
1.前言
切片是 Go 中的一种基本的数据结构,使用这种结构可以用来管理数据集合。切片的设计想法是由动态数组概念而来,为了开发者可以更加方便的使一个数据结构可以自动增加和减少。但是切片本身并不是动态数据或者数组指针。切片常见的操作有 reslice、append、copy。与此同时,切片还具有可索引,可迭代的优秀特性。
2.证明slice指向数组
程序解释:
main函数中定义了一个10个长度的整型数组array,然后定义了一个切片slice,切取数组的第6个元素,最后打印slice的长度和容量,判断切片的第一个元素和数组的第6个元素地址是否相等。
参考答案:
slice根据数组array创建,与数组共享存储空间,slice起始位置是array[5],长度为1,容量为5,slice[0]和array[5]地址相同。
func main() {
var array [10]int
var slice = array[5:6]
fmt.Println("lenth of slice: ", len(slice)) //lenth of slice: 1
fmt.Println("capacity of slice: ", cap(slice)) //capacity of slice: 5
fmt.Println(&slice[0] == &array[5]) //true
}
3.证明数组是值类型
Go 数组是值类型,赋值和函数传参操作都会复制整个数组数据。
可以看到,三个内存地址都不同,这也就验证了 Go 中数组赋值和函数传参都是值复制的
func main() {
arrayA := [2]int{100, 200}
var arrayB [2]int
arrayB = arrayA
fmt.Printf("arrayA : %p , %v\n", &arrayA, arrayA)
fmt.Printf("arrayB : %p , %v\n", &arrayB, arrayB)
testArray(arrayA)
/*
arrayA : 0xc4200bebf0 , [100 200]
arrayB : 0xc4200bec00 , [100 200]
func Array : 0xc4200bec30 , [100 200]*/
}
func testArray(x [2]int) {
fmt.Printf("func Array : %p , %v\n", &x, x)
}
4.slice由来
每次传参都用数组,那么每次数组都要被复制一遍。如果数组大小有 100万,在64位机器上就需要花费大约 800W 字节,即 8MB 内存。这样会消耗掉大量的内存。于是乎有人想到,函数传参用数组的指针。
不过传指针会有一个弊端,从打印结果可以看到,第一行和第三行指针地址都是同一个,万一原数组的指针指向更改了,那么函数里面的指针指向都会跟着更改。
切片的优势也就表现出来了。用切片传数组参数,既可以达到节约内存的目的,也可以达到合理处理好共享内存的问题。
由此我们可以得出结论:
把第一个大数组传递给函数会消耗很多内存,采用切片的方式传参可以避免上述问题。切片是引用传递,所以它们不需要使用额外的内存并且比使用数组更有效率。
func main() {
arrayA := [2]int{100, 200}
testArrayPoint1(&arrayA) // 1.传数组指针
arrayB := arrayA[:]
testArrayPoint2(&arrayB) // 2.传切片
fmt.Printf("arrayA : %p , %v\n", &arrayA, arrayA)
/*
func Array : 0xc4200b0140 , [100 200]
func Array : 0xc4200b0180 , [100 300]
arrayA : 0xc4200b0140 , [100 400]
*/
}
func testArrayPoint1(x *[2]int) {
fmt.Printf("func Array : %p , %v\n", x, *x)
(*x)[1] += 100
}
func testArrayPoint2(x *[]int) {
fmt.Printf("func Array : %p , %v\n", x, *x)
(*x)[1] += 100
}
5.slice数据结构
切片本身并不是动态数组或者数组指针。它内部实现的数据结构通过指针引用底层数组,设定相关属性将数据读写操作限定在指定的区域内。切片本身是一个只读对象,其工作机制类似数组指针的一种封装。
