
schedule 函数中,我们简单提过找一个 runnable goroutine 的过程,这一讲我们来详细分析源码。
工作线程 M 费尽心机也要找到一个可运行的 goroutine,这是它的工作和职责,不达目的,绝不罢体,这种锲而不舍的精神值得每个人学习。
共经历三个过程:先从本地队列找,定期会从全局队列找,最后实在没办法,就去别的 P 偷。如下图所示:
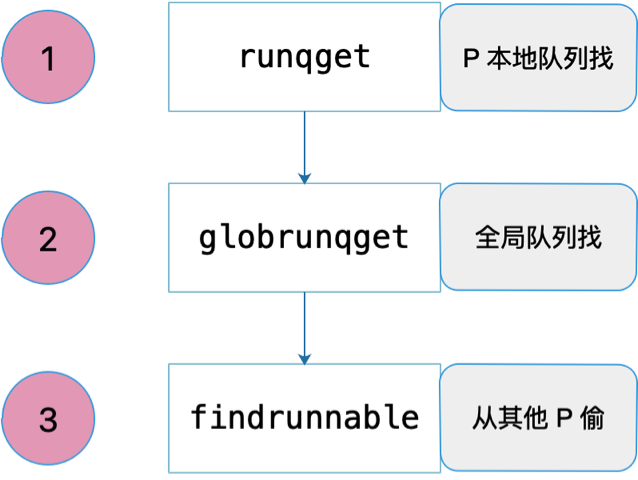
先看第一个:从 P 本地队列找。源码如下:
// 从本地可运行队列里找到一个 g
// 如果 inheritTime 为真,gp 应该继承这个时间片,否则,新开启一个时间片
func runqget(_p_ *p) (gp *g, inheritTime bool) {
// If there's a runnext, it's the next G to run.
// 如果 runnext 不为空,则 runnext 是下一个待运行的 G
for {
next := _p_.runnext
if next == 0 {
// 为空,则直接跳出循环
break
}
// 再次比较 next 是否没有变化
if _p_.runnext.cas(next, 0) {
// 如果没有变化,则返回 next 所指向的 g。且需要继承时间片
return next.ptr(), true
}
}
for {
// 获取队列头
h := atomic.Load(&_p_.runqhead) // load-acquire, synchronize with other consumers
// 获取队列尾
t := _p_.runqtail
if t == h {
// 头和尾相等,说明本地队列为空,找不到 g
return nil, false
}
// 获取队列头的 g
gp := _p_.runq[h%uint32(len(_p_.runq))].ptr()
// 原子操作,防止这中间被其他线程因为偷工作而修改
if atomic.Cas(&_p_.runqhead, h, h+1) { // cas-release, commits consume
return gp, false
}
}
}
整个源码结构比较简单,主要是两个 for 循环。
第一个 for 循环尝试返回 P 的 runnext 成员,因为 runnext 具有最高的运行优先级,因此要首先尝试获取 runnext。当发现 runnext 为空时,直接跳出循环,进入第二个。否则,用原子操作获取 runnext,并将其值修改为 0,也就是空。这里用到原子操作的原因是防止在这个过程中,有其他线程过来“偷工作”,导致并发修改 runnext 成员。
第二个 for 循环则是在尝试获取 runnext 成员失败后,尝试从本地队列中返回队列头的 goroutine。同样,先用原子操作获取队列头,使用原子操作的原因同样是防止其他线程“偷工作”时并发对队列头的并发写操作。之后,直接获取队列尾,因为不担心其他线程同时更改,所以直接获取。注意,“偷工作”时只会修改队列头。
比较队列头和队列尾,如果两者相等,说明 P 本地队列没有可运行的 goroutine,直接返回空。否则,算出队列头指向的 goroutine,再用一个 CAS 原子操作来尝试修改队列头,使用原子操作的原因同上。
globrunqget// 为了公平,每调用 schedule 函数 61 次就要从全局可运行 goroutine 队列中获取
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
// 从全局队列最大获取 1 个 goroutine
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
