
函数调用栈
代码段callret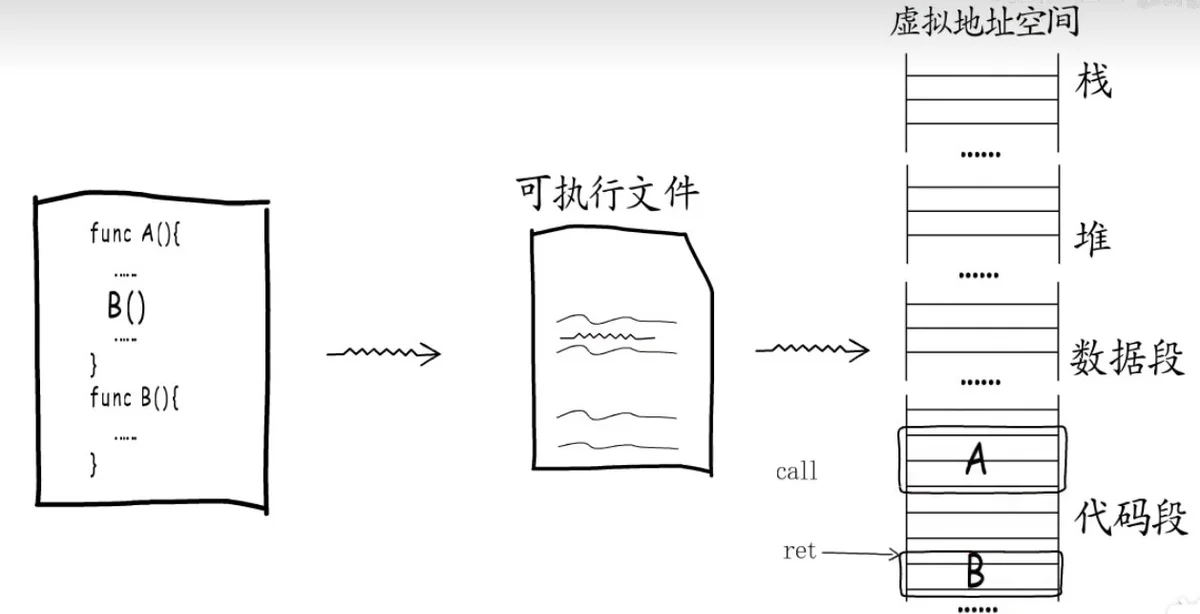
栈区
函数执行的时候需要有足够的内存空间来存放局部变量,参数,返回值等数据,这些数据存在上图中的栈中。
栈先入后出,先入栈的在底部。
虚拟地址空间的栈区,上面是高地址,下面是低地址,栈底通常称为栈基,栈顶又叫栈指针。
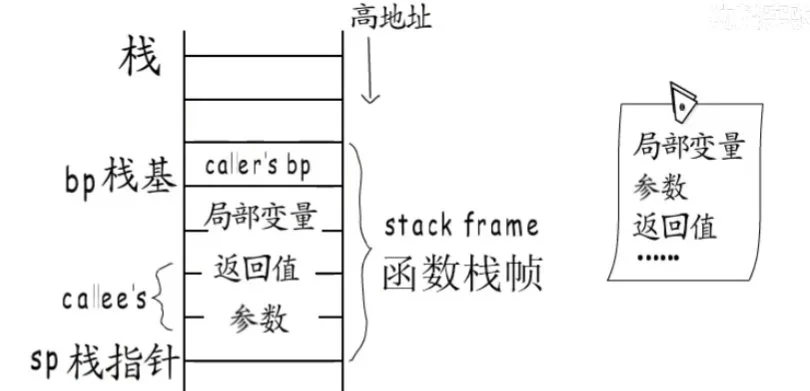
具体的栈帧布局是:
调用者栈基地址(也就是谁调用了这个函数)
局部变量
调用函数的返回值
参数
通过栈指针加上偏移来定位到每个参数和返回值。
比如栈指针+8字节处,就是栈指针的上一格,通过这种方式来进行偏移。
callcallcall- 首先把A函数中下一条指令的地址入栈(栈基地址,当B函数执行完之后,可以再通过这个地址回到A函数的调用处继续执行A函数。)