切片(slice)是对数组一个连续片段的引用,所以切片是一个引用类型(因此更类似于 C++ 中的 Vector 类型,或者 Python 中的 list 类型)。这个片段可以是整个数组,或者是由起始和终止索引标识的一些项的子集。需要注意的是,终止索引标识的项不包括在切片内。切片提供了一个与指向数组的动态窗口。
给定项的切片索引可能比相关数组的相同元素的索引小。和数组不同的是,切片的长度可以在运行时修改,最小为 0 最大为相关数组的长度:切片是一个长度可变的数组。
Slice 的数据结构定义如下:
type slice struct {
array unsafe.Pointer
len int
cap int
}
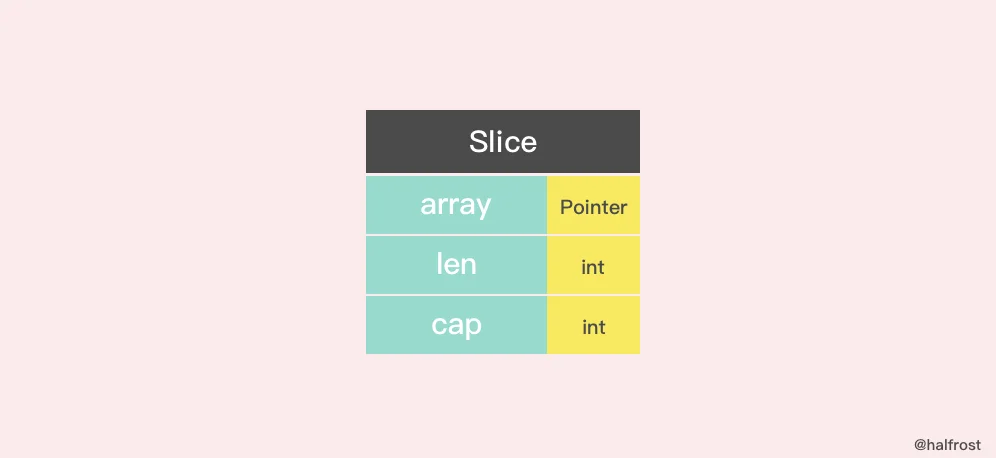
切片的结构体由3部分构成,Pointer 是指向一个数组的指针,len 代表当前切片的长度,cap 是当前切片的容量。cap 总是大于等于 len 的。
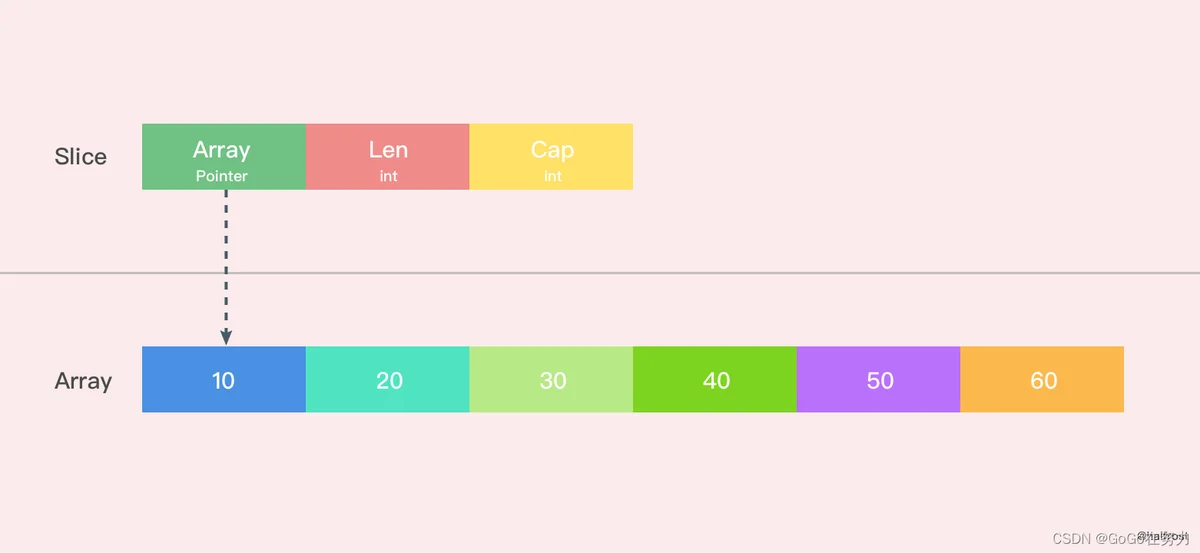
6.slice中获取一块内存地址
func main() {
s := make([]byte, 200)
ptr := unsafe.Pointer(&s[0])
fmt.Println(ptr) //0xc000196000
fmt.Println(&s[0]) //0xc000196000
}
7.从go的内存地址中构造一个slice
7.1方法一
构造一个虚拟的结构体,把 slice 的数据结构拼出来。
func main() {
var ptr unsafe.Pointer
var s1 = struct {
addr unsafe.Pointer
len int
cap int
}{ptr, 1, 1}
s := *(*[]byte)(unsafe.Pointer(&s1))
fmt.Println(s) //输出:[]
fmt.Println(s1.len) //输出:1
fmt.Println(s1.cap) //输出:1
//fmt.Println(&s)//会抛出panic: runtime error: invalid memory address or nil pointer dereference错误
}
func main() {
var ptr unsafe.Pointer
var s1 = struct {
addr uintptr //不能这样写,否则下面会编译报错
len int
cap int
}{ptr, 1, 1} //无法将unsafe.Pointer类型转化为ptr类型
s := *(*[]byte)(unsafe.Pointer(&s1))
fmt.Println(s)
}
7.2方法二
当然还有更加直接的方法,在 Go 的反射中就存在一个与之对应的数据结构 SliceHeader,我们可以用它来构造一个 slice
func main() {
var o []byte
var ptr unsafe.Pointer
sliceHeader := (*reflect.SliceHeader)((unsafe.Pointer(&o)))
sliceHeader.Cap = 2
sliceHeader.Len = 1
sliceHeader.Data = uintptr(ptr)
fmt.Println(sliceHeader) //&{0 1 2}
fmt.Println(&sliceHeader) //0xc000006028
/*
reflect.SliceHeader:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
*/
}
8.make创建slice
make 函数允许在运行期动态指定数组长度,绕开了数组类型必须使用编译期常量的限制。
func makeslice(et *_type, len, cap int) slice {
// 根据切片的数据类型,获取切片的最大容量
maxElements := maxSliceCap(et.size)
// 比较切片的长度,长度值域应该在[0,maxElements]之间
if len < 0 || uintptr(len) > maxElements {
panic(errorString("makeslice: len out of range"))
}
// 比较切片的容量,容量值域应该在[len,maxElements]之间
if cap < len || uintptr(cap) > maxElements {
panic(errorString("makeslice: cap out of range"))
}
// 根据切片的容量申请内存