globrunqgetglobrunqget// 尝试从全局队列里获取可运行的 goroutine 队列
func globrunqget(_p_ *p, max int32) *g {
// 如果队列大小为 0
if sched.runqsize == 0 {
return nil
}
// 根据 p 的数量平分全局运行队列中的 goroutines
n := sched.runqsize/gomaxprocs + 1
if n > sched.runqsize {
n = sched.runqsize // 如果 gomaxprocs 为 1
}
// 修正"偷"的数量
if max > 0 && n > max {
n = max
}
// 最多只能"偷"本地工作队列一半的数量
if n > int32(len(_p_.runq))/2 {
n = int32(len(_p_.runq)) / 2
}
// 更新全局可运行队列长度
sched.runqsize -= n
// 如果都要被"偷"走,修改队列尾
if sched.runqsize == 0 {
sched.runqtail = 0
}
// 获取队列头指向的 goroutine
gp := sched.runqhead.ptr()
// 移动队列头
sched.runqhead = gp.schedlink
n--
for ; n > 0; n-- {
// 获取当前队列头
gp1 := sched.runqhead.ptr()
// 移动队列头
sched.runqhead = gp1.schedlink
// 尝试将 gp1 放入 P 本地,使全局队列得到更多的执行机会
runqput(_p_, gp1, false)
}
// 返回最开始获取到的队列头所指向的 goroutine
return gp
}
代码比较简单。首先根据全局队列的可运行 goroutine 长度和 P 的总数,来计算一个数值,表示每个 P 可平均分到的 goroutine 数量。
然后根据函数参数中的 max 以及 P 本地队列的长度来决定把多少全局队列中的 goroutine 转移到 P 本地。
最后,for 循环挨个把全局队列中 n-1 个 goroutine 转移到本地,并且返回最开始获取到的队列头所指向的 goroutine,毕竟它最需要得到运行的机会。
把全局队列中的可运行 goroutine 转移到本地队列,给了全局队列中可运行 goroutine 运行的机会,不然全局队列中的 goroutine 一直得不到运行。
最后,我们继续看第三个过程,从其他 P “偷工作”:
// 从本地运行队列和全局运行队列都没有找到需要运行的 goroutine,
// 调用 findrunnable 函数从其它工作线程的运行队列中偷取,如果偷不到,则当前工作线程进入睡眠
// 直到获取到 runnable goroutine 之后 findrunnable 函数才会返回。
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
这是整个找工作过程最复杂的部分:
// 从其他地方找 goroutine 来执行
func findrunnable() (gp *g, inheritTime bool) {
_g_ := getg()
top:
_p_ := _g_.m.p.ptr()
// ……………………
// local runq
// 从本地队列获取
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// global runq
// 从全局队列获取
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
// ……………………
// Steal work from other P's.