- 跳转到被调用函数的入口处执行(也就是被调用函数的栈帧,而所有的函数栈帧布局都遵循统一的结构约定。)

入栈策略
程序执行时,CPU通过特定的寄存器来存运行时的栈基和栈指针,也有指令指针寄存器用来存储下一条要执行的指令地址。
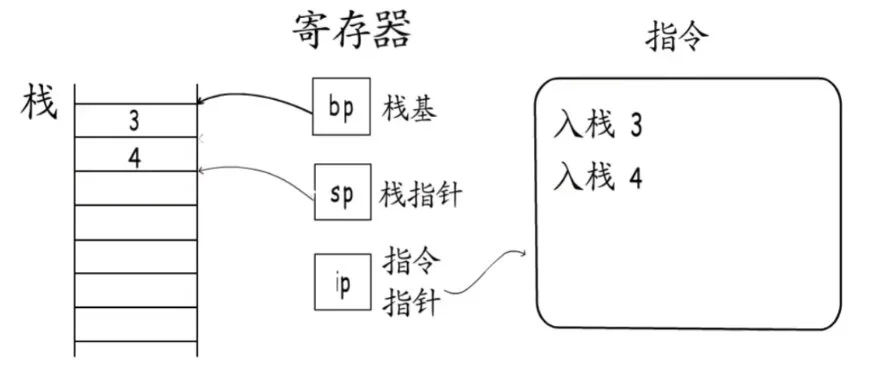
执行指令的过程有两种,第一种是逐步扩张:
逐步扩张
- 如果要执行入栈3这条指令,CPU读取之后,会先把指令指针移向下一条指令,然后栈指针向下移动,入栈数字3。
- 然后再执行入栈4这条指令,CPU读取之后,再把指令指针移向下一条指令,然后栈指针向下移动,入栈数字4。
- 一直往复。
一次性分配
一次性分配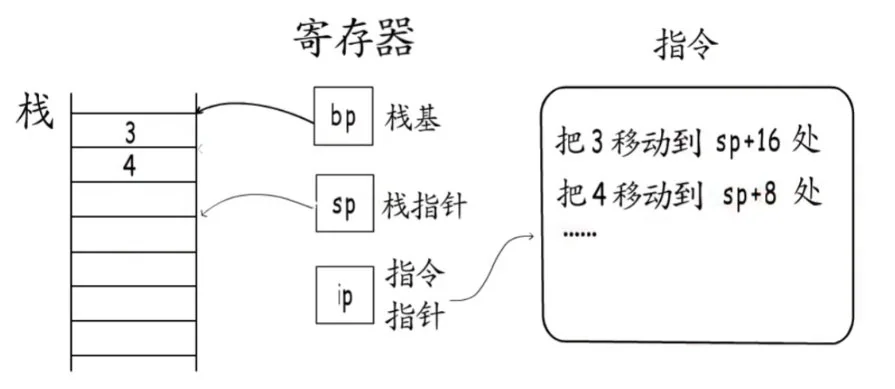
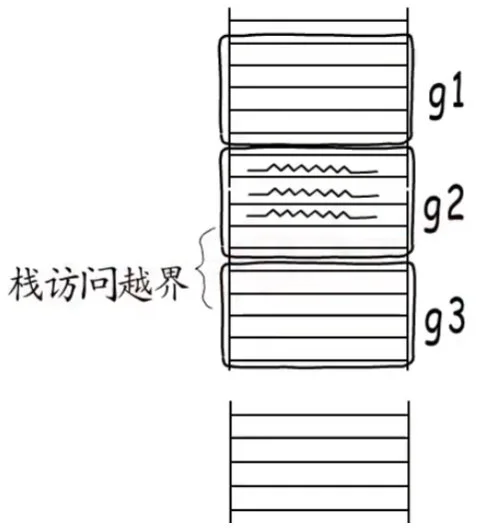
Go语言选择使用一次性分配的策略是有原因的,拿下图来讲,下面三个goroutine,初始分配的栈空间只有那么大,如果要逐步扩张的话,如果g2执行到最后了,但是接下来要执行的函数又要用掉很多的空间,如果函数栈是逐步扩张的,执行时就可能会发生栈访问越界。
函数栈帧的大小可以在编译时期确定, 对于栈消耗大的函数,Go编译器会在函数头部插入检测代码,如果发现需要进行栈增长,则会另外分配一段足够大的空间,然后把原来的内容移过来,并释放原来的空间。
call和ret的细节
栈区代码段当代码段执行到对应的指令时,就会给栈中添加对应的元素,最终再把栈全部出栈。
假如说,我们是在函数A中的a1处调用函数B(函数B开始位置为b1)。
首先,在最开始的时候,寄存器在栈中的情况是这样的:
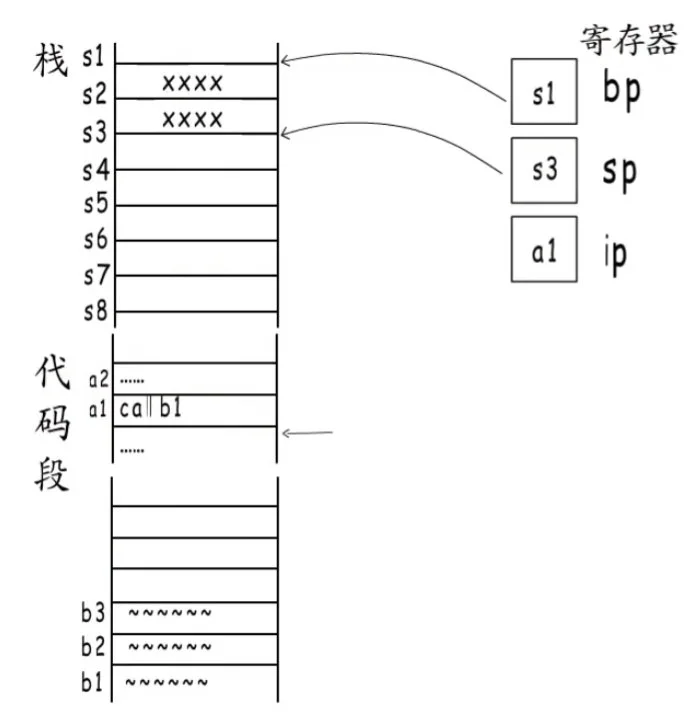
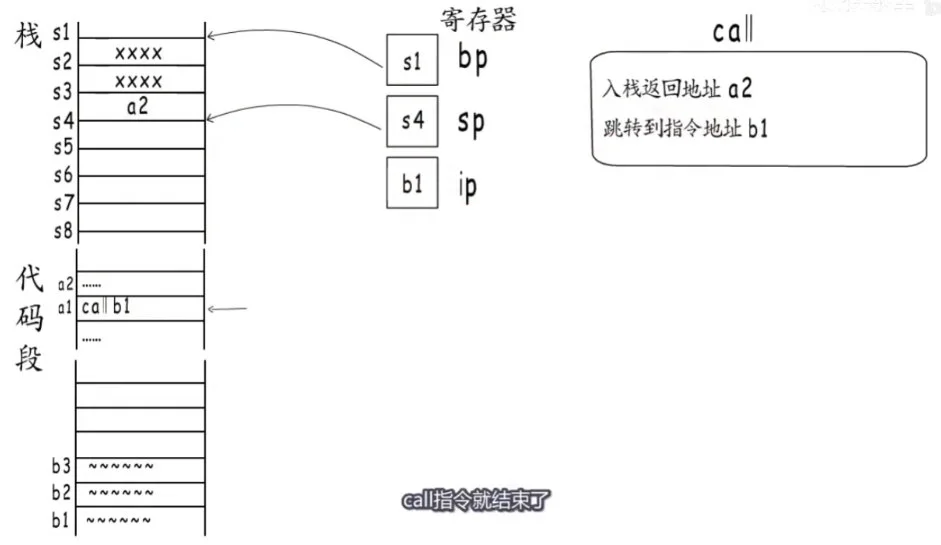
a1首先会入栈返回地址a2,然后栈指针sp向下一格,然后给ip寄存器b1的指令地址,接下来要去B函数的开始处运行。call指令就结束了。