p := mallocgc(et.size*uintptr(cap), et, true)
// 返回申请好内存的切片的首地址
return slice{p, len, cap}
}
还有一个 int64 的版本:
实现原理和上面的是一样的,只不过多了把 int64 转换成 int 这一步罢了。
func makeslice64(et *_type, len64, cap64 int64) slice {
len := int(len64)
if int64(len) != len64 {
panic(errorString("makeslice: len out of range"))
}
cap := int(cap64)
if int64(cap) != cap64 {
panic(errorString("makeslice: cap out of range"))
}
return makeslice(et, len, cap)
}
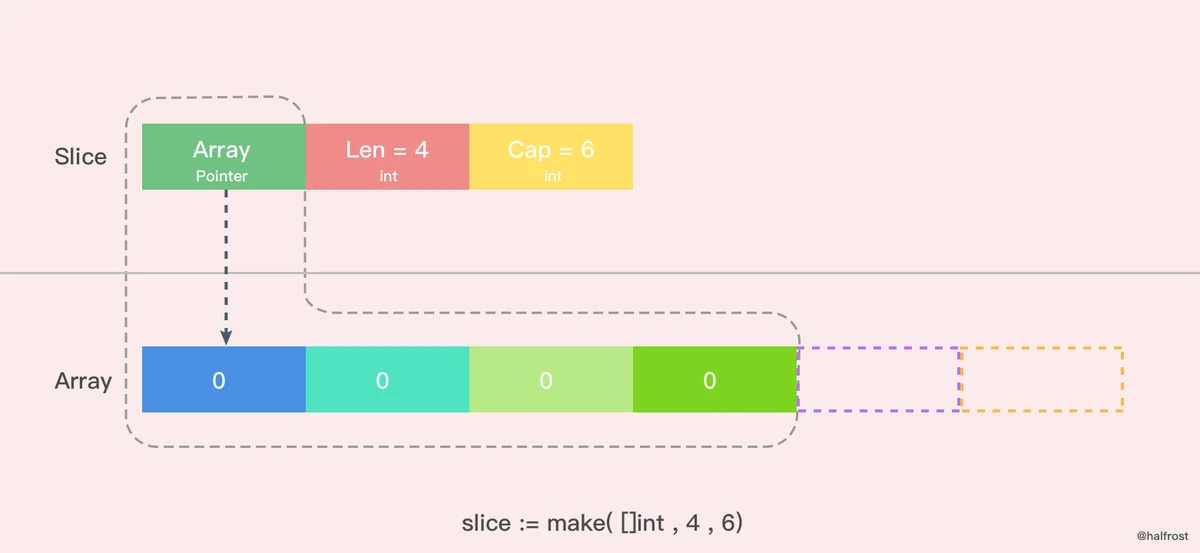
下图是用 make 函数创建的一个 len = 4, cap = 6 的切片。内存空间申请了6个 int 类型的内存大小。由于 len = 4,所以后面2个暂时访问不到,但是容量还是在的。这时候数组里面每个变量都是0 。
9.字面量创建slice
除了 make 函数可以创建切片以外,字面量也可以创建切片。
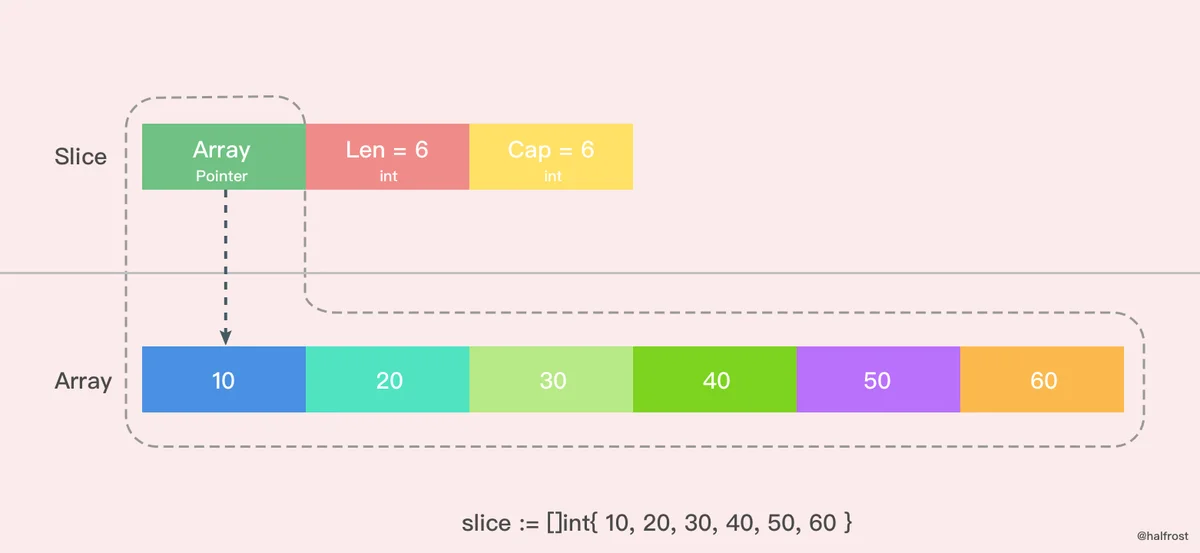
这里是用字面量创建的一个 len = 6,cap = 6 的切片,这时候数组里面每个元素的值都初始化完成了。需要注意的是 [ ] 里面不要写数组的容量,因为如果写了个数以后就是数组了,而不是切片了。
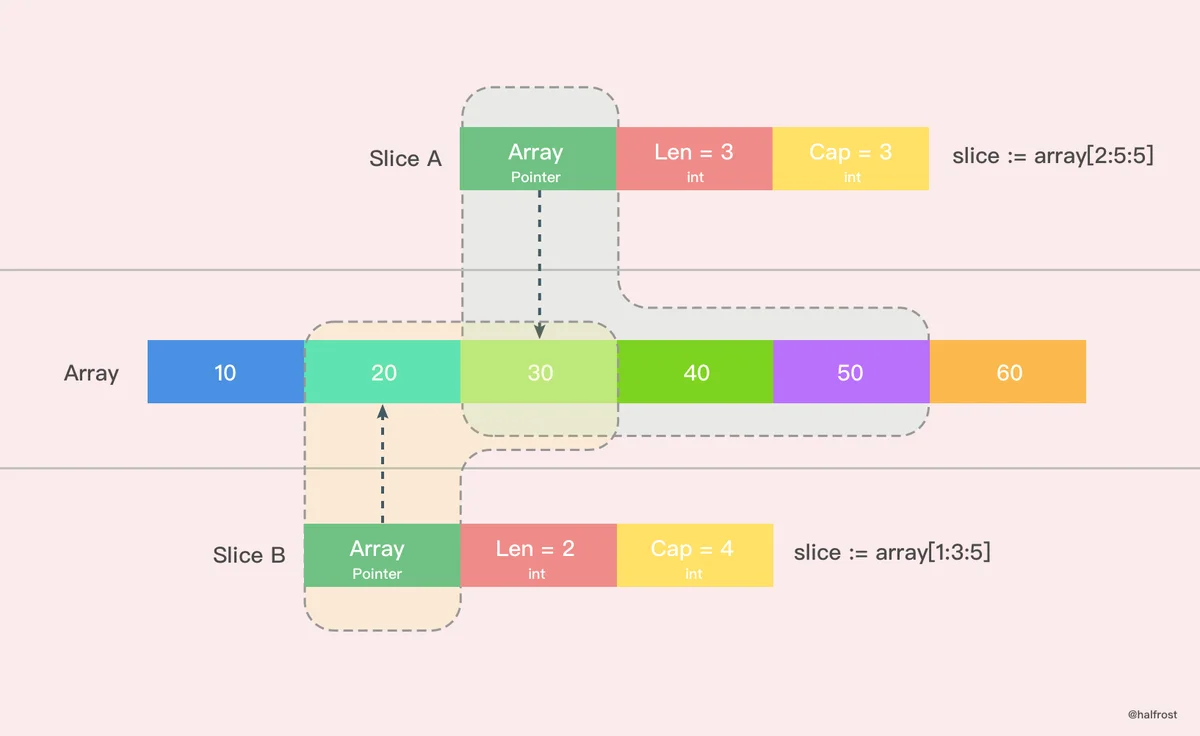
还有一种简单的字面量创建切片的方法。如下图,下图就 Slice A 创建出了一个 len = 3,cap = 3 的切片。从原数组的第二位元素(0是第一位)开始切,一直切到第四位为止(不包括第五位)。同理,Slice B 创建出了一个 len = 2,cap = 4 的切片。
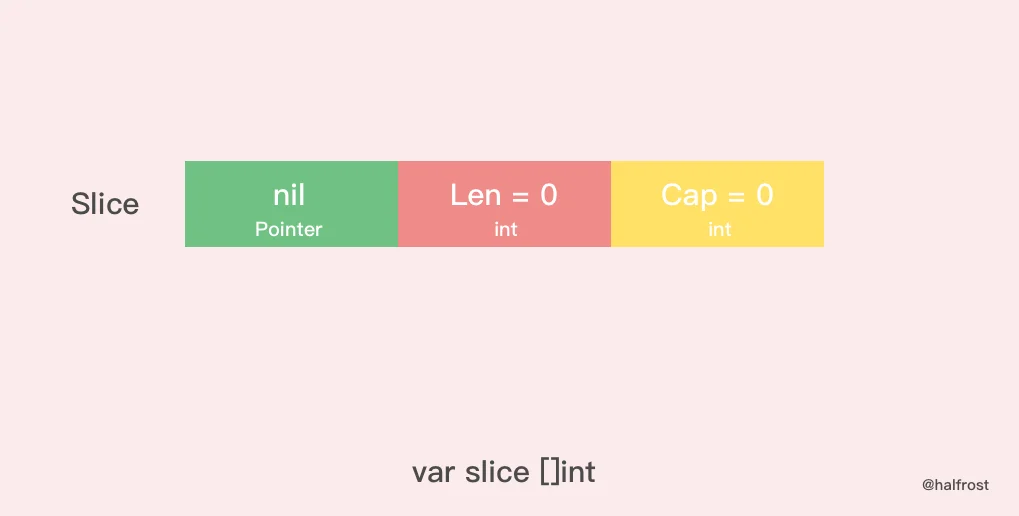
10.nil切片
var创建切片不初始值情况下,该切片叫做"nil切片",nil 切片被用在很多标准库和内置函数中,描述一个不存在的切片的时候,就需要用到 nil 切片。比如函数在发生异常的时候,返回的切片就是 nil 切片。nil 切片的指针指向 nil
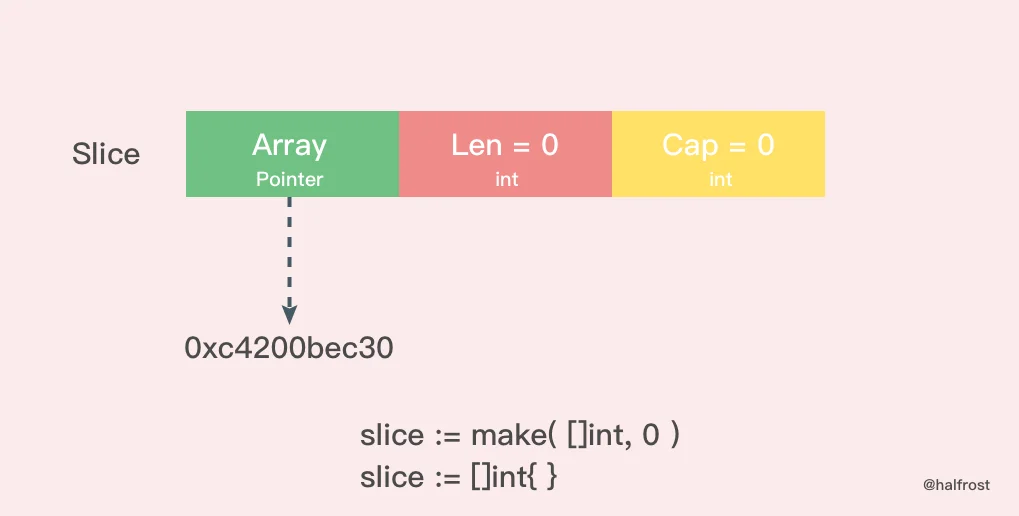
11.空切片
make只指定len=0创建情况下,该切片叫做"空切片",空切片和 nil 切片的区别在于,空切片指向的地址不是nil,指向的是一个内存地址,底层元素包含0个元素。
最后需要说明的一点是。不管是使用 nil 切片还是空切片,对其调用内置函数 append,len 和 cap 的效果都是一样的。
var sNil []int //底层array指向nil
var sEmpty = make([]int, 0) //底层array指向一个内存地址,但是这个内存地址没有分配空间给它
fmt.Println(len(sNil), len(sEmpty), cap(sNil), cap(sEmpty))//输出:0 0 0 0
package main
import (
"fmt"
"unsafe"
)
type Student struct {
Name string
}
var list map[string]Student
func main() {
var s1 []int
s2 := make([]int, 0)
fmt.Println(unsafe.Sizeof(s1)) //24
fmt.Println(unsafe.Sizeof(s2)) //24
fmt.Println(s1)//[]
fmt.Println(s2)//[]
fmt.Println(s1 == nil)//true
fmt.Println(s2 == nil)//false
}
11.切片扩容
当一个切片的容量满了,就需要扩容了。怎么扩,策略是什么?
下述就是扩容的实现。主要需要关注的有两点,一个是扩容时候的策略,还有一个就是扩容是生成全新的内存地址还是在原来的地址后追加。
func growslice(et *_type, old slice, cap int) slice {
if raceenabled {
callerpc := getcallerpc(unsafe.Pointer(&et))