// 如果其他的 P 都处于空闲状态,那肯定没有其他工作要做
procs := uint32(gomaxprocs)
if atomic.Load(&sched.npidle) == procs-1 {
goto stop
}
// 如果有很多工作线程在找工作,那我就停下休息。避免消耗太多 CPU
if !_g_.m.spinning && 2*atomic.Load(&sched.nmspinning) >= procs-atomic.Load(&sched.npidle) {
goto stop
}
if !_g_.m.spinning {
// 设置自旋状态为 true
_g_.m.spinning = true
// 自旋状态数加 1
atomic.Xadd(&sched.nmspinning, 1)
}
// 从其它 p 的本地运行队列盗取 goroutine
for i := 0; i < 4; i++ {
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
// ……………………
stealRunNextG := i > 2 // first look for ready queues with more than 1 g
if gp := runqsteal(_p_, allp[enum.position()], stealRunNextG); gp != nil {
return gp, false
}
}
}
stop:
// ……………………
// return P and block
lock(&sched.lock)
if sched.gcwaiting != 0 || _p_.runSafePointFn != 0 {
unlock(&sched.lock)
goto top
}
if sched.runqsize != 0 {
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
return gp, false
}
// 当前工作线程解除与 p 之间的绑定,准备去休眠
if releasep() != _p_ {
throw("findrunnable: wrong p")
}
// 把 p 放入空闲队列
pidleput(_p_)
unlock(&sched.lock)
wasSpinning := _g_.m.spinning
if _g_.m.spinning {
// m 即将睡眠,不再处于自旋
_g_.m.spinning = false
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("findrunnable: negative nmspinning")
}
}
// check all runqueues once again
// 休眠之前再检查一下所有的 p,看一下是否有工作要做
for i := 0; i < int(gomaxprocs); i++ {
_p_ := allp[i]
if _p_ != nil && !runqempty(_p_) {
lock(&sched.lock)
_p_ = pidleget()
unlock(&sched.lock)
if _p_ != nil {
acquirep(_p_)
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
goto top
}
break
}
}
// ……………………
// 休眠
stopm()
goto top
}
这部分也是最能说明 M 找工作的锲而不舍精神:尽力去各个运行队列中寻找 goroutine,如果实在找不到则进入睡眠状态,等待有工作时,被其他 M 唤醒。
_p__p_不过,在偷之前,先看大的局势。如果其他所有的 P 都处于空闲状态,就说明其他 P 肯定没有工作可做,就没必要再去偷了,毕竟“地主家也没有余粮了”,跳到 stop 部分。接着再看下当前正在“偷工作”的线程数量“太多了”,就没必要扎堆了,这么多人,竞争肯定大,工作肯定不好找,也不好偷。
在真正的“偷”工作之前,把自己的自旋状态设置为 true,全局自旋数量加 1。
终于到了“偷工作”的部分了,好紧张!整个过程由两层 for 循环组成,外层控制尝试偷的次数,内层控制“偷”的顺序,并真正的去“偷”。实际上,内层会遍历所有的 P,因此,整体看来,会尝试 4 次扫遍所有的 P,并去“偷工作”,是不是非常有毅力!
第二层的循环并不是每次都按一个固定的顺序去遍历所有的 P,这样不太科学,而是使用了一些方法,“随机”地遍历。具体是使用了下面这个变量:
var stealOrder randomOrder
type randomOrder struct {
count uint32
coprimes []uint32
}
初始化的时候会给 count 赋一个值,例如 8,根据 count 计算出 coprimes,里面的元素是小于 count 的值,且和 8 互质,算出来是:[1, 3, 5, 7]。
第二层循环,开始随机给一个值,例如 2,则第一个访问的 P 就是 P2;从 coprimes 里取出索引为 2 的值为 5,那么,第二个访问的 P 索引就是 2+5=7;依此类推,第三个就是 7+5=12,和 count 做一个取余操作,即 12%8=4……
stealRunNextGstealRunNextG := i > 2
allp[enum.position()runqsteal(_p_, allp[enum.position()], stealRunNextG)// 从 p2 偷走一半的工作放到 _p_ 的本地
func runqsteal(_p_, p2 *p, stealRunNextG bool) *g {
// 队尾
t := _p_.runqtail
// 从 p2 偷取工作,放到 _p_.runq 的队尾
n := runqgrab(p2, &_p_.runq, t, stealRunNextG)
if n == 0 {
return nil
}
n--
// 找到最后一个 g,准备返回
gp := _p_.runq[(t+n)%uint32(len(_p_.runq))].ptr()
if n == 0 {
// 说明只偷了一个 g
return gp
}
// 队列头
h := atomic.Load(&_p_.runqhead) // load-acquire, synchronize with consumers
// 判断是否偷太多了
if t-h+n >= uint32(len(_p_.runq)) {
throw("runqsteal: runq overflow")
}
// 更新队尾,将偷来的工作加入队列
atomic.Store(&_p_.runqtail, t+n) // store-release, makes the item available for consumption
return gp
}
runqgrab_p_n := runqgrab(p2, &_p_.runq, t, stealRunNextG)
runqgrab_p_.runqt_p_.runq_p_.runq接着往下看,返回的 n 表示偷到的工作数量。先将 n 自减 1,目的是把第 n 个工作(也就是 g)直接返回,如果这时候 n 变成 0 了,说明就只偷到了一个 g,那就直接返回。否则,将队尾往后移动 n,把偷来的工作合法化,简直完美!