接下来就要运行四步函数都要做的事:
s7bps5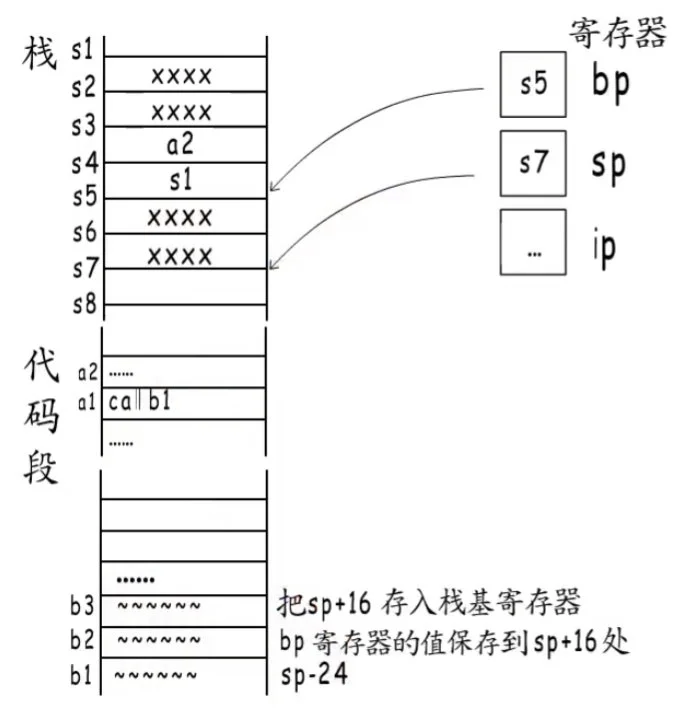
在函数B运行到最后——ret指令之前,编译器还会插入两条指令:
- 恢复调用者栈基。最开始我们分配了多少空间,此时就释放多少空间,修改bp寄存器为之前入栈的s1,bp继续指向s1处。
- 然后就到ret指令了,它首先会弹出call指令压栈的返回地址a2,sp赋值为s3。然后跳转到这个返回地址a2,把ip寄存器赋值为a2。 接下来可以从a2这里继续执行了。
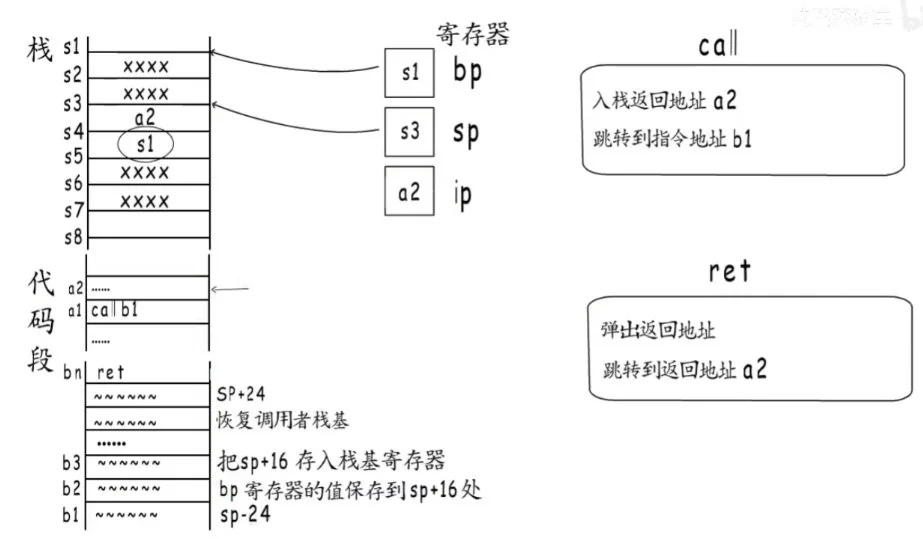
简单来说,call指令会分配栈帧,ret指令又会释放栈帧,恢复到call之前的样子。通过这些指令的配合,就能实现函数的层层嵌套了。
Reference
本站全部内容均为原创,欢迎转载,但请注明出处。