
系统内核已经有一个thread scheduler,为什么golang还自己实现了一套runtime scheduler。主要有两个原因,一个是,线程的很多特性(比如context上下文切换的耗时,thread自己的信号掩码等)对go程序来说是累赘。另一个原因是go的垃圾回收需要所有的goroutine停止,使得内存存在一个一致的状态。垃圾回收的时间点是不明确的,如果依靠系统自身的scheduler来调度,那么会有大量的线程需要停止工作。
线程调度
背景知识
1.并行与并发:
并发: 指的是程序的逻辑结构。如果程序有多个独立并且可同时执行的逻辑控制流,那么这个程序就是并发的。这里的“同时“是指,把逻辑控制流画成时序流程图,它们在时间线上是可以重叠的。
并行: 并行是指程序的运行状态。如果一个程序在某一时刻被多个CPU流水线同时进行处理,那么我们就说这个程序是以并行的形式运行的。
举例说明
非并发的程序:入门程序——简单的hello world打印
并发的程序:多线程+入门程序——基于多线程的hello world打印,每个线程里打印一个hello world
注意 如果这个程序是在单核CPU上 ,那么这个是并发程序但还不是并行的;如果用多核多CPU且支持多任务的操作系统 来执行,那么这个并发程序就是并行的。
2.段寄存器和指针寄存器
关于段寄存器和指针寄存器如果已经有所了解,可以直接跳过。
段寄存器:
- CS 代码段,或代码选择器。同IP寄存器(稍后介绍)一同指向当前正在执行的那个地址。处理器执行时从这个寄存器指向的段(实模式)或内存(保护模式)中获取指令。除了跳转或其他分支指令之外,你无法修改这个寄存器的内容。
- DS 数据段,或数据选择器。这个寄存器的低16 bit连同ESI一同指向的指令将要处理的内存。同时,所有的内存操作指令 默认情况下都用它指定操作段(实模式)或内存(作为选择器,在保护模式。这个寄存器可以被装入任意数值,然而在这么做的时候需要小心一些。方法是,首先把数据送给AX,然后再把它从AX传送给DS(当然,也可以通过堆栈来做).
- ES 附加段,或附加选择器。这个寄存器的低16 bit连同EDI一同指向的指令将要处理的内存。同样的,这个寄存器可以被装入任意数值,方法和DS类似。
- FS F段或F选择器(推测F可能是Free?)。可以用这个寄存器作为默认段寄存器或选择器的一个替代品。它可以被装入任何数值,方法和DS类似。
- GS G段或G选择器(G的意义和F一样,没有在Intel的文档中解释)。它和FS几乎完全一样。
- SS 堆栈段或堆栈选择器。这个寄存器的低16 bit连同ESP一同指向下一次堆栈操作(push和pop)所要使用的堆栈地址。这个寄存器也可以被装入任意数值,你可以通过入栈和出栈操作来给他赋值,不过由于堆栈对于很多操作有很重要的意义,因此,不正确的修改有可能造成对堆栈的破坏。
指针寄存器:
EIP 这个寄存器非常的重要。这是一个32位宽的寄存器 ,同CS一同指向即将执行的那条指令的地址。不能够直接修改这个寄存器的值,修改它的唯一方法是跳转或分支指令。(CS是默认的段或选择器)
线程的调度
线程是并发实现的一种方式,此处主要介绍操作系统如何让多个线程并发的执行(在多CPU的时候,就是并行执行)。线程是操作系统对外提供的服务方式之一,应用程序可以通过系统调用让操作系统启动线程,并负责随后的线程调度和切换。
结合上文提及的段寄存和指针寄存器,我们知道CPU通过CS:EIP寄存器的值确定下一条指针的位置,必须通过JMP系列指令、CALL/RET指令、或INT中断指令来实现代码的跳转,在指令序列间切换的时候,除了更改EIP之外,必须保证代码可能会使用到的各个寄存器的值,尤其是栈指针SS:EIP,以及EFLAGS标志位等,都能够恢复到目标指令序列上次执行到这个位置时候的状态。