runqgrab// 从 _p_ 批量获取可运行 goroutine,放到 batch 数组里
// batch 是一个环,起始于 batchHead
// 返回偷的数量,返回的 goroutine 可被任何 P 执行
func runqgrab(_p_ *p, batch *[256]guintptr, batchHead uint32, stealRunNextG bool) uint32 {
for {
// 队列头
h := atomic.Load(&_p_.runqhead) // load-acquire, synchronize with other consumers
// 队列尾
t := atomic.Load(&_p_.runqtail) // load-acquire, synchronize with the producer
// g 的数量
n := t - h
// 取一半
n = n - n/2
if n == 0 {
if stealRunNextG {
// 连 runnext 都要偷,没有人性
// Try to steal from _p_.runnext.
if next := _p_.runnext; next != 0 {
// 这里是为了防止 _p_ 执行当前 g,并且马上就要阻塞,所以会马上执行 runnext,
// 这个时候偷就没必要了,因为让 g 在 P 之间"游走"不太划算,
// 就不偷了,给他们一个机会。
// channel 一次同步的的接收发送需要 50ns 左右,因此 3us 差不多给了他们 50 次机会了,做得还是不错的
if GOOS != "windows" {
usleep(3)
} else {
osyield()
}
if !_p_.runnext.cas(next, 0) {
continue
}
// 真的偷走了 next
batch[batchHead%uint32(len(batch))] = next
// 返回偷的数量,只有 1 个
return 1
}
}
// 没偷到
return 0
}
// 如果 n 这时变得太大了,重新来一遍了,不能偷的太多,做得太过分了
if n > uint32(len(_p_.runq)/2) { // read inconsistent h and t
continue
}
// 将 g 放置到 bacth 中
for i := uint32(0); i < n; i++ {
g := _p_.runq[(h+i)%uint32(len(_p_.runq))]
batch[(batchHead+i)%uint32(len(batch))] = g
}
// 工作被偷走了,更新一下队列头指针
if atomic.Cas(&_p_.runqhead, h, h+n) { // cas-release, commits consume
return n
}
}
}
stealRunNextGchannel继续看,再次判断 n 是否小于等于 p.runq 长度的一半,因为这个时候很可能 p 也被其他线程偷了,它的 p.runq 就没那么多工作了,这个时候就不能偷这么多了,要重新再走一次循环。
最后一个 for 循环,将 p.runq 里的 g 放到 batch 数组里。使用原子操作更新 p 的队列头指针,往后移动 n 个位置,这些都是被偷走的,伤心!
