当我开始学习map底层时,便思考一个问题,hash到底是什么?散列?数据结构?一种算法?
关于各语言中的map实现
go:笼统的来说,go的map底层是一个hash表,通过键值对进行映射。 键通过哈希函数生成哈希值,然后go底层的map数据结构就存储相应的hash值,进行索引,最终是在底层使用的数组存储key,和value。
c++:使用红黑树组织,性能稍低但是稳定性很好。使用模版在编译期生成代码,好处是效率高,但是缺点是代码膨胀、编译时间也会变长。
java:使用的是hash table+链表/红黑树,当bucket内元素超过某个阈值时,该bucket的链表会转换成红黑树。java为了所有map共用一份代码,规定了只有Object的子类才能使用作为map的key,缺点是基础数据类型必须使用object包装一下才能使用map。
go-map底层结构
// Go map的一个header结构
type hmap struct {
count int // map的大小. len()函数就取的这个值
flags uint8 //map状态标识
B uint8 // 可以最多容纳 6.5 * 2 ^ B 个元素,6.5为装载因子即:map长度=6.5*2^B
//B可以理解为buckets已扩容的次数
noverflow uint16 // 溢出buckets的数量
hash0 uint32 // hash 种子
buckets unsafe.Pointer //指向最大2^B个Buckets数组的指针. count==0时为nil.
oldbuckets unsafe.Pointer //指向扩容之前的buckets数组,并且容量是现在一半.不增长就为nil
nevacuate uintptr // 搬迁进度,小于nevacuate的已经搬迁
extra *mapextra // 可选字段,额外信息
}
//额外信息
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
