
导语 | 现代高级编程语言管理内存的方式分自动和手动两种。手动管理内存的典型代表是C和C++,编写代码过程中需要主动申请或者释放内存;而Java和Go等语言使用自动的内存管理系统,由内存分配器和垃圾收集器来代为分配和回收内存,开发者只需关注业务代码而无需关注底层内存分配和回收,虽然语言帮我们处理了这部分,但是还是有必要去了解一下底层的架构设计和执行逻辑,这样可以更好的掌握一门语言,本文主要以go内存管理为切入点再到go垃圾回收,系统地讲解了go自动内存管理系统的设计和原理。
之前发过一篇,对比JAVA和GO GC内幕,本文主要针对go的内存管理和gc,可以再次复习加深一下:
go内存管理是借鉴了TCMalloc的设计思想,TCMalloc全称Thead-Caching Malloc,是google开发的内存分配器,为了方便理解下面的go内存管理,有必要要先熟悉一下TCMalloc。
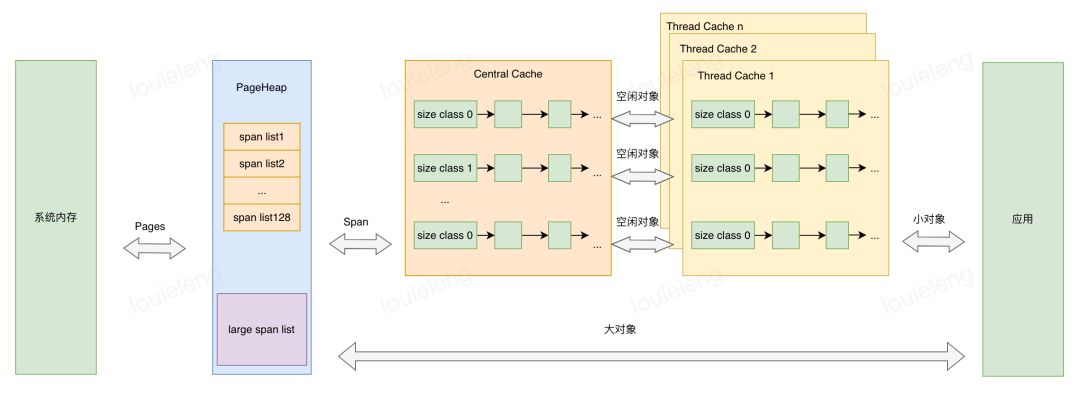
(一)Page
操作系统对内存管理以页为单位,TCMalloc也是这样,只不过TCMalloc里的Page大小与操作系统里的大小并不一定相等,而是倍数关系。
(二) Span
一组连续的Page被称为Span,比如可以有4个页大小的Span,也可以有8个页大小的Span,Span比Page高一个层级,是为了方便管理一定大小的内存区域,Span是TCMalloc中内存管理的基本单位。
(三) ThreadCache
每个线程各自的Cache,一个Cache包含多个空闲内存块链表,每个链表连接的都是内存块,同一个链表上内存块的大小是相同的,也可以说按内存块大小,给内存块分了个类,这样可以根据申请的内存大小,快速从合适的链表选择空闲内存块。由于每个线程有自己的ThreadCache,所以ThreadCache访问是无锁的。
(四)CentralCache
是所有线程共享的缓存,也是保存的空闲内存块链表,链表的数量与ThreadCache中链表数量相同,当ThreadCache内存块不足时,可以从CentralCache取,当ThreadCache内存块多时,可以放回CentralCache。由于CentralCache是共享的,所以它的访问是要加锁的。
(五)PageHeap
PageHeap是堆内存的抽象,PageHeap存的也是若干链表,链表保存的是Span,当CentralCache没有内存的时,会从PageHeap取,把1个Span拆成若干内存块,添加到对应大小的链表中,当CentralCache内存多的时候,会放回PageHeap。
(六)TCMalloc对象分配
小对象直接从ThreadCache分配,若ThreadCache不够则从CentralCache中获取内存,CentralCache内存不够时会再从PageHeap获取内存,大对象在PageHeap中选择合适的页组成span用于存储数据。
经过上一节对TCMalloc内存管理的描述,对接下来理解go的内存管理会有大致架构的熟悉,go内存管理架构取之TCMalloc不过在细节上有些出入,先来看一张go内存管理的架构图:
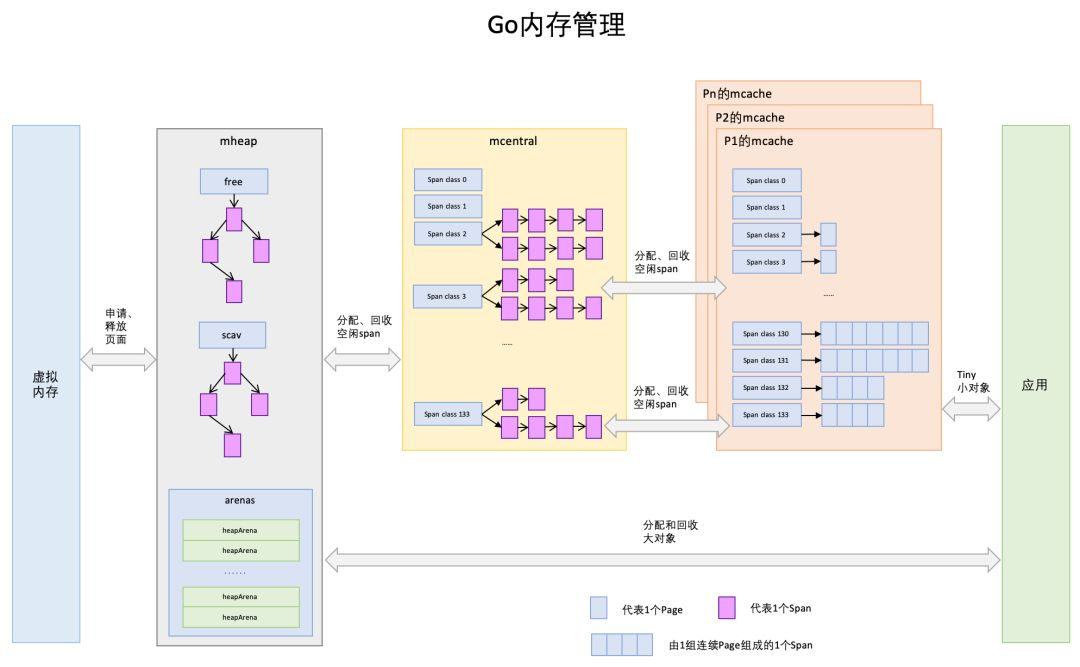
(一)Page
和TCMalloc中page相同,上图中最下方浅蓝色长方形代表一个page。
(二)Span
与TCMalloc中的Span相同,Span是go内存管理的基本单位,代码中为mspan,一组连续的Page组成1个Span,所以上图一组连续的浅蓝色长方形代表的是一组Page组成的1个Span,另外,1个淡紫色长方形为1个Span。
(三)mcache
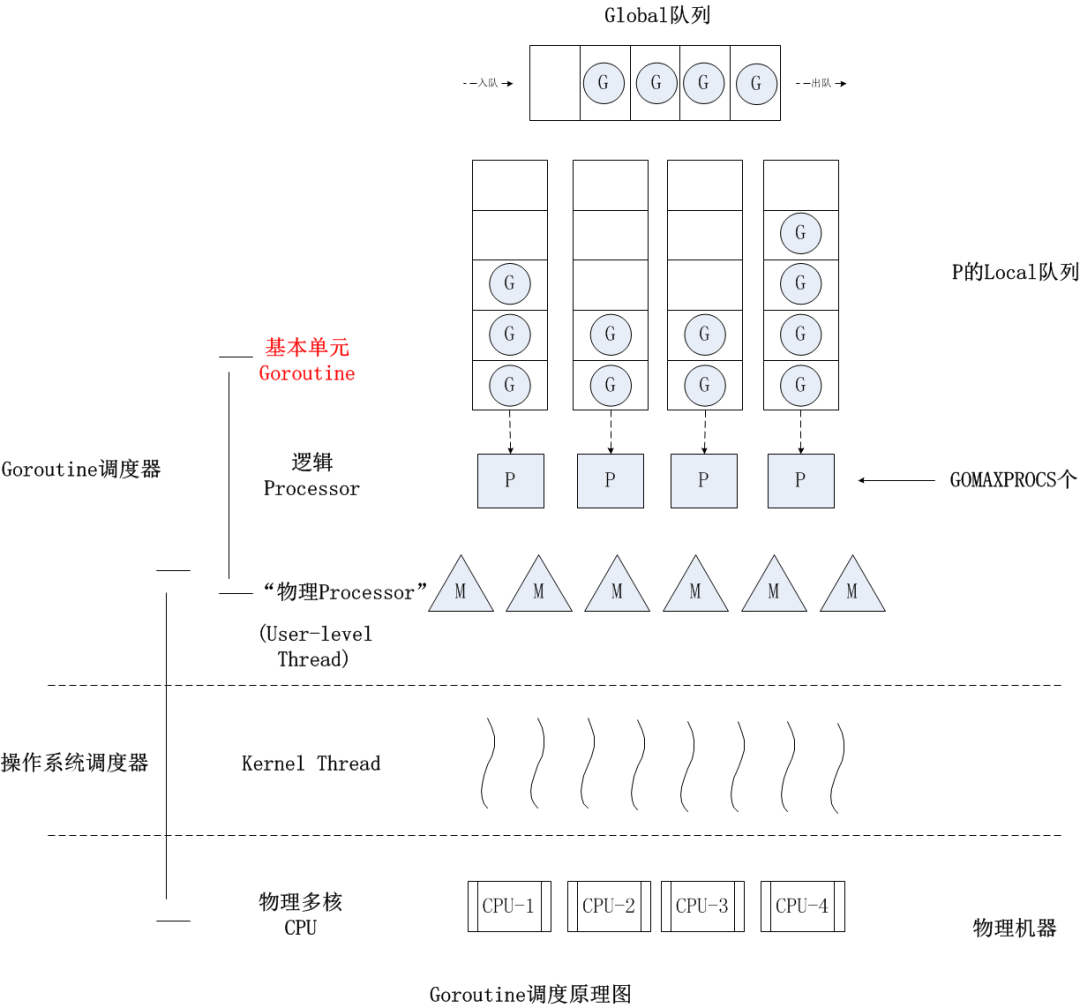
