
背景
先来了解一下缓存问题的几种场景,以redis为例
缓存穿透
缓存穿透,是指查询一个数据库一定不存在的数据。正常的使用缓存流程大致是,数据查询先进行缓存查询,如果key不存在或者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存。
代码流程
1.参数传入对象主键ID
2.根据key从缓存中获取对象
3.如果对象不为空,直接返回
4.如果对象为空,进行数据库查询
5.如果从数据库查询出的对象不为空,则放入缓存(设定过期时间)
想象一下这个情况,如果传入的参数为-1,会是怎么样?这个-1,就是一定不存在的对象。就会每次都去查询数据库,而每次查询都是空,每次又都不会进行缓存。假如有恶意攻击,就可以利用这个漏洞,对数据库造成压力,甚至压垮数据库。即便是采用UUID,也是很容易找到一个不存在的KEY,进行攻击。
小编在工作中,会采用缓存空值的方式,也就是【代码流程】中第5步,如果从数据库查询的对象为空,也放入缓存,只是设定的缓存过期时间较短,比如设置为60秒。
缓存雪崩
缓存雪崩,是指在某一个时间段,缓存集中过期失效。
产生雪崩的原因之一,比如在写本文的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。
比如电商项目,一般是采取不同分类商品,缓存不同周期。在同一分类中的商品,加上一个随机因子。这样能尽可能分散缓存过期时间,而且,热门类目的商品缓存时间长一些,冷门类目的商品缓存时间短一些,也能节省缓存服务的资源。
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,那么那个时候数据库能顶住压力,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。相当于电商项目中的“爆款”。
其实,大多数情况下这种爆款很难对数据库服务器造成压垮性的压力。达到这个级别的公司没有几家的。如果流量不大,务实一点就是直接设置缓存永不过期,即便某些商品自己发酵成了爆款,也是直接设为永不过期就好了。
但是万一流量很大,遇到这种缓存击穿怎么办,这个时候推荐一款golang的包singleflight
原理:
多个并发请求对一个失效的key进行源数据获取时,只让其中一个得到执行,其余阻塞等待到执行的那个请求完成后,将结果传递给阻塞的其他请求达到防止击穿的效果。
demo:
模拟一百个并发请求在缓存失效的瞬间同时调用rpc访问源数据
package backup
import (
"fmt"
"github.com/golang/groupcache/singleflight"
"net/http"
"net/rpc"
"sync"
"time"
)
type (
Arg struct {
Caller int
}
Data struct{}
)
// 模拟从数据源获取数据
func (d *Data) GetData(arg *Arg, replay *string) error {
fmt.Printf("request from client %d\n", arg.Caller)
time.Sleep(1 * time.Second)
*replay = "source data from rpcServer"
return nil
}
func main() {
d := new(Data)
rpc.Register(d)
rpc.HandleHTTP()
fmt.Println("start rpc server")
if err := http.ListenAndServe(":8976", nil); err != nil {
panic(err)
}
client, err := rpc.DialHTTP("tcp", ":8976")
if (err != nil) {
panic(err)
}
singleFlight := new(singleflight.Group)
wg := sync.WaitGroup{}
wg.Add(100)
//然后再模拟一百个并发请求在缓存失效的瞬间同时调用rpc访问源数据
for i := 0; i < 100; i++ {
fn := func() (interface{}, error) {
var replay string
err = client.Call("Data.GetData", Arg{Caller: i}, &replay)
//从数据源拿到数据后再更新缓存等
//...
//...
return replay, err
}
go func(i int) {
result, _ := singleFlight.Do("foo", fn)
fmt.Printf("caller %d get result '%s'\n", i, result)
wg.Done()
}(i)
}
}
效果:
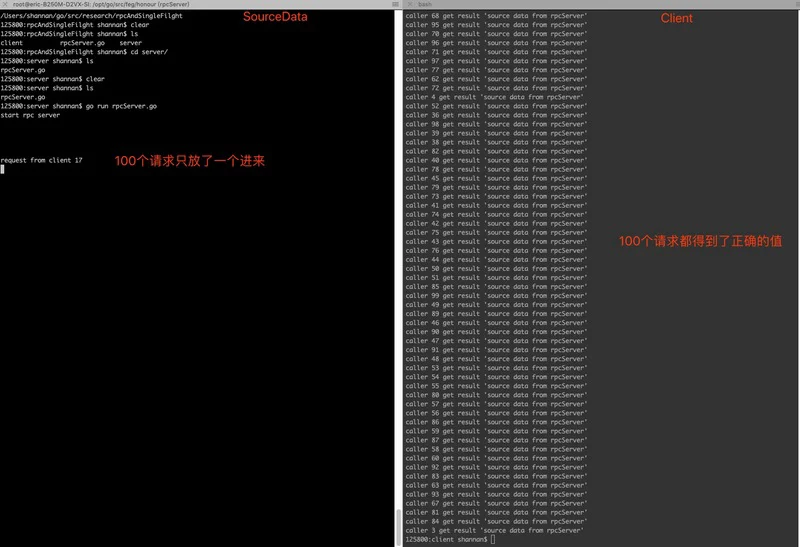
可以看到100个并发请求从源数据获取时,rpcServer端只收到了来自client 17的请求,而其余99个最后也都得到了正确的返回值。
其实singleflight就几十行代码,主要就用到sync包的两个特性Mutex和WaitGroup,所以说看优秀开源代码是学习最快的方式,没有之一。
package singleflight
import "sync"
// call is an in-flight or completed Do call
type call struct {
wg sync.WaitGroup
val interface{}
err error
}
// Group represents a class of work and forms a namespace in which
// units of work can be executed with duplicate suppression.
type Group struct {
mu sync.Mutex // protects m
m map[string]*call // lazily initialized
}
// Do executes and returns the results of the given function, making
// sure that only one execution is in-flight for a given key at a
// time. If a duplicate comes in, the duplicate caller waits for the
// original to complete and receives the same results.
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
if c, ok := g.m[key]; ok {
g.mu.Unlock()
c.wg.Wait()
return c.val, c.err
}
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
c.val, c.err = fn()
c.wg.Done()
g.mu.Lock()
delete(g.m, key)
g.mu.Unlock()
return c.val, c.err
}