//在编译期间会产生新的结构体,bucket
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
data byte[1] //key value数据:key/key/key/.../value/value/value...
overflow *bmap //溢出bucket的地址
}我们主要通过讲解hashmap的以下几点进行对其的简单剖析:
-
数据结构
-
扩容机制
-
查找&插入操作
-
hash冲突的解决方法
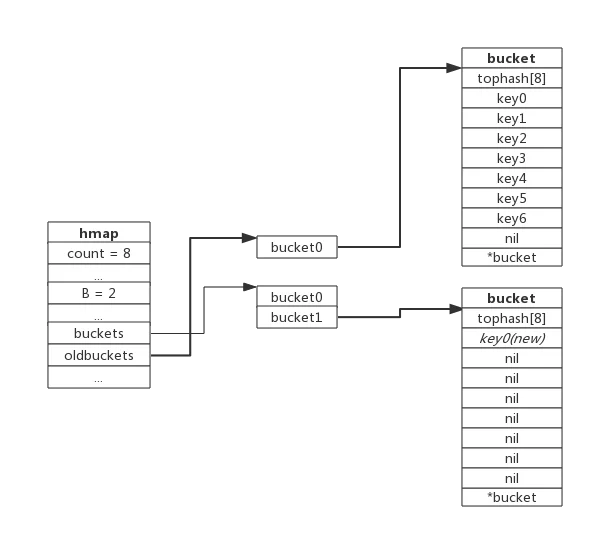
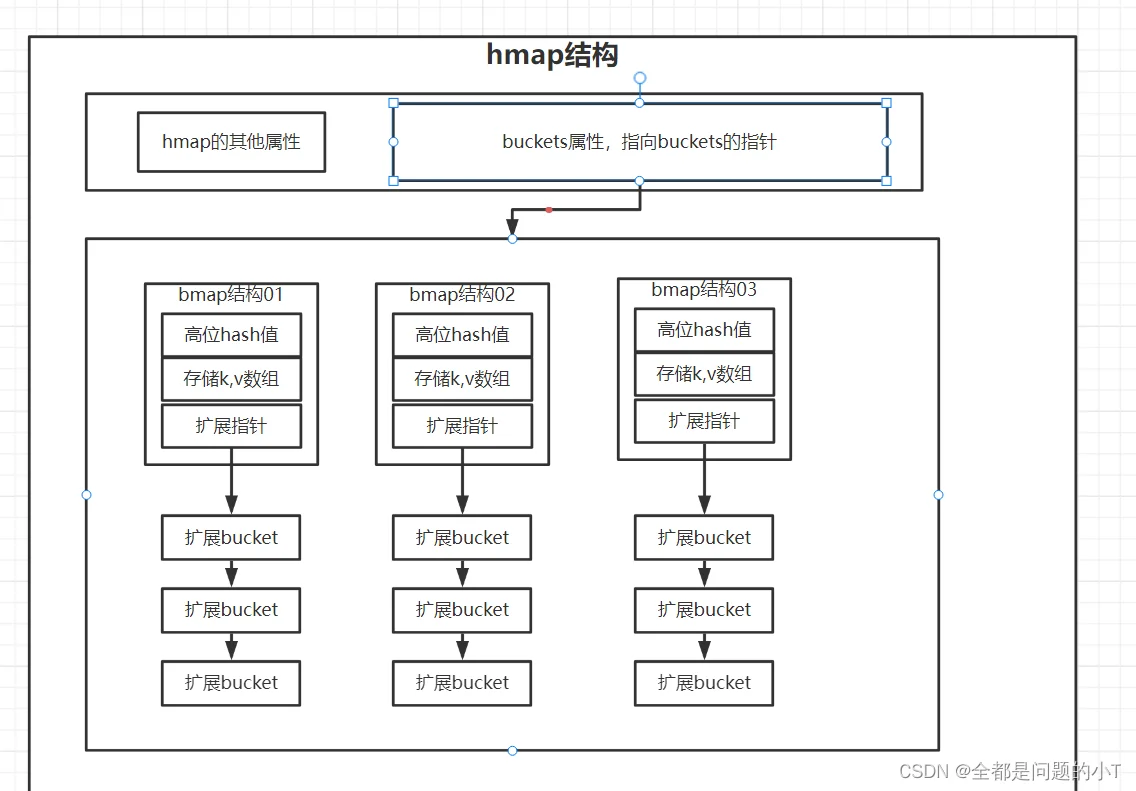
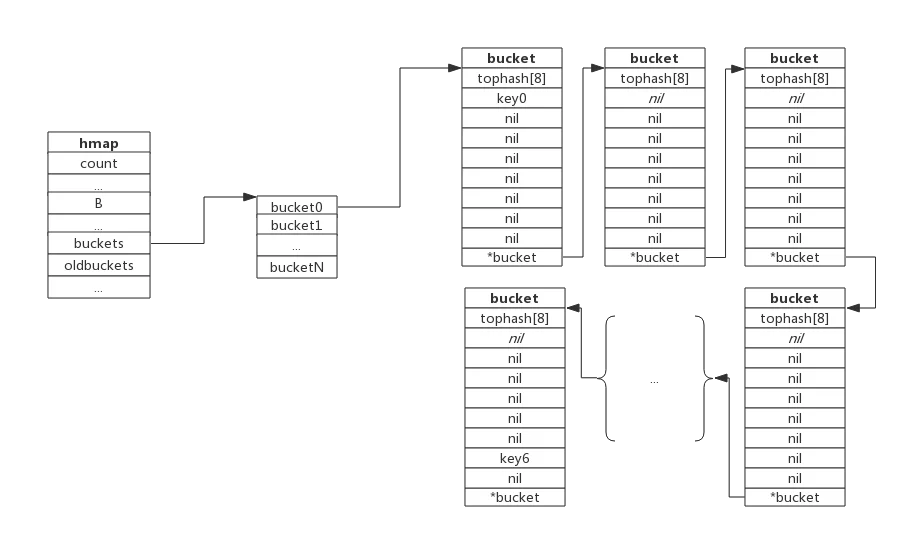
我们由上面源码可知,hmap中包含字段意义。其中最主要的buckets(hash桶)是map的存储结构
其中主要结构为:
hmap:
buckets中包含了哈希中最小细粒度单元bucket桶,数据通过hash函数均匀的分布在各个bucket中,buckets这个参数,它存储的是指向buckets数组的一个指针,当bucket(桶为0时)为nil。我们可以理解为,hmap指向了一个空bucket数组
bmap(bucket)
:bucket(桶),每一个bucket最多放8个key和value,最后由一个overflow字段指向下一个bmap,注意key、value、overflow字段都不显示定义,而是通过maptype计算偏移获取的。
- 它的tophash 存储的是哈希函数算出的哈希值的高八位。是用来加快索引的。因为把高八位存储起来,这样不用完整比较key就能过滤掉不符合的key,加快查询速度当一个哈希值的高8位和存储的高8位相符合,再去比较完整的key值,进而取出value。