mcache与TCMalloc中的ThreadCache类似,mcache保存的是各种大小的Span,并按Span class分类,小对象直接从mcache分配内存,它起到了缓存的作用,并且可以无锁访问。但mcache与ThreadCache也有不同点,TCMalloc中是每个线程1个ThreadCache,Go中是每个P拥有1个mcach,因为在Go程序中,当前最多有GOMAXPROCS个线程在运行,所以最多需要GOMAXPROCS个mcache就可以保证各线程对mcache的无锁访问,下图是G,P,M三者之间的关系:
(四)mcentral
mcentral与TCMalloc中的CentralCache类似,是所有线程共享的缓存,需要加锁访问,它按Span class对Span分类,串联成链表,当mcache的某个级别Span的内存被分配光时,它会向mcentral申请1个当前级别的Span。但mcentral与CentralCache也有不同点,CentralCache是每个级别的Span有1个链表,mcache是每个级别的Span有2个链表。
(五)mheap
mheap与TCMalloc中的PageHeap类似,它是堆内存的抽象,把从OS(系统)申请出的内存页组织成Span,并保存起来。当mcentral的Span不够用时会向mheap申请,mheap的Span不够用时会向OS申请,向OS的内存申请是按页来的,然后把申请来的内存页生成Span组织起来,同样也是需要加锁访问的。但mheap与PageHeap也有不同点:mheap把Span组织成了树结构,而不是链表,并且还是2棵树,然后把Span分配到heapArena进行管理,它包含地址映射和span是否包含指针等位图,这样做的主要原因是为了更高效的利用内存:分配、回收和再利用。
(六)内存分配
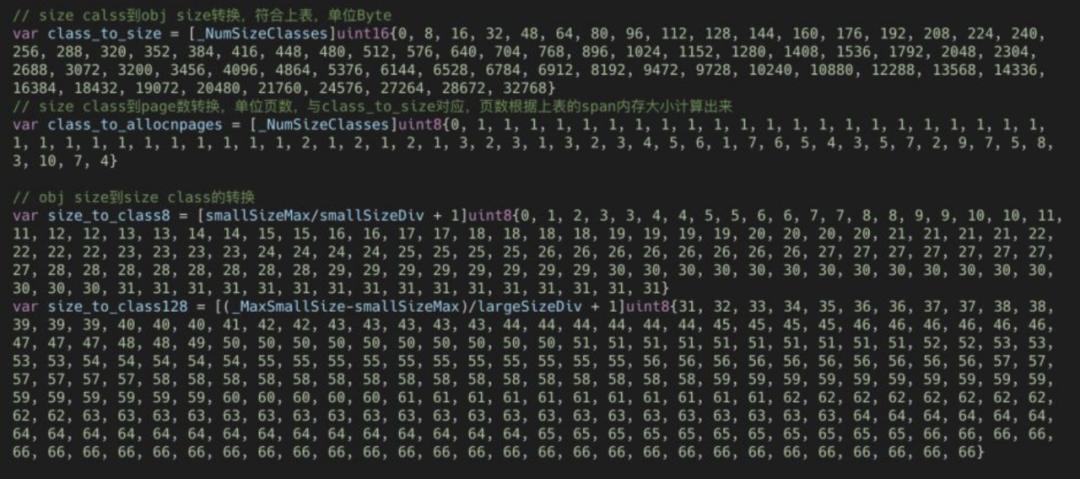
Go中的内存分类并不像TCMalloc那样分成小、中、大对象,但是它的小对象里又细分了一个Tiny对象,Tiny对象指大小在1Byte到16Byte之间并且不包含指针的对象。小对象和大对象只用大小划定,无其他区分,其中小对象大小在16Byte到32KB之间,大对象大小大于32KB。span规格分类 上面说到go的内存管理基本单位是span,且span有不同的规格,要想区分出不同的的span,我们必须要有一个标识,每个span通过spanclass标识属于哪种规格的span,golang的span规格一共有67种,具体如下:
//from runtime.gosizeclasses.go// class bytes/obj bytes/span objects tail waste max waste// 1 8 8192 1024 0 87.50%// 2 16 8192 512 0 43.75%// 3 32 8192 256 0 46.88%// 4 48 8192 170 32 31.52%// 5 64 8192 128 0 23.44%// 6 80 8192 102 32 19.07%// 7 96 8192 85 32 15.95%// 8 112 8192 73 16 13.56%// 9 128 8192 64 0 11.72%// 10 144 8192 56 128 11.82%// 11 160 8192 51 32 9.73%// 12 176 8192 46 96 9.59%// 13 192 8192 42 128 9.25%// 14 208 8192 39 80 8.12%// 15 224 8192 36 128 8.15%// 16 240 8192 34 32 6.62%// 17 256 8192 32 0 5.86%// 18 288 8192 28 128 12.16%// 19 320 8192 25 192 11.80%// 20 352 8192 23 96 9.88%// 21 384 8192 21 