racereadrangepc(old.array, uintptr(old.len*int(et.size)), callerpc, funcPC(growslice))
}
if msanenabled {
msanread(old.array, uintptr(old.len*int(et.size)))
}
if et.size == 0 {
// 如果新要扩容的容量比原来的容量还要小,这代表要缩容了,那么可以直接报panic了。
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
// 如果当前切片的大小为0,还调用了扩容方法,那么就新生成一个新的容量的切片返回。
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
// 这里就是扩容的策略
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
// 计算新的切片的容量,长度。
var lenmem, newlenmem, capmem uintptr
const ptrSize = unsafe.Sizeof((*byte)(nil))
switch et.size {
case 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
newcap = int(capmem)
case ptrSize:
lenmem = uintptr(old.len) * ptrSize
newlenmem = uintptr(cap) * ptrSize
capmem = roundupsize(uintptr(newcap) * ptrSize)
newcap = int(capmem / ptrSize)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem = roundupsize(uintptr(newcap) * et.size)
newcap = int(capmem / et.size)
}
// 判断非法的值,保证容量是在增加,并且容量不超过最大容量
if cap < old.cap || uintptr(newcap) > maxSliceCap(et.size) {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
if et.kind&kindNoPointers != 0 {
// 在老的切片后面继续扩充容量
p = mallocgc(capmem, nil, false)
// 将 lenmem 这个多个 bytes 从 old.array地址 拷贝到 p 的地址处
memmove(p, old.array, lenmem)
// 先将 P 地址加上新的容量得到新切片容量的地址,然后将新切片容量地址后面的 capmem-newlenmem 个 bytes 这块内存初始化。为之后继续 append() 操作腾出空间。
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// 重新申请新的数组给新切片
// 重新申请 capmen 这个大的内存地址,并且初始化为0值
p = mallocgc(capmem, et, true)
if !writeBarrier.enabled {
// 如果还不能打开写锁,那么只能把 lenmem 大小的 bytes 字节从 old.array 拷贝到 p 的地址处
memmove(p, old.array, lenmem)
} else {
// 循环拷贝老的切片的值
for i := uintptr(0); i < lenmem; i += et.size {
typedmemmove(et, add(p, i), add(old.array, i))
}
}
}
// 返回最终新切片,容量更新为最新扩容之后的容量
return slice{p, old.len, newcap}
}
12.扩容策略
先看看扩容策略。
func main() {
slice := []int{10, 20, 30, 40}
newSlice := append(slice, 50)
fmt.Printf("Before slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("Before newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
newSlice[1] += 10