- 第二部分,存储的是key 和value,就是我们传入的key和value,注意,它的底层排列方式是,key全部放在一起,value全部放在一起。当key大于128字节时,bucket的key字段存储的会是指针,指向key的实际内容;value也是一样。
- 这样排列好处是在key和value的长度不同的时候,可以消除padding带来的空间浪费。并且每个bucket最多存放8个键值对。
- 第三部分,存储的是当bucket溢出时,指向的下一个bucket的指针
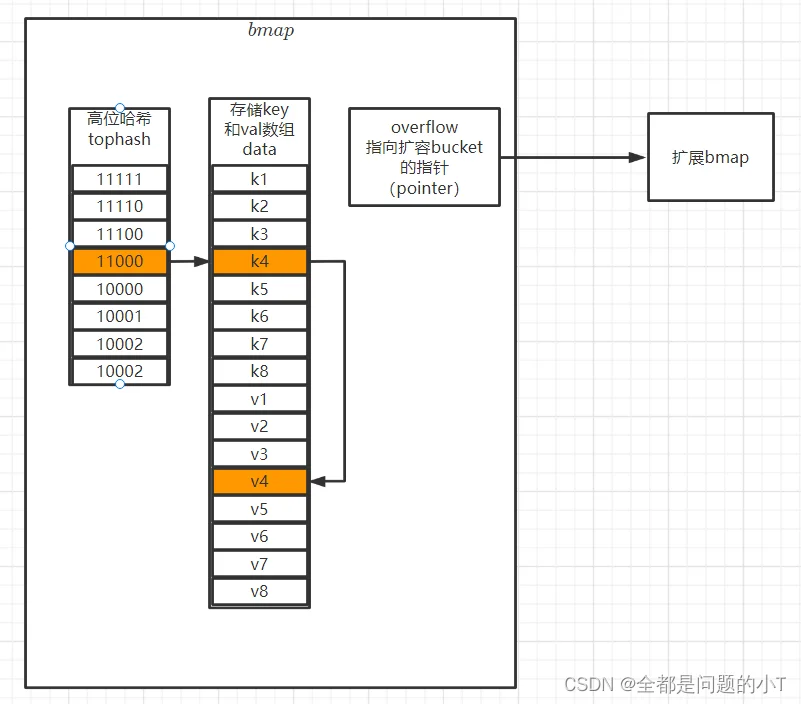
了解查找和插入过程,必须要先知道高位hash和低位hash值
哈希函数会将传入的key值进行哈希运算,得到一个唯一的值。
比如key1的hash值为:1123456789876543210 若将前八位hash值取出“11234567”部分就叫做“高位哈希值”。Go取后B位hash值为“低位hash值”
高位哈希值:是用来确定当前的bucket(桶)有没有所存储的数据的。
低位哈希值:是用来确定,当前的数据存在了哪个bucket(桶)
查找过程如下:
- 根据key值算出哈希值
- 取哈希值低位与hmap.B取模确定bucket位置
- 取哈希值高位在tophash数组中查询
- 如果tophash[i]中存储值也哈希值相等,则去找到该bucket中的key值进行比较
- 当前bucket没有找到,则继续从下个overflow的bucket中查找。
- 如果当前处于搬迁过程,则优先从oldbuckets查找
注:如果查找不到,也不会返回空值,而是返回相应类型的0值。
新元素插入过程如下:
- 根据key值算出哈希值
- 取哈希值低位与hmap.B取模确定bucket位置
- 查找该key是否已经存在,如果存在则直接更新值
- 如果没找到将key,将key插入
如图:1.算出hash值2.取高低位hash值
2.通过低位hash找到对应bucket桶,再通过高位hash找到对应key值(此处可能有hash冲突和扩容),