1.单个单核CPU
操作系统和应用程序共享同一个CPU,当EIP在应用程序代码段的时候,内核没有控制权,内核只是以实模式运行的,代码段权限位RING 0的内存程序 ,只有当产生中断或是应用程序调用系统调用的时候,控制权才转移到内核,在内核里,所有代码都在同一个地址空间,为了给不同的线程提供服务,内核会为每一个线程建立一个内核堆栈,这是线程切换的关键。通常,内核会在时钟中断里或系统调用返回前,对整个系统的线程进行调度,计算当前线程的剩余时间片,如果需要切换,就在“可运行”的线程队列里计算优先级,选出目标线程后,则保存当前线程的运行环境,并恢复目标线程的运行环境,其中最重要的上就是切换堆栈指针ESP,然后再把EIP指向目标线程上次被移出CPU时的指令 。
2.多个多核
目前常见的普通的PC和服务器通常包含多个CPU,每个CPU又有多个核,每个核又可以支持超线程,也就是逻辑处理器。每个逻辑处理器都有自己的一套完整的寄存器 ,其中包括CS:EIP和SS:ESP,从操作系统和应用的角度看,每个逻辑处理器都是一个单独的流水线。在多处理器的情况下,线程切换的原理和流程其实和单处理器是基本一致的,内核代码只有一份,当某个CPU上发生时钟中断或是系统调用时,该CPU的CS:EIP和控制权又回到了内核,内核根据调度策略结果进行线程切换。这个时候如果程序用线程实现了并发,那么操作系统可以使我们的程序在多个CPU上实现并行。
并发编程框架
理论上,我们可以不依赖操作系统和其提供的线程,在自己程序的代码段里定义多个片段,然后在我们自己程序里对其进行调度和切换(为了描述方便,接下来把“代码片段”称为“任务” )。和内核的实现类似,只是我们不需要考虑中断和系统调用,那么,我们程序本质上就是一个循环,这个循环本身就是schedule(),我们需要维护一个任务的列表,根据定义的策略,先进先出或是优先级等等,每次从列表里挑选出一个任务,然后恢复各个寄存器的值,并且JMP到该任务上次被暂停的地方,所有这些需要保存的信息都可以作为任务的属性,存放在任务列表里。
思路很简单,但仍有几个问题需要解决:
1.运行在用户态, 是没有中断或系统调用这用的机制来中断代码执行的,一旦schedule()代码把控制权交给任务代码,下次调度在什么时候开始?
- 不会发生,只能靠任务主动调用schedule(),才有机会执行下一次调度,此处任务不能像线程一样依赖内核调度从而毫无顾忌的执行,任务里一定要显示的调用schedule(),这就是所谓的协作式(cooperative)调度。
2.堆栈
- 和内核调度线程的原理一样,我们也需要为每个任务单独分配堆栈,并且把堆栈信息保存在任务属性里,在任务切换时也保存或恢复当前的SS:ESP 。任务堆栈的空间可以是在当前线程的栈上分配,也可以是在堆上分配,但通常是在堆上分配比较好:几乎没有大小或任务总数的限制、堆栈大小可以动态扩展,便于切换把任务切换到其他线程。
在多线程处理多任务的时候,需要考虑一下几个问题:
1.如果某个任务发起一个系统调用,譬如长时间等待IO,那当前线程就被内核放入等待调度队列,岂不是让其他任务没有机会执行?
- 在单线程的情况下,只有一个解决办法,就是使用非阻塞的IO系统调用,并让出CPU,然后在schedule()里统一进行轮询,有数据时切换回该fd对应的任务;效率略低的做法是不进行统一轮询,让各个任务在轮到自己执行时再次用非阻塞方式进行IO,直到有数据可用。
2.任务同步。生产者消费者模式,让消费者在数据还没有被生产出来的时候进入等待,并且在数据可用时触发消费者继续执行
struct chan {
bool ready,
int data
};
int read (struct chan *c) {
