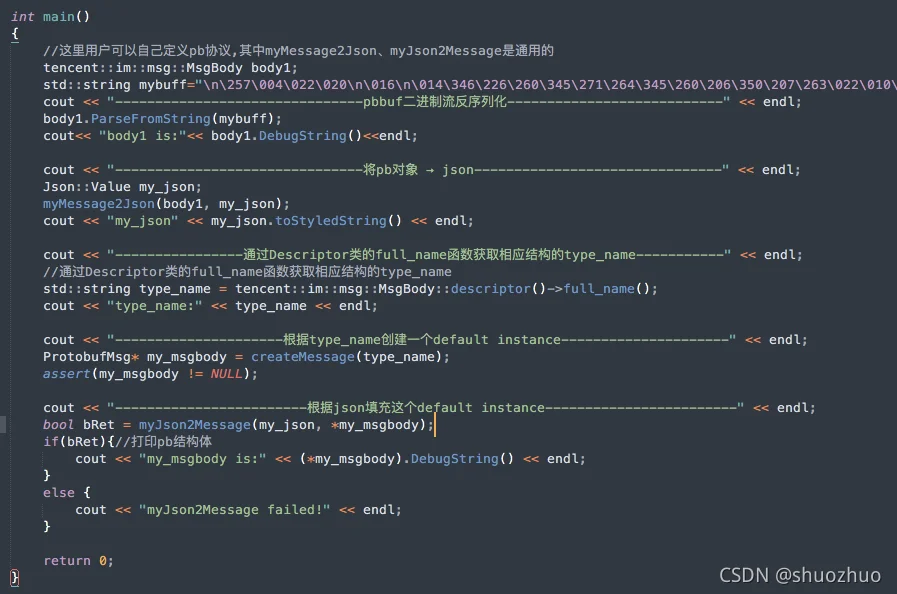
执行效果如下:
[root@VM_50_94_centos /mystudy/protobuf2/pb2json]# ./pb2json
-------------------------------pbbuf二进制流反序列化---------------------------
body1 is:riXXXXXt {
exxxs {
text {
str: "\346\226\260\345\271\264\345\260\206\350\207\263"
}
}
exxxs {
face {
index: 69
old: "\024h"
}
}
exxxs {
text {
str: "\357\274\214\347\272\242\345\214\205\345\257\271\350\201\224\345\244\247\347\244\274\345\214\205\347\201\253\347\203\255\345\256\232\345\210\266\344\270\255"
}
}
exxxs {
face {
index: 144
old: "\024\321"
}
}
exxxs {
text {
str: "\357\274\201\357\274\201\357\274\201"
}
}
elems {
crm_elem {
crm_buf: "\010\010\202\001.\010"
}
}
}
-------------------------------将pb对象 → json-------------------------------
my_json{
"rixxxxxt" : {
"elxxxs" : [
{
"texxt" : {
"str" : "新年将至"
}
},
{
"face" : {
"index" : 69,
"old" : "\u0014h"
}
},
{
"text" : {
"str" : ",红包对联大礼包火热定制中"
}
},
{
"face" : {
"index" : 144,
"old" : "\u0014�"
}
},
{
"text" : {
"str" : "!!!"
}
},
{
"crm_elem" : {
"crm_buf" : "\b\b�\u0001.\b"
}
}
]
}
}
----------------通过Descriptor类的full_name函数获取相应结构的type_name-----------
type_name:tencent.im.msg.MsgBody
---------------------根据type_name创建一个default instance---------------------
------------------------根据json填充这个default instance------------------------
my_msgbody is:rxxxxt {
exxxxs {
text {
str: "\346\226\260\345\271\264\345\260\206\350\207\263"
}
}
exxxxs {
face {
index: 69
old: "\024h"
}
}
exxxxs {
txxxt {
stxxxr: "\357\274\214\347\272\242\345\214\205\345\257\271\350\201\224\345\244\247\347\244\274\345\214\205\347\201\253\347\203\255\345\256\232\345\210\266\344\270\255"
}
}
elems {
face {
index: 144
old: "\024\321"
}
}
exxxs {
text {
str: "\357\274\201\357\274\201\357\274\201"
}
}
exxxxs {
crxxxxm {
cxxxxxuf: "\010\010\202\001.\010"
}
}
}