128 9.51%// 22 416 8192 19 288 10.71%// 23 448 8192 18 128 8.37%// 24 480 8192 17 32 6.82%// 25 512 8192 16 0 6.05%// 26 576 8192 14 128 12.33%// 27 640 8192 12 512 15.48%// 28 704 8192 11 448 13.93%// 29 768 8192 10 512 13.94%// 30 896 8192 9 128 15.52%// 31 1024 8192 8 0 12.40%// 32 1152 8192 7 128 12.41%// 33 1280 8192 6 512 15.55%// 34 1408 16384 11 896 14.00%// 35 1536 8192 5 512 14.00%// 36 1792 16384 9 256 15.57%// 37 2048 8192 4 0 12.45%// 38 2304 16384 7 256 12.46%// 39 2688 8192 3 128 15.59%// 40 3072 24576 8 0 12.47%// 41 3200 16384 5 384 6.22%// 42 3456 24576 7 384 8.83%// 43 4096 8192 2 0 15.60%// 44 4864 24576 5 256 16.65%// 45 5376 16384 3 256 10.92%// 46 6144 24576 4 0 12.48%// 47 6528 32768 5 128 6.23%// 48 6784 40960 6 256 4.36%// 49 6912 49152 7 768 3.37%// 50 8192 8192 1 0 15.61%// 51 9472 57344 6 512 14.28%// 52 9728 49152 5 512 3.64%// 53 10240 40960 4 0 4.99%// 54 10880 32768 3 128 6.24%// 55 12288 24576 2 0 11.45%// 56 13568 40960 3 256 9.99%// 57 14336 57344 4 0 5.35%// 58 16384 16384 1 0 12.49%// 59 18432 73728 4 0 11.11%// 60 19072 57344 3 128 3.57%// 61 20480 40960 2 0 6.87%// 62 21760 65536 3 256 6.25%// 63 24576 24576 1 0 11.45%// 64 27264 81920 3 128 10.00%// 65 28672 57344 2 0 4.91%// 66 32768 32768 1 0 12.50%
由上表可见最大的对象是32KB大小,超过32KB大小的由特殊的class表示,该class ID为0,每个class只包含一个对象。所以上面只有列出了1-66。内存大小转换,下面还要三个数组,分别是:class_to_size,size_to_class和class_to_allocnpages3个数组,对应下图上的3个箭头:
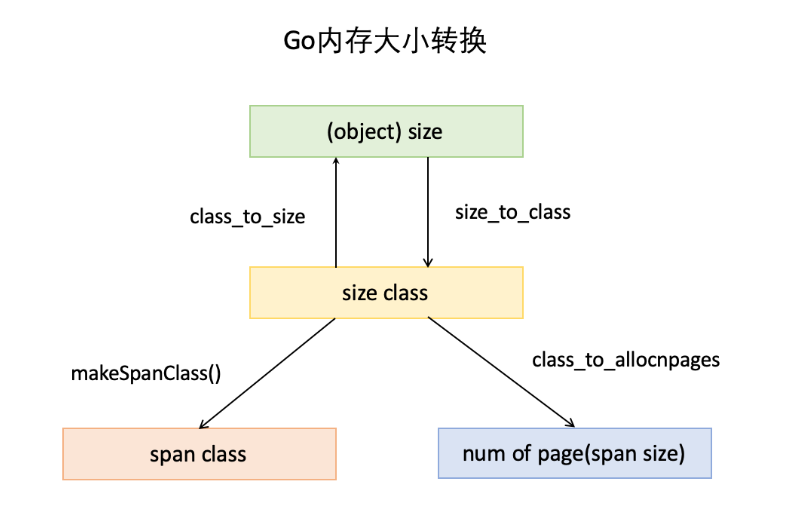
以第一列为例,类别1的对象大小是8bytes,所以class_to_size[1]=8;span大小是8KB,为1页,所以class_to_allocnpages[1]=1,下图是go源码中大小转换数组。
为对象寻找span,寻找span的流程如下:
-
计算对象所需内存大小size。
-
根据size到size class映射,计算出所需的size class。
-