查找hahs冲突:若找到对应高位hash值,但key值不一致,则线性向下或通过扩展指针(数组到末尾了)查找key值。
插入hash冲突:先查找,若存在重复高位hash值,则线性向下寻空位插入。若当前kv数组已满,则扩展bucket,插入
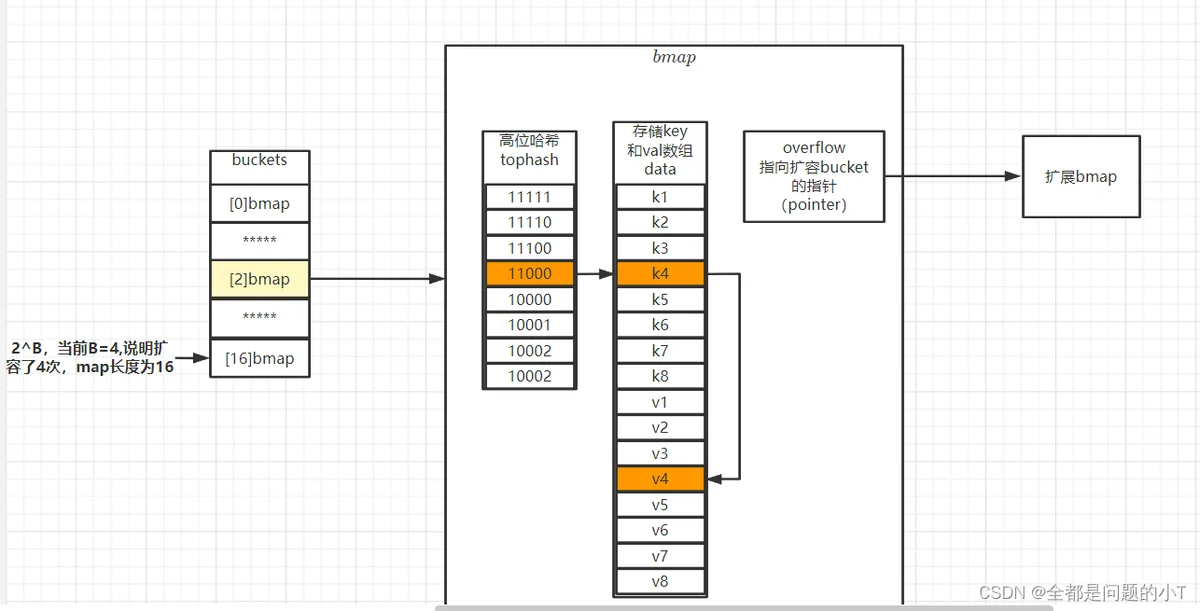
扩容的前提条件
为了保证访问效率,当新元素将要添加进map时,都会检查是否需要扩容,扩容实际上是以空间换时间的手段。
触发扩容的条件有二个:
- 负载因子 > 6.5时,也即平均每个bucket存储的键值对达到6.5个。
- 当溢出桶过多时:
- 当 B < 15 时,如果overflow的bucket数量超过 2^B。
- 当 B >= 15 时,overflow的bucket数量超过 2^15。
简单来讲,新加入key的hash值后B位都一样,使得个别桶一直在插入新数据,进而导致它的溢出桶链条越来越长。如此一来,当map在操作数据时,扫描速度就会变得很慢。及时的扩容,可以对这些元素进行重排,使元素在桶的位置更平均一些。
等量扩容
由于map中不断的put和delete key,桶中可能会出现很多断断续续的空位,这些空位会导致连接的bmap溢出桶很长,导致扫描时间边长。这种扩容实际上是一种整理,把后置位的数据整理到前面。这种情况下,元素会发生重排,但不会换桶。
增量扩容
这种2倍扩容是由于当前桶数组确实不够用了,发生这种扩容时,元素会重排,可能会发生桶迁移。
当负载因子过大时,就新建一个bucket,新的bucket长度是原来的2倍,然后旧bucket数据搬迁到新的bucket。
考虑到如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,Go采用逐步搬迁策略,即每次访问map时都会触发一次搬迁,每次搬迁2个键值对。
本B=0,其溢出桶上限也为2^0 =1,触发条件进行buckets扩容,则根据后B位hash值进行元素重排