fmt.Printf("After slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("After newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
}
输出结果:
Before slice = [10 20 30 40], Pointer = 0xc4200b0140, len = 4, cap = 4
Before newSlice = [10 20 30 40 50], Pointer = 0xc4200b0180, len = 5, cap = 8
After slice = [10 20 30 40], Pointer = 0xc4200b0140, len = 4, cap = 4
After newSlice = [10 30 30 40 50], Pointer = 0xc4200b0180, len = 5, cap = 8
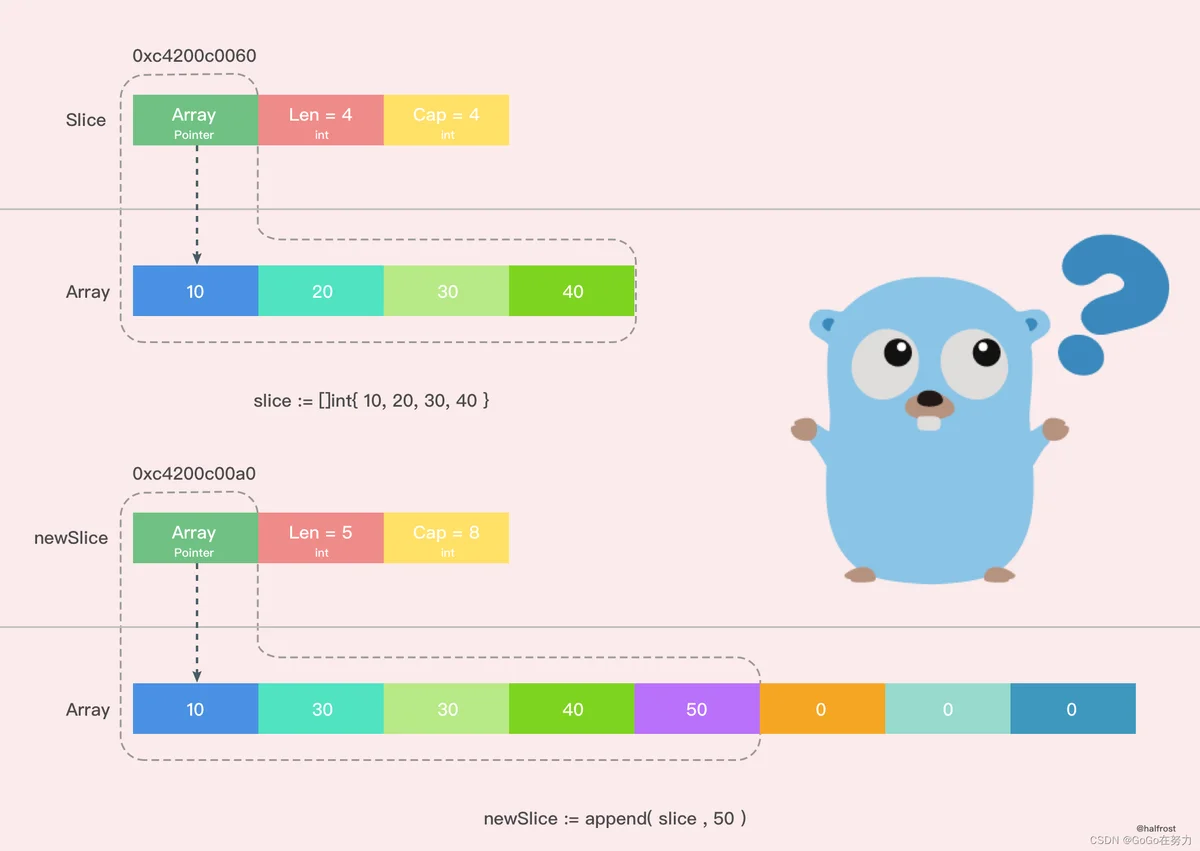
用图表示出上述过程。
从图上我们可以很容易的看出,新的切片和之前的切片已经不同了,因为新的切片更改了一个值,并没有影响到原来的数组,新切片指向的数组是一个全新的数组。并且 cap 容量也发生了变化。
Go 中切片扩容的策略是这样的:
1.首先判断,如果新申请容量cap大于2倍的旧容量old.cap,最终容量newcap就是新申请容量cap
2.否则判断,如果旧切片的长度小于1024,则最终容量newcap就是旧容量old.cap的两倍,即newcap=doublecap
3.否则判断,如果旧切片长度大于等于1024,则最终容量newcap从旧容量old.cap开始循环增加原来的 1/4,直到最终容量newcap大于等于新申请容量cap,即newcap >= cap
4.如果最终容量newcap计算值溢出,则最终容量newcap就是新申请容量cap
注意:扩容扩大的容量都是针对原来的容量而言的,而不是针对原来数组的长度而言的。
// 这里就是扩容的策略
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
if newcap <= 0 {
newcap = cap
}
}
}
13.扩容后新数组or老数组?
再谈谈扩容之后的数组一定是新的么?这个不一定,分两种情况。
13.1老数组情况
func main() {
array := [4]int{10, 20, 30, 40}
slice := array[0:2]
newSlice := append(slice, 50)
fmt.Printf("Before slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("Before newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
newSlice[1] += 10
fmt.Printf("After slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("After newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
fmt.Printf("After array = %v\n", array)
}
打印输出:
Before slice = [10 20], Pointer = 0xc4200c0040, len = 2, cap = 4
Before newSlice = [10 20 50], Pointer = 0xc4200c0060, len = 3, cap = 4
After slice = [10 30], Pointer = 0xc4200c0040, len = 2, cap = 4
After newSlice = [10 30 50], Pointer = 0xc4200c0060, len = 3, cap = 4
After array = [10 30 50 40]
把上述过程用图表示出来,如下图。
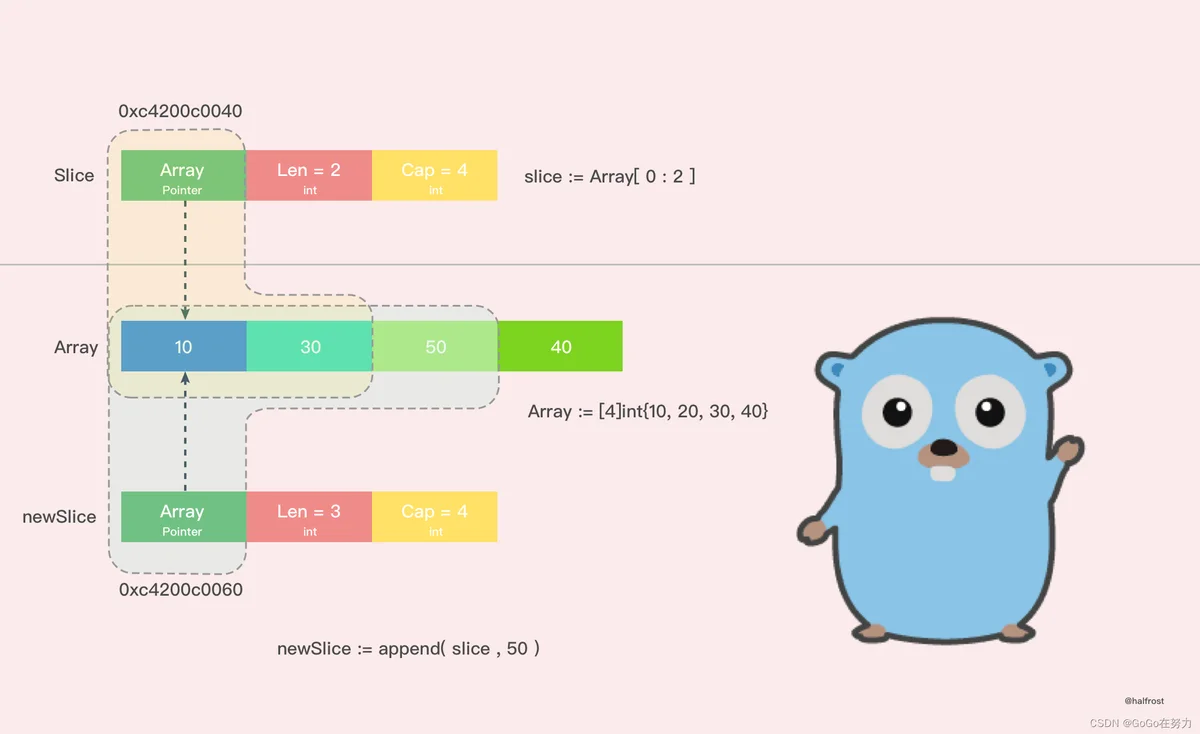
通过打印的结果,我们可以看到,在这种情况下,扩容以后并没有新建一个新的数组,扩容前后的数组都是同一个,这也就导致了新的切片修改了一个值,也影响到了老的切片了。并且 append() 操作也改变了原来数组里面的值。一个 append() 操作影响了这么多地方,如果原数组上有多个切片,那么这些切片都会被影响!无意间就产生了莫名的 bug!
这种情况,由于原数组还有容量可以扩容,所以执行 append() 操作以后,会在原数组上直接操作,所以这种情况下,扩容以后的数组还是指向原来的数组。
这种情况也极容易出现在字面量创建切片时候,第三个参数 cap 传值的时候,如果用字面量创建切片,cap 并不等于指向数组的总容量,那么这种情况就会发生。
slice := array[1:2:3]
func main() {
array := [4]int{10, 20, 30, 40}
slice := array[1:2:3]
fmt.Printf("Before slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
newSlice := append(slice, 50)
fmt.Printf("Before slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("Before newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
newSlice[1] += 10
fmt.Printf("After slice = %v, Pointer = %p, len = %d, cap = %d\n", slice, &slice, len(slice), cap(slice))
fmt.Printf("After newSlice = %v, Pointer = %p, len = %d, cap = %d\n", newSlice, &newSlice, len(newSlice), cap(newSlice))
fmt.Printf("After array = %v\n", array)
/*
Before slice = [20], Pointer = 0xc000004078, len = 1, cap = 2
Before slice = [20], Pointer = 0xc000004078, len = 1, cap = 2
Before newSlice = [20 50], Pointer = 0xc0000040a8, len = 2, cap = 2
After slice = [20], Pointer = 0xc000004078, len = 1, cap = 2
After newSlice = [20 60], Pointer = 0xc0000040a8, len = 2, cap = 2
After array = [10 20 60 40]
*/
}
上面这种情况非常危险,极度容易产生 bug 。
建议用字面量创建切片的时候,cap 的值一定要保持清醒,避免共享原数组导致的 bug。
13.2新数组情况
情况二其实就是在扩容策略里面举的例子,在那个例子中之所以生成了新的切片,是因为原来数组的容量已经达到了最大值,再想扩容, Go 默认会先开一片内存区域,把原来的值拷贝过来,然后再执行 append() 操作。这种情况丝毫不影响原数组。
所以建议尽量避免情况一,尽量使用情况二,避免 bug 产生。
14.slice拷贝
Slice 中拷贝方法有2个。
func slicecopy(to, fm slice, width uintptr) int {
// 如果源切片或者目标切片有一个长度为0,那么就不需要拷贝,直接 return
if fm.len == 0 || to.len == 0 {
return 0
}
// n 记录下源切片或者目标切片较短的那一个的长度
n := fm.len
if to.len < n {
n = to.len
}
// 如果入参 width = 0,也不需要拷贝了,返回较短的切片的长度
if width == 0 {
return n
}
// 如果开启了竞争检测
if raceenabled {
callerpc := getcallerpc(unsafe.Pointer(&to))
pc := funcPC(slicecopy)
racewriterangepc(to.array, uintptr(n*int(width)), callerpc, pc)
racereadrangepc(fm.array, uintptr(n*int(width)), callerpc, pc)
}
// 如果开启了 The memory sanitizer (msan)
if msanenabled {
msanwrite(to.array, uintptr(n*int(width)))
msanread(fm.array, uintptr(n*int(width)))
}
size := uintptr(n) * width
if size == 1 {
// TODO: is this still worth it with new memmove impl?
// 如果只有一个元素,那么指针直接转换即可
*(*byte)(to.array) = *(*byte)(fm.array) // known to be a byte pointer
} else {
// 如果不止一个元素,那么就把 size 个 bytes 从 fm.array 地址开始,拷贝到 to.array 地址之后
memmove(to.array, fm.array, size)
}
return n
}
在这个方法中,slicecopy 方法会把源切片值(即 fm Slice )中的元素复制到目标切片(即 to Slice )中,并返回被复制的元素个数,copy 的两个类型必须一致。slicecopy 方法最终的复制结果取决于较短的那个切片,当较短的切片复制完成,整个复制过程就全部完成了。
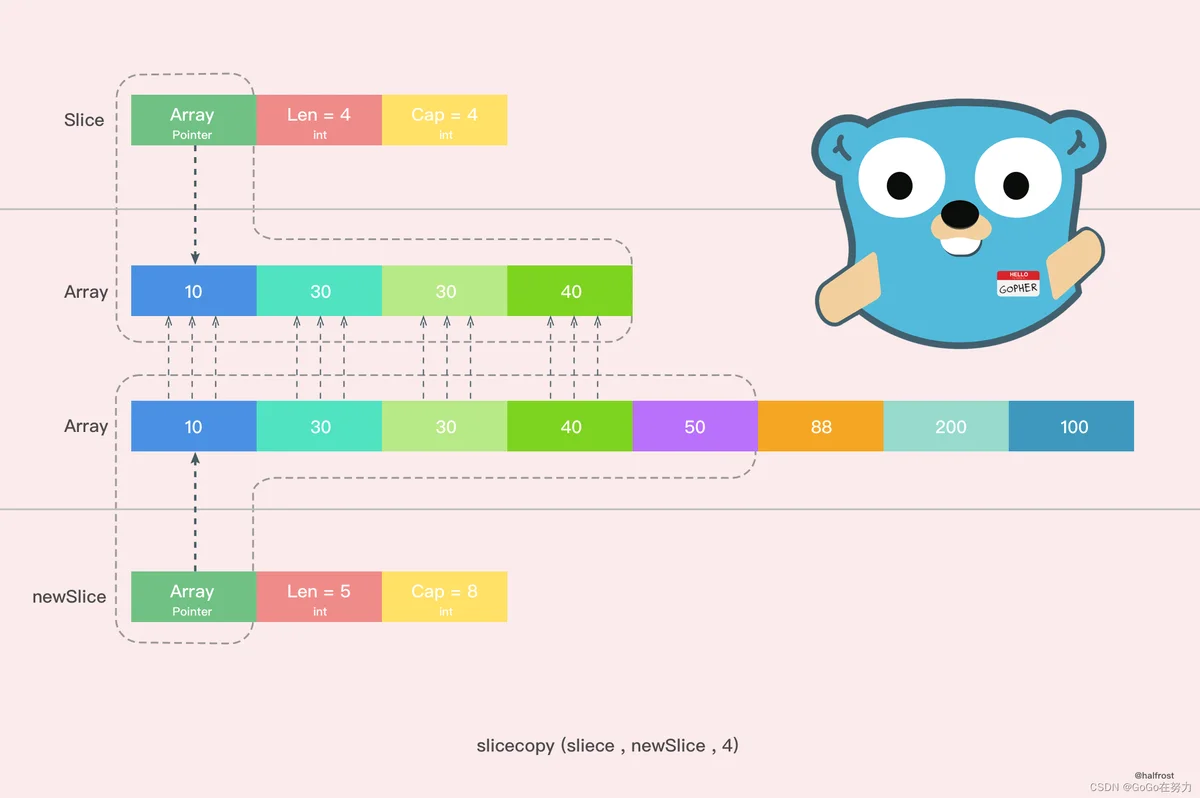
举个例子,比如:
func main() {
array := []int{10, 20, 30, 40}
slice := make([]int, 6)
fmt.Println(slice, len(slice), cap(slice)) //[0 0 0 0 0 0] 6 6
n := copy(slice, array)
fmt.Println(n, slice) //4 [10 20 30 40 0 0]
fmt.Println(slice, len(slice), cap(slice))//[10 20 30 40 0 0] 6 6
}
还有一个拷贝的方法,这个方法原理和 slicecopy 方法类似,不在赘述了,注释写在代码里面了。
func slicestringcopy(to []byte, fm string) int {
// 如果源切片或者目标切片有一个长度为0,那么就不需要拷贝,直接 return
if len(fm) == 0 || len(to) == 0 {
return 0
}
// n 记录下源切片或者目标切片较短的那一个的长度
n := len(fm)
if len(to) < n {
n = len(to)
}
// 如果开启了竞争检测
if raceenabled {
callerpc := getcallerpc(unsafe.Pointer(&to))
pc := funcPC(slicestringcopy)
racewriterangepc(unsafe.Pointer(&to[0]), uintptr(n), callerpc, pc)
}
// 如果开启了 The memory sanitizer (msan)
if msanenabled {
msanwrite(unsafe.Pointer(&to[0]), uintptr(n))
}
// 拷贝字符串至字节数组
memmove(unsafe.Pointer(&to[0]), stringStructOf(&fm).str, uintptr(n))
return n
}
再举个例子,比如:
func main() {
slice := make([]byte, 3)
n := copy(slice, "abcdef")
fmt.Println(n,slice)
}
输出:
3 [97,98,99]
不能把切片copy给array
15.for range切片是值拷贝
说到拷贝,切片中有一个需要注意的问题。
func main() {
slice := []int{10, 20, 30, 40}
for index, value := range slice {
fmt.Printf("value = %d , value-addr = %x , slice-addr = %x\n", value, &value, &slice[index])
}
}
输出:
value = 10 , value-addr = c4200aedf8 , slice-addr = c4200b0320
value = 20 , value-addr = c4200aedf8 , slice-addr = c4200b0328
value = 30 , value-addr = c4200aedf8 , slice-addr = c4200b0330
value = 40 , value-addr = c4200aedf8 , slice-addr = c4200b0338
从上面结果我们可以看到,如果用 range 的方式去遍历一个切片,拿到的 Value 其实是切片里面的值拷贝。所以每次打印 Value 的地址都不变。
由于 Value 是值拷贝的,并非引用传递,所以直接改 Value 是达不到更改原切片值的目的的,需要通过 &slice[index] 获取真实的地址。
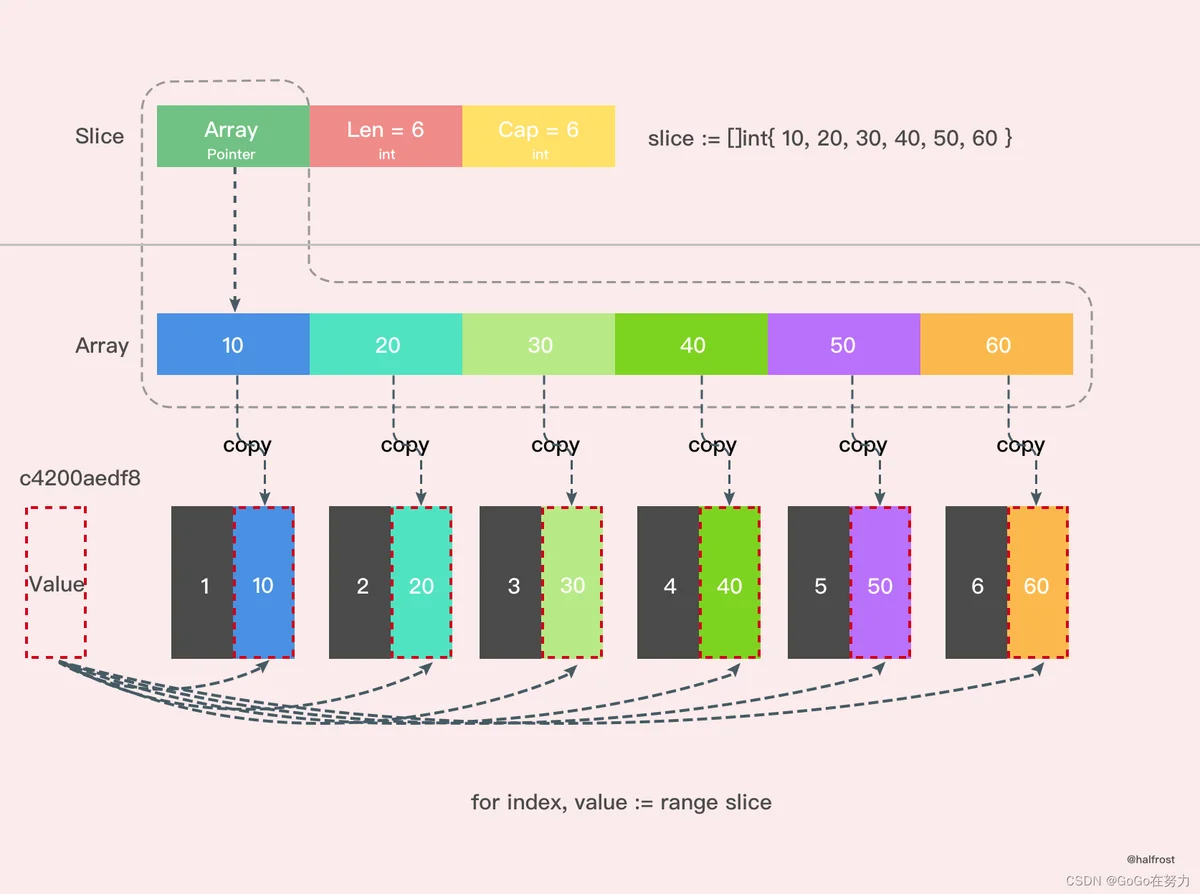
value的地址一直处于变化当中
func main() {
slice := []int{10, 20, 30, 40}
fmt.Println(&slice[0])
fmt.Println(&slice[1])
fmt.Println(&slice[2])
fmt.Println(&slice[3])
for index, value := range slice {
fmt.Printf("value = %d , value-addr = %x , slice-addr = %x\n", value, &value, &slice[index])
}
/*
0xc0000a8060
0xc0000a8068
0xc0000a8070
0xc0000a8078
value = 10 , value-addr = c0000aa058 , slice-addr = c0000a8060
value = 20 , value-addr = c0000aa058 , slice-addr = c0000a8068
value = 30 , value-addr = c0000aa058 , slice-addr = c0000a8070
value = 40 , value-addr = c0000aa058 , slice-addr = c0000a8078
*/
}
package main
import "fmt"
func main() {
slice := []int{10, 20, 30, 40}
fmt.Println(&slice[0])
fmt.Println(&slice[1])
fmt.Println(&slice[2])
fmt.Println(&slice[3])
for _, value := range slice {
fmt.Println(&value)
fmt.Println(*(&value))
}
/*
0xc00000e1c0
0xc00000e1c8
0xc00000e1d0
0xc00000e1d8
0xc0000160a8
10
0xc0000160a8
20
0xc0000160a8
30
0xc0000160a8
40
*/
}
package main
import "fmt"
func main() {
slice := []int{0, 1, 2, 3}
m := make(map[int]*int)
for key, value := range slice {
m[key] = &value
fmt.Println(&value)
}
fmt.Println(m)
fmt.Println(&slice[3])
/* 0xc0000aa058
0xc0000aa058
0xc0000aa058
0xc0000aa058
map[0:0xc0000160a8 1:0xc0000160a8 2:0xc0000160a8 3:0xc0000160a8]
0xc00000e1d8
*/
for key, val := range m {
fmt.Println(key, "-v", *val)
}
/*
map[0:0xc0000160a8 1:0xc0000160a8 2:0xc0000160a8 3:0xc0000160a8]
0xc00000e1d8
0 -v 3
1 -v 3
2 -v 3
3 -v 3
*/
}
//c里存的一直是a的地址
func main() {
a := 4
b := 5
c := &a
fmt.Println(&a) //0xc0000160a8
fmt.Println(&b) //0xc0000160c0
fmt.Println(&c) //0xc000006028
fmt.Println(c) //0xc0000160a8
a = b
fmt.Println(c) //0xc0000160a8
}
package main
import "fmt"
func main() {
a := 4
a = 5
fmt.Println(&a)
fmt.Println(&a)
/*
0xc0000aa058
0xc0000aa058
*/
}
package main
import "fmt"
func main() {
a := 4
b := 5
fmt.Println(&a)
a = b
fmt.Println(&a)
/*
0xc0000160a8
0xc0000160a8
*/
}
package main
import "fmt"
func main() {
a := [1]int{1}
b := [1]int{2}
fmt.Printf("%p\n", &a)