根据size class和对象是否包含指针计算出span class。
-
获取该span class指向的span。
以分配一个包含指针大小为20Byte的对象为例,根据映射表:
// class bytes/obj bytes/span objects tail waste max waste// 1 8 8192 1024 0 87.50%// 2 16 8192 512 0 43.75%// 3 32 8192 256 0 46.88%
size class 3,它的对象大小范围是(16,32]Byte,20Byte刚好在此区间,所以此对象的size class为3,Size class到span class的计算如下:
// noscan为false代表对象包含指针func makeSpanClass(sizeclass uint8, noscan bool) spanClass {return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))}
所以,对应的span class为:
span class = 3 << 1 | 0 = 6所以该对象需要的是span class 7指向的span,自此,小对象内存分配完成。
//from runtime.gomalloc.govar sizeclass uint8//step1: 确定规格sizeClassif size <= smallSizeMax-8 {sizeclass = size_to_class8[divRoundUp(size, smallSizeDiv)]} else {sizeclass = size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]}size = uintptr(class_to_size[sizeclass])// size class到span classspc := makeSpanClass(sizeclass, noscan)//step2: 分配对应spanClass 的 spanspan = c.alloc[spc]v := nextFreeFast(span)if v == 0 {v, span, shouldhelpgc = c.nextFree(spc)}x = unsafe.Pointer(v)if needzero && span.needzero != 0 {memclrNoHeapPointers(unsafe.Pointer(v), size)}
大对象(>32KB)的分配则简单多了,直接在mheap上进行分配,首先计算出需要的内存页数和span class级别,然后优先从free中搜索可用的span,如果没有找到,会从scav中搜索可用的span,如果还没有找到,则向OS申请内存,再重新搜索2棵树,必然能找到span。如果找到的span比需求的span大,则把span进行分割成2个span,其中1个刚好是需求大小,把剩下的span再加入到free中去。
(一)标记-清除
标记-清除算法是第一种自动内存管理,基于追踪的垃圾收集算法。算法思想在70年代就提出了,是一种非常古老的算法。内存单元并不会在变成垃圾立刻回收,而是保持不可达状态,直到到达某个阈值或者固定时间长度。这个时候系统会挂起用户程序,也就是STW,转而执行垃圾回收程序。垃圾回收程序对所有的存活单元进行一次全局遍历确定哪些单元可以回收。算法分两个部分:标记(mark)和清除(sweep)。标记阶段表明所有的存活单元,清扫阶段将垃圾单元回收。可视化可以参考下图。
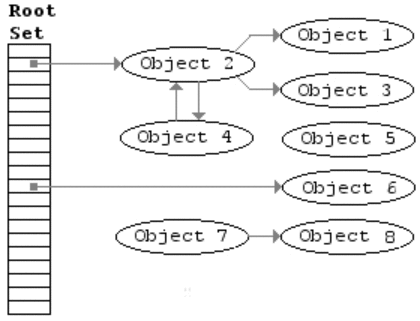
标记-清除算法的优点也就是基于追踪的垃圾回收算法具有的优点:避免了引用计数算法的缺点(不能处理循环引用,需要维护指针)。缺点也很明显,需要STW。
(二)三色可达性分析
三色标记算法是对标记阶段的改进,原理如下:
-
起初所有对象都是白色。
-
从根出发扫描所有可达对象,标记为灰色,放入待处理队列。
-
从队列取出灰色对象,将其引用对象标记为灰色放入队列,自身标记为黑色。
-
重复上一步,直到灰色对象队列为空。此时白色对象即为垃圾,进行回收。
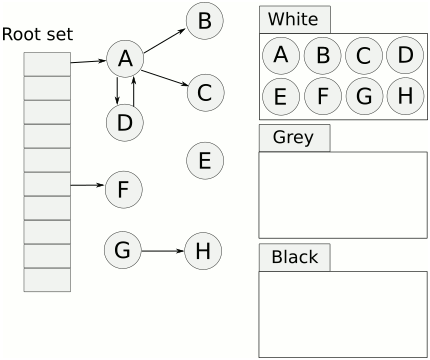
三色标记的一个明显好处是能够让用户程序和mark并发的进行,不过三色标记清除算法本身是不可以并发或者增量执行的,它需要STW,而如果并发执行,用户程序可能在标记执行的过程中修改对象的指针,导致可能将本该死亡的对象标记为存活和本该存活的对象标记为死亡,为了解决这种问题,go v1.8之后使用混合写屏障技术支持并发和增量执行,将垃圾收集的时间缩短至0.5ms以内。
(三)gc触发
在堆上分配大于32K byte对象的时候进行检测此时是否满足垃圾回收条件,如果满足则进行垃圾回收
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {...shouldhelpgc := false// 分配的对象小于 32K byteif size <= maxSmallSize {...} else {shouldhelpgc = true...}...// gcShouldStart() 函数进行触发条件检测if shouldhelpgc && gcShouldStart(false) {// gcStart() 函数进行垃圾回收gcStart(gcBackgroundMode, false)}}
上面是自动垃圾回收,还有一种主动垃圾回收,通过调用runtime.GC(),这是阻塞式的。
// GC runs a garbage collection and blocks the caller until the// garbage collection is complete. It may also block the entire// program.func GC() {gcStart(gcForceBlockMode, false)}
系统gc触发条件:触发条件主要关注下面代码中的中间部分:forceTrigger||memstats.heap_live>=memstats.gc_trigger。forceTrigger是forceGC的标志,后面半句的意思是当前堆上的活跃对象大于我们初始化时候设置的GC触发阈值,在malloc以及free的时候heap_live会一直进行更新。
// gcShouldStart returns true if the exit condition for the _GCoff// phase has been met. The exit condition should be tested when// allocating.//// If forceTrigger is true, it ignores the current heap size, but// checks all other conditions. In general this should be false.func gcShouldStart(forceTrigger bool) bool {return gcphase == _GCoff && (forceTrigger || memstats.heap_live >= memstats.gc_trigger) && memstats.enablegc && panicking == 0 && gcpercent >= 0}//初始化的时候设置 GC 的触发阈值func gcinit() {_ = setGCPercent(readgogc())memstats.gc_trigger = heapminimum...}// 启动的时候通过 GOGC 传递百分比 x// 触发阈值等于 x * defaultHeapMinimum (defaultHeapMinimum 默认是 4M)func readgogc() int32 {p := gogetenv("GOGC")if p == "off" {return -1}if n, ok := atoi32(p); ok {return n}return 100}