findrunnablestop先上锁,因为要将 P 放到全局空闲 P 链表里去。在这之前还不死心,再瞧一下全局队列里是否有工作,如果有,再去尝试偷全局。如果没有,就先解除当前工作线程和当前 P 的绑定关系:
// 解除 p 与 m 的关联
func releasep() *p {
_g_ := getg()
// ……………………
_p_ := _g_.m.p.ptr()
// ……………………
// 清空一些字段
_g_.m.p = 0
_g_.m.mcache = nil
_p_.m = 0
_p_.status = _Pidle
return _p_
}
_Pidle这之后,将其放入全局空闲 P 列表:
// 将 p 放到 _Pidle 列表里
//go:nowritebarrierrec
func pidleput(_p_ *p) {
if !runqempty(_p_) {
throw("pidleput: P has non-empty run queue")
}
_p_.link = sched.pidle
sched.pidle.set(_p_)
// 增加全局空闲 P 的数量
atomic.Xadd(&sched.npidle, 1) // TODO: fast atomic
}
构造链表的过程其实比较简单,先将 p.link 指向原来的 sched.pidle 所指向的 p,也就是原空闲链表的最后一个 P,最后,再更新 sched.pidle,使其指向当前 p,这样,新的链表就构造完成。
接下来就要真正地准备休眠了,但是仍然不死心!还要再查看一次所有的 P 是否有工作,如果发现任何一个 P 有工作的话(判断 P 的本地队列不空),就先从全局空闲 P 链表里先拿到一个 P:
// 试图从 _Pidle 列表里获取 p
//go:nowritebarrierrec
func pidleget() *p {
_p_ := sched.pidle.ptr()
if _p_ != nil {
sched.pidle = _p_.link
atomic.Xadd(&sched.npidle, -1) // TODO: fast atomic
}
return _p_
}
acquirep(_p_)_Prunning// 休眠,停止执行工作,直到有新的工作需要做为止
func stopm() {
// 当前 goroutine,g0
_g_ := getg()
// ……………………
retry:
lock(&sched.lock)
// 将 m 放到全局空闲链表里去
mput(_g_.m)
unlock(&sched.lock)
// 进入睡眠状态
notesleep(&_g_.m.park)
// 这里被其他工作线程唤醒
noteclear(&_g_.m.park)
// ……………………
acquirep(_g_.m.nextp.ptr())
_g_.m.nextp = 0
}
notesleep(&_g_.m.park)noteclear(&_g_.m.park)&_g_.m.parktype note struct {
key uintptr
}
很简单,只有一个 key 字段。
note 的底层实现机制跟操作系统相关,不同系统使用不同的机制,比如 linux 下使用的 futex 系统调用,而 mac 下则是使用的 pthread_cond_t 条件变量,note 对这些底层机制做了一个抽象和封装。
这种封装给扩展性带来了很大的好处,比如当睡眠和唤醒功能需要支持新平台时,只需要在 note 层增加对特定平台的支持即可,不需要修改上层的任何代码。
上面这一段来自阿波张的系列教程。我们接着来看下 notesleep 的实现:
// runtime/lock_futex.go
func notesleep(n *note) {
// g0
gp := getg()
if gp != gp.m.g0 {
throw("notesleep not on g0")
}
// -1 表示无限期休眠
ns := int64(-1)
// ……………………
// 这里之所以需要用一个循环,是因为 futexsleep 有可能意外从睡眠中返回,
// 所以 futexsleep 函数返回后还需要检查 note.key 是否还是 0,
// 如果是 0 则表示并不是其它工作线程唤醒了我们,
// 只是 futexsleep 意外返回了,需要再次调用 futexsleep 进入睡眠
for atomic.Load(key32(&n.key)) == 0 {
// 表示 m 被阻塞
gp.m.blocked = true
futexsleep(key32(&n.key), 0, ns)
// ……………………
// 被唤醒,更新标志
gp.m.blocked = false
}
}
继续往下追:
// runtime/os_linux.go
func futexsleep(addr *uint32, val uint32, ns int64) {
var ts timespec
if ns < 0 {
futex(unsafe.Pointer(addr), _FUTEX_WAIT, val, nil, nil, 0)
return
}
// ……………………
}
futexTEXT runtime·futex(SB),NOSPLIT,$0
// 为系统调用准备参数
MOVQ addr+0(FP), DI
MOVL op+8(FP), SI
MOVL val+12(FP), DX
MOVQ ts+16(FP), R10
MOVQ addr2+24(FP), R8
MOVL val3+32(FP), R9
// 系统调用编号
MOVL $202, AX
// 执行 futex 系统调用进入休眠,被唤醒后接着执行下一条 MOVL 指令
SYSCALL
// 保存系统调用的返回值
MOVL AX, ret+40(FP)
RET
findrunnable这就是 m 找工作的整个过程,历尽千辛万苦,终于修成正果。
参考资料: