
项目种需要统计用户昵称的字符数量进行限制,用户可以输入英文,中文,emoji 字符,当用户输入中英文和普通的 emoji 字符时,将字符串转为 []rune 进行统计没有问题。
func main() {
s0 := "我爱中国" // 中文
s1 := "我爱China" // 中英文
s2 := "我爱China😀" // 中英文加普通 emoji(笑脸)
fmt.Println(len([]rune(s0))) // 4
// 或 fmt.Println(utf8.RuneCountInString(s0))
fmt.Println(len([]rune(s1))) // 7
// 或 fmt.Println(utf8.RuneCountInString(s1))
fmt.Println(len([]rune(s2))) // 8
// fmt.Println(utf8.RuneCountInString(s2))
}
但是,当字符串种含有旗帜类的 emoji 字符,比如下面的中国旗帜,使用 []rune 无法准确统计字符数量。

func main() {
s := "我爱中国🇨🇳"
fmt.Println(len([]rune(s))) // 6
}
预期输出 5,结果输出了 6。
因为代码编辑器不支持旗帜 emoji,所以显示为 CN。
2.emoji 分类你可能以为一个 emoji 字符仅用一个 Unicode 码值表示,虽然大部分 emoji 是这样的,但实际上并非如此。
上面统计包含旗帜 emoji 字符串时,错误地将一个 emoji 字符统计成了两个字符,原因也是如此。
emoji 实际上有多种分类:
Basic_Emoji
Emoji_Keycap_Sequence
RGI_Emoji_Flag_Sequence
RGI_Emoji_Tag_Sequence
RGI_Emoji_Modifier_Sequence
RGI_Emoji_ZWJ_Sequence
2.1 Basic_Emoji
基本 emoji,对应 Emoji Sequences 标准书 Basic_Emoji 小节。
包含两种类型:
- 单一 unicode 字符
- 单一 unicode 字符后面增加 U+FE0E 或 U+FE0F 分别表示以黑白文本模式还是彩色模式展示表情
2.2 Emoji_Keycap_Sequence
键帽序列,对应 Emoji Sequences 标准书 Emoji_Keycap_Sequence 小节。
这一类序列总共有12组,这里其实就对应着电话上的12个按钮,分别是 0~9 十个字符,外加 # 和 * 开头,然后后面紧跟着 U+FE0F 和 U+20E3 两个字符组成。
字符长度:均是 Unicode 码值。
2.3 RGI_Emoji_Flag_Sequence
国家/地区旗帜序列。对应 Emoji Sequences 标准书 RGI_Emoji_Flag_Sequence 小节。
其中 RGI(Recommended for General Interchange)表示可以在日常的交流中使用。
这一组文字均由两个 unicode 字符组成,字符的值为 U+1F1E6 到 U+1F1FF 的26个字符,一一对应着 A 到 Z。这一组 unicode 文字对应着使用两个字母的国家/地区码所对应的国家/地区旗帜,以及用 UN 表示的联合国旗和 EU 表示的欧盟旗。
合法的旗帜总共有 258 个组合,标准中完整地列出了。需要注意的是,U+1F1E6 到 U+1F1FF 这26个字符不能单独出现,它们是专门用于这一类旗帜所使用的特殊 unicode 字符。
国家/地区码可参见 ISO 3166-1。
2.4 RGI_Emoji_Tag_Sequence
标记序列,对应 Emoji Sequences 标准书 RGI_Emoji_Tag_Sequence 小节。
这一组其实是 unicode 预留的扩展类别,虽然在 emoji 中定义了所谓 “tag latin letter” 用于此类别,但是目前只有三个合法 emoji,从展示效果上分别是 英格兰、苏格兰、威尔士旗帜。
英格兰(🏴):U+1F3F4 U+E0067 U+E0062 U+E0065 U+E006E U+E0067 U+E007F
苏格兰(🏴):U+1F3F4 U+E0067 U+E0062 U+E0073 U+E0063 U+E0074 U+E007F
威尔士(🏴):U+1F3F4 U+E0067 U+E0062 U+E0077 U+E006C U+E0073 U+E007F
2.5 RGI_Emoji_Modifier_Sequence
修饰符序列,对应 Emoji Sequences 标准书 RGI_Emoji_Modifier_Sequence 小节。
Unicode 定义了五个用于 emoji 的肤色字符,分别是:U+1F3FB U+1F3FC U+1F3FD U+1F3FE U+1F3FF,在 unicode 标准中分别表示:
light skin tone
medium-light skin tone
medium skin tone
medium-dark skin tone
dark skin tone
用于与部分基本 emoji 经字符搭配,用于调整相应文字中的肤色。常用在需要西方式 “政治正确” 的场合。
这五个字符按照标准而言是不会单独出现的,必然是跟在一个基本 emoji 后面。
Unicode 总共定义了 580 个 modifier sequences,也就是说有 116 个基本 emoji 字符可以搭配肤色字符使用。
2.6 RGI_Emoji_ZWJ_Sequence
零宽度连接符,对应 Emoji ZWJ Sequences 标准书。
ZWJ 即 Zero Width Joiner。ZWJ 的 unicode 码值为 U+200D,因为是没有宽度的连接符,所以不可见,它的作用就是连接两个字符,比如 “👨👩👧👦” 就是由 U+200D 连接四个 emoji 字符而成。
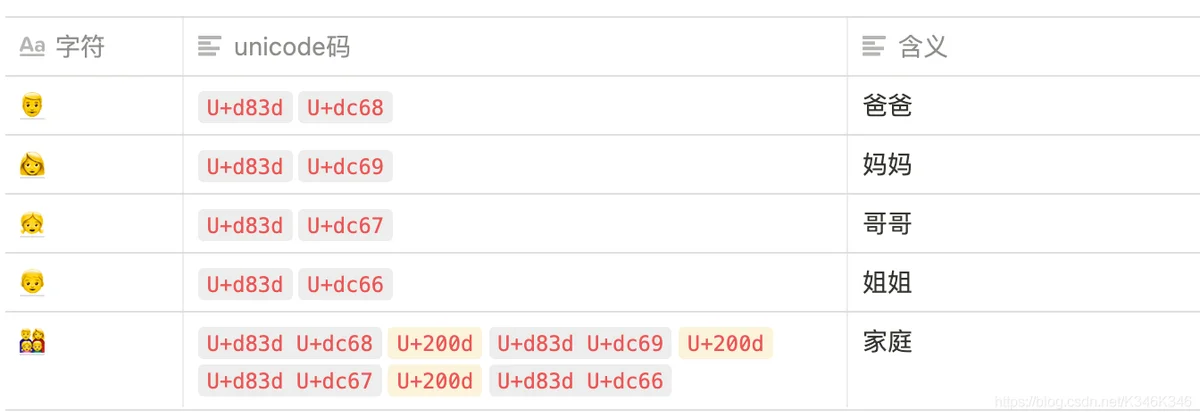
并不是所有的 emoji 都可以任意连接。Unicode 定义了 1122 个 Emoji ZWJ 序列类型的文字。在 Emoji ZWJ Sequences 标准书可以查阅完整列表。
几番搜索,终于发现开源包 uniseg 可以准确识别包含 emoji 字符的字符串的字符数量。它根据 Unicode Standard Annex #29中指定的规则来中断字符串。
使用示例:
package main
import (
"fmt"
"github.com/rivo/uniseg"
)
func main() {
s := "我爱中国🇨🇳"
fmt.Println(uniseg.GraphemeClusterCount(s))
}
运行输出:
5
utf8.RuneCountInString()len()因为 emoji 字符长度不固定,判断是否是 emoji 表情,不能简单按照 UTF8 编码规则来判断,而应该根据 Unicode 码值范围与连接顺序来判断是否为 emoji,可以使用开源库 uniseg 来准确获取包含 emoji 字符的字符串长度(字符数)。
参考文献
[1] EmojiXD
[2] go语言:彻底掌握emoji
[3] Unicode 颜文字(emoji)格式和 Go 代码处理
[4] emoji 标准书
[5] string - 计算golang字符串中的字符