(四)gc过程
下列源码是基于go 1.8,由于源码过长,所以这里尽量只关注主流程
-
gcStart
// gcStart 是 GC 的入口函数,根据 gcMode 做处理。// 1. gcMode == gcBackgroundMode(后台运行,也就是并行), _GCoff -> _GCmark// 2. 否则 GCoff -> _GCmarktermination,这个时候就是主动 GCfunc gcStart(mode gcMode, forceTrigger bool) {...//在后台启动 mark workerif mode == gcBackgroundMode {gcBgMarkStartWorkers()}...// Stop The Worldsystemstack(stopTheWorldWithSema)...if mode == gcBackgroundMode {// GC 开始前的准备工作//处理设置 GCPhase,setGCPhase 还会 开始写屏障setGCPhase(_GCmark)gcBgMarkPrepare() // Must happen before assist enable.gcMarkRootPrepare()// Mark all active tinyalloc blocks. Since we're// allocating from these, they need to be black like// other allocations. The alternative is to blacken// the tiny block on every allocation from it, which// would slow down the tiny allocator.gcMarkTinyAllocs()// Start The Worldsystemstack(startTheWorldWithSema)} else {...}}
-
Mark
func gcStart(mode gcMode, forceTrigger bool) {...//在后台启动 mark workerif mode == gcBackgroundMode {gcBgMarkStartWorkers()}}func gcBgMarkStartWorkers() {// Background marking is performed by per-P G's. Ensure that// each P has a background GC G.for _, p := range &allp {if p == nil || p.status == _Pdead {break}if p.gcBgMarkWorker == 0 {go gcBgMarkWorker(p)notetsleepg(&work.bgMarkReady, -1)noteclear(&work.bgMarkReady)}}}// gcBgMarkWorker 是一直在后台运行的,大部分时候是休眠状态,通过 gcController 来调度func gcBgMarkWorker(_p_ *p) {for {// 将当前 goroutine 休眠,直到满足某些条件gopark(...)...