while (1) {
if (c->ready) {
c->ready = false;
return c->data;
} else {
schedule();
}
}
}
void write (struct chan *c, int i) {
while (1) {
if (c->ready) {
schedule();
} else {
c->data = i;
c->ready = true;
schedule(); // optional
return;
}
}
}在其他语言里,我们所谓的“任务”更多时候被称为“协程”,也就是Coroutine。譬如C++里最常用的是Boost.Coroutine;Java因为有一层字节码解释,比较麻烦,但也有支持协程的JVM补丁,或是动态修改字节码以支持协程的项目;PHP和Python的generator和yield其实已经是协程的支持,在此之上可以封装出更通用的协程接口和调度;另外还有原生支持协程的Erlang等,笔者不懂,就不说了,具体可参见Wikipedia的页面:http://en.wikipedia.org/wiki/Coroutine
goroutine调度的理解
go的调度器内部有三个重要的结构:M, P,G
M : 代表真正的内核OS线程,和POSIX规定的thread差不多。
G : 代表一个goroutine, 它有自己的栈,指令指针和其他信息,用于调度。
P : 代表调度的上下文,可以把它看做一个局部的调度器,使go代码在一个线程上跑,它是实现从N:1到N:M映射的关键。
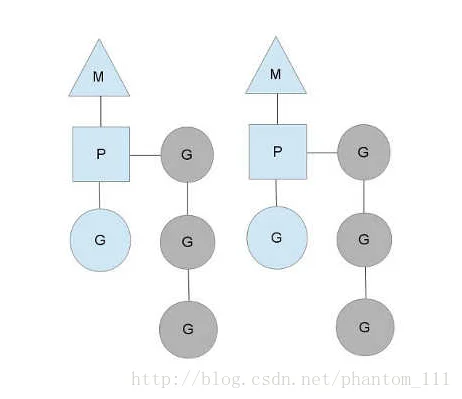
如上图所示,有2个物理线程M,每个M都拥有一个context(P),每个也都有一个正在运行的goroutine。图中灰色的那些goroutine并没有运行,而是处于ready的就绪态,等待被调度。P维护着这个队列(称为runqueue)。go语言里,启动一个goroutine很容易:go function就行,所以每有一个go语句被执行,runqueue队列就在其末位加入一个goroutine,在下一个调度点,就从runqueue取出一个goroutine执行。
注意: P的数量可以通过GOMAXPROCS()来设置,它其实代表真正的并发度,即有多少个goroutine可以同时运行。
为什么要维护多个上下P
- 因为当一个os线程被阻塞时,p可以转而投奔另一个os线程。如下图所示,当一个os线程M0陷入阻塞时,P转而在os线程M1上运行。调度器保证有足够的线程来运行所有的contenxt P(M1可能是创建或者从线程缓存总取出)。
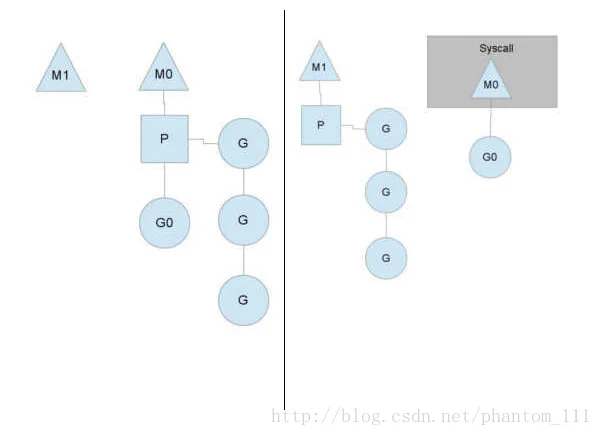
当M0返回时,它必须尝试取得一个context P来运行goroutine,一般情况下,它会从其他的os线程那里偷一个context过来。如果没有偷到的话,它就把goroutine放在一个global runqueue里,然后放入线程缓存里。contexts们也会周期性的检查global runqueue,否则global runqueue上的goroutine永远无法执行。
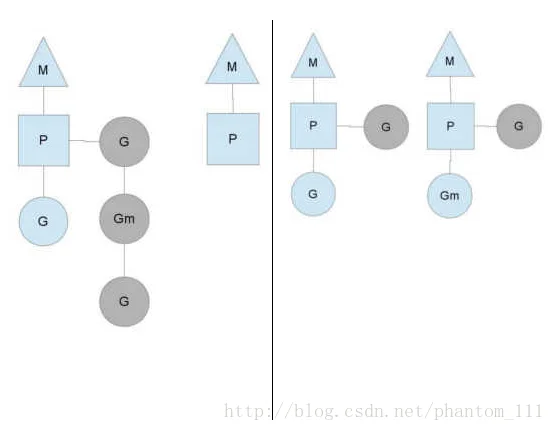
另一种情况是P所分配的任务G很快就执行完了(分配不均),这就导致一个上下文P闲着没事干而系统却仍然忙碌。但是如果global runqueue没有任务G了,那么P就不得不从其他的上下文P那里拿一些G来执行。一般来说,如果上下文P从其他的上下文P那里要偷一个任务的话,一般就是’偷’run queue的一半,这就确保了每个os线程都能充分使用。