
SDB:纯golang开发,分布式,丰富的数据结构,持久化,好用的NoSQL数据库
为什么需要 SDB?
考虑以下业务场景:
-
统计服务:统计内容的点赞、播放等数据
-
评论服务:发表评论后,查看某条内容的评论列表
-
推荐服务:每个用户都有一个推荐列表,有内容和权重
以上业务场景都可以通过 MySQL + Redis 来实现。
MySQL在这种场景下充当持久化能力,Redis提供读写
在线服务的能力。
上述存储要求是:持久性+高性能+丰富的数据结构。只可以
使用一个存储来满足上述场景?
答案是:很少。有些数据库要么支持的数据结构不够,要么数据
结构不够丰富,或者接入成本太高......
为了解决上述问题,创建了SDB。
SDB简介
-
纯golang开发,核心代码不超过1k,代码易读
-
丰富的数据结构
*字符串
*列表
*设置
*排序集
*布隆过滤器
*超级日志日志
*位集
*地图
*地理哈希
*发布子
-
Persistence - 使用pebble、leveldb、badger存储引擎
-
监视器
-
支持prometheus + grafana 监控方案
-
cli
-
易于使用cli
-
分布式
-
基于raft实现主从架构
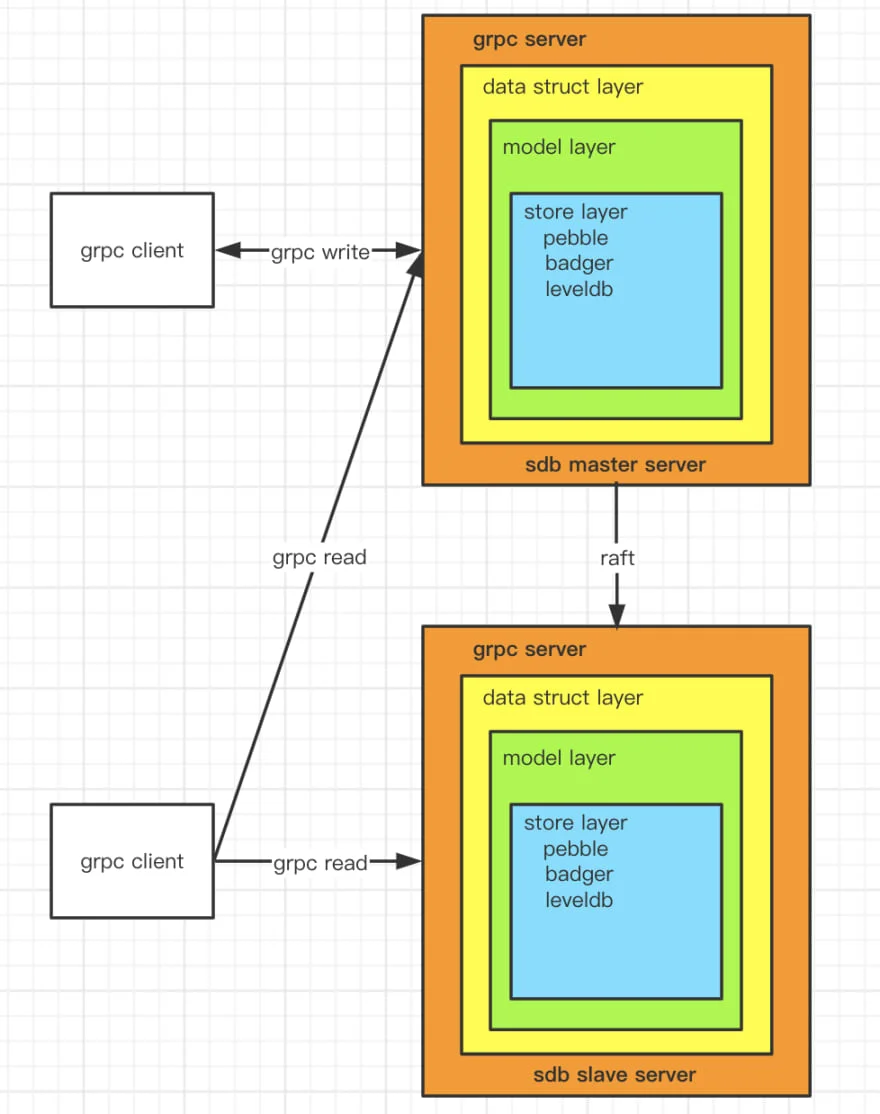
架构
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--YXw4KBJC--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://github.com/yemingfeng /sdb/raw/master/docs/architecture.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--YXw4KBJC--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://github.com/yemingfeng /sdb/raw/master/docs/architecture.png)
-
实现了基于raft协议的主从架构。
-
发起写请求时,可以连接任意节点。如果节点是主节点,则直接处理请求,否则将请求转发到主节点。
-
发起读请求时,可以连接任意节点,节点会直接处理请求。
快速使用
编译protobuf
由于使用了protobuf,项目没有将protobuf生成的go文件上传到
github。需要手动触发编译protobuf文件
sh ./scripts/build_protobuf.sh
进入全屏模式 退出全屏模式
启动主服务器
sh ./scripts/start_sdb.sh
进入全屏模式 退出全屏模式
启动从服务器1
sh ./scripts/start_slave1.sh
进入全屏模式 退出全屏模式
启动从服务器2
sh ./scripts/start_slave2.sh
进入全屏模式 退出全屏模式
默认使用 pebble 存储引擎。
使用cli
客户端使用
package main
import (
"github.com/yemingfeng/sdb/internal/util"
pb "github.com/yemingfeng/sdb/pkg/protobuf"
"golang.org/x/net/context"
"google.golang.org/grpc"
)
var clientLogger = util.GetLogger("client")
func main() {
conn, err := grpc.Dial(":10000", grpc.WithInsecure())
if err != nil {
clientLogger.Printf("faild to connect: %+v", err)
}
defer func() {
_ = conn.Close()
}()
c := pb.NewSDBClient(conn)
setResponse, err := c.Set(context.Background(),
&pb.SetRequest{Key: []byte("hello"), Value: []byte("world")})
clientLogger.Printf("setResponse: %+v, err: %+v", setResponse, err)
getResponse, err := c.Get(context.Background(),
&pb.GetRequest{Key: []byte("hello")})
clientLogger.Printf("getResponse: %+v, err: %+v", getResponse, err)
}
进入全屏模式 退出全屏模式
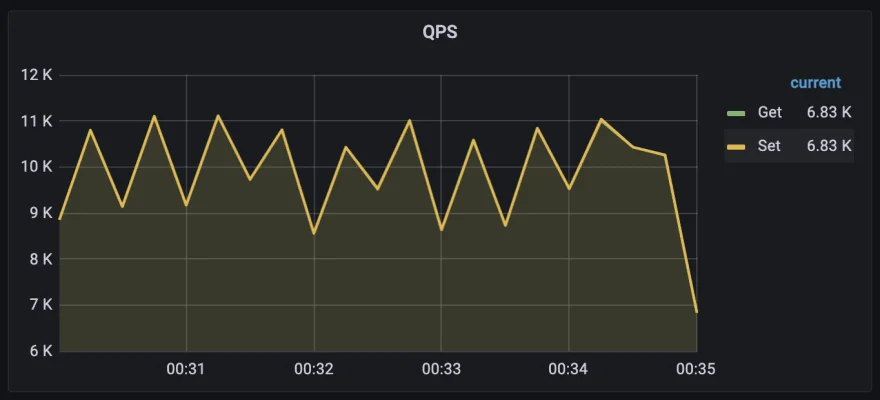
性能测试
测试脚本:benchmark
测试机:MacBook Pro(13 英寸,2016 年,四个 Thunderbolt 3 端口)
测试处理器:2.9GHz 双核酷睿 i5
测试内存:8GB
**测试结果:peek QPS > 10k,avg QPS > 9k,set avg time < 80ms,get avg time <
0.2ms**
[ ](https://res.cloudinary.com/practicaldev/image/fetch/s--IPM37gYb--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://github.com/yemingfeng /sdb/raw/master/docs/benchmark.png)
](https://res.cloudinary.com/practicaldev/image/fetch/s--IPM37gYb--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://github.com/yemingfeng /sdb/raw/master/docs/benchmark.png)
计划
-
[x] 写接口文档
-
[x] 实现更多 API (2021.12.30)
-
[x] 字符串
-
[x] 设置NX
-
[x] 获取集
-
[x] MGet
-
[x] MSet
-
[x] 列表
-
[x] 成员
-
[x] LLPush
-
[x] 设置
-
[x] 成员
-
[x] 排序集
-
[x] ZMembers
-
[x] 支持更丰富的数据结构(2021.01.20)
-
[x] 位集
-
[x] 映射
-
[x] 地理哈希
-
[x] sdb-cli(2021.03.10)
-
[x] 主从架构
-
[ ] 写sdb kv存储引擎
接口文档
字符串
界面
范围
描述
放
核心价值
设置千伏
MSet
键、值
设置多kv
集NX
核心价值
当key不存在时,设置值
得到
钥匙
获取key对应的值
获取
钥匙
获取一