// mark 过程systemstack(func() {// Mark our goroutine preemptible so its stack// can be scanned. This lets two mark workers// scan each other (otherwise, they would// deadlock). We must not modify anything on// the G stack. However, stack shrinking is// disabled for mark workers, so it is safe to// read from the G stack.casgstatus(gp, _Grunning, _Gwaiting)switch _p_.gcMarkWorkerMode {default:throw("gcBgMarkWorker: unexpected gcMarkWorkerMode")case gcMarkWorkerDedicatedMode:gcDrain(&_p_.gcw, gcDrainNoBlock|gcDrainFlushBgCredit)case gcMarkWorkerFractionalMode:gcDrain(&_p_.gcw, gcDrainUntilPreempt|gcDrainFlushBgCredit)case gcMarkWorkerIdleMode:gcDrain(&_p_.gcw, gcDrainIdle|gcDrainUntilPreempt|gcDrainFlushBgCredit)}casgstatus(gp, _Gwaiting, _Grunning)})...}}
Mark阶段的标记代码主要在函数gcDrain()中实现
// gcDrain scans roots and objects in work buffers, blackening grey// objects until all roots and work buffers have been drained.func gcDrain(gcw *gcWork, flags gcDrainFlags) {...// Drain root marking jobs.if work.markrootNext < work.markrootJobs {for !(preemptible && gp.preempt) {job := atomic.Xadd(&work.markrootNext, +1) - 1if job >= work.markrootJobs {break}markroot(gcw, job)if idle && pollWork() {goto done}}}// 处理 heap 标记// Drain heap marking jobs.for !(preemptible && gp.preempt) {...//从灰色列队中取出对象var b uintptrif blocking {b = gcw.get()} else {b = gcw.tryGetFast()if b == 0 {b = gcw.tryGet()}}if b == 0 {// work barrier reached or tryGet failed.break}//扫描灰色对象的引用对象,标记为灰色,入灰色队列scanobject(b, gcw)}}
-
Sweep