fmt.Printf("%p\n", &b)
a = b
fmt.Printf("%p\n", &a)
fmt.Printf("%p\n", &b)
/*
0xc0000160a8
0xc0000160c0
0xc0000160a8
0xc0000160c0
*/
}
package main
import "fmt"
func main() {
a := []int{1}
b := []int{2, 3}
fmt.Printf("%p\n", &a)
fmt.Printf("%p\n", &b)
a = b
fmt.Printf("%p\n", &a)
fmt.Printf("%p\n", &b)
/*
0xc000004078
0xc000004090
0xc000004078
0xc000004090
*/
}
16.实验
16.1扩容地址重新分配
var s = make([]int, 2, 2)
s[0] = 1
fmt.Println(unsafe.Pointer(&s[0])) //0xc0000aa090
s[1] = 2
fmt.Println(unsafe.Pointer(&s[0])) //0xc0000aa090
// Tip: 扩容后,slice的array的地址会重新分配
s = append(s, 3)
fmt.Println(unsafe.Pointer(&s[0])) //0xc0000a80a0
var s = make([]int, 2, 2)
s[0] = 1
s[1] = 2
fmt.Println(unsafe.Pointer(&s)) //0xc000004078
fmt.Println(unsafe.Pointer(&s[0])) //0xc0000160d0
16.2截取切片但指向同一底层数组
func main() {
var s = make([]int, 2, 2)
s[0] = 1
s[1] = 2
fmt.Println(unsafe.Pointer(&s)) //0xc000004078
fmt.Println(unsafe.Pointer(&s[0])) //0xc0000160b0
a := s[:2]
fmt.Println(unsafe.Pointer(&a)) //0xc000004090
fmt.Println(unsafe.Pointer(&a[0])) //0xc0000160b0
}
16.3copy拷贝slice重新分配底层array内存
var s = make([]int, 2, 2)
b := make([]int, 2)
// Tip: 如果要进行slice拷贝,使用copy方法
copy(b, s) //copy会重新分配底层array的内存
fmt.Println(unsafe.Pointer(&s[0])) //0xc0000160b0
fmt.Println(unsafe.Pointer(&b[0])) //0xc0000160c0
func main() {
var s = make([]int, 2, 2)
s[0] = 1
s[0] = 2
b := make([]int, 2)
b[0] = 3
b[1] = 4
fmt.Println(s) //[2 0]
fmt.Println(b) //[3 4]
fmt.Println(unsafe.Pointer(&s[0])) //0xc0000160b0
fmt.Println(unsafe.Pointer(&b[0])) //0xc0000160c0
copy(b, s)
fmt.Println(s) //[2 0]
fmt.Println(b) //[3 4]
fmt.Println(unsafe.Pointer(&s[0])) //0xc0000160b0
fmt.Println(unsafe.Pointer(&b[0])) //0xc0000160c0
}
16.4对nil切片append容量的变化
func main() {
var a []int
a = append(a, 1)
fmt.Println(a, len(a), cap(a))
var b []int
b = append(b, 1, 2)
fmt.Println(b, len(b), cap(b))
var c []int
c = append(c, 1, 2, 3)
fmt.Println(c, len(c), cap(c))
var d []int
d = append(d, 1, 2, 3, 4)
fmt.Println(d, len(d), cap(d))
var e []int
e = append(e, 1, 2, 3, 4, 5)
fmt.Println(e, len(e), cap(e))
var f []int
f = append(f, 1, 2, 3, 4, 5, 6)
fmt.Println(f, len(f), cap(f))
var g []int
g = append(g, 1, 2, 3, 4, 5, 6, 7)
fmt.Println(g, len(g), cap(g))
var h []int
h = append(h, 1, 2, 3, 4, 5, 6, 7, 8)
fmt.Println(h, len(h), cap(h))
/*
[1] 1 1
[1 2] 2 2
[1 2 3] 3 3
[1 2 3 4] 4 4
[1 2 3 4 5] 5 6
[1 2 3 4 5 6] 6 6
[1 2 3 4 5 6 7] 7 8
[1 2 3 4 5 6 7 8] 8 8
*/
}
16.5.对nil切片字面声明容量的变化
func main() {
var a []int
a = []int{1}
fmt.Println(a, len(a), cap(a))
var b []int
b = []int{1, 2}
fmt.Println(b, len(b), cap(b))
var c []int
c = []int{1, 2, 3}
fmt.Println(c, len(c), cap(c))
var d []int
d = []int{1, 2, 3, 4}
fmt.Println(d, len(d), cap(d))
var e []int
e = []int{1, 2, 3, 4, 5}
fmt.Println(e, len(e), cap(e))
var f []int
f = []int{1, 2, 3, 4, 5, 6}
fmt.Println(f, len(f), cap(f))
var g []int
g = []int{1, 2, 3, 4, 5, 6, 7}
fmt.Println(g, len(g), cap(g))
var h []int
h = []int{1, 2, 3, 4, 5, 6, 7, 8}
fmt.Println(h, len(h), cap(h))
/*
[1] 1 1
[1 2] 2 2
[1 2 3] 3 3
[1 2 3 4] 4 4
[1 2 3 4 5] 5 5
[1 2 3 4 5 6] 6 6
[1 2 3 4 5 6 7] 7 7
[1 2 3 4 5 6 7 8] 8 8
*/
}