func gcSweep(mode gcMode) {...//阻塞式if !_ConcurrentSweep || mode == gcForceBlockMode {// Special case synchronous sweep....// Sweep all spans eagerly.for sweepone() != ^uintptr(0) {sweep.npausesweep++}// Do an additional mProf_GC, because all 'free' events are now real as well.mProf_GC()mProf_GC()return}// 并行式// Background sweep.lock(&sweep.lock)if sweep.parked {sweep.parked = falseready(sweep.g, 0, true)}unlock(&sweep.lock)}
对于并行式清扫,在GC初始化的时候就会启动 bgsweep(),然后在后台一直循环
func bgsweep(c chan int) {sweep.g = getg()lock(&sweep.lock)sweep.parked = truec <- 1goparkunlock(&sweep.lock, "GC sweep wait", traceEvGoBlock, 1)for {for gosweepone() != ^uintptr(0) {sweep.nbgsweep++Gosched()}lock(&sweep.lock)if !gosweepdone() {// This can happen if a GC runs between// gosweepone returning ^0 above// and the lock being acquired.unlock(&sweep.lock)continue}sweep.parked = truegoparkunlock(&sweep.lock, "GC sweep wait", traceEvGoBlock, 1)}}func gosweepone() uintptr {var ret uintptrsystemstack(func() {ret = sweepone()})return ret}
不管是阻塞式还是并行式,最终都会调用sweepone()。上面说过go内存管理都是基于span的,mheap_是一个全局的变量,所有分配的对象都会记录在mheap_中。在标记的时候,我们只要找到对对象对应的span进行标记,清扫的时候扫描span,没有标记的span就可以回收了。
// sweeps one span// returns number of pages returned to heap, or ^uintptr(0) if there is nothing to sweepfunc sweepone() uintptr {...for {s := mheap_.sweepSpans[1-sg/2%2].pop()...if !s.sweep(false) {// Span is still in-use, so this returned no// pages to the heap and the span needs to// move to the swept in-use list.npages = 0}}}// Sweep frees or collects finalizers for blocks not marked in the mark phase.// It clears the mark bits in preparation for the next GC round.// Returns true if the span was returned to heap.// If preserve=true, don't return it to heap nor relink in MCentral lists;// caller takes care of it.func (s *mspan) sweep(preserve bool) bool {...}
参考资料:
1.《go语言设计与实现》
文章来源于腾讯云开发者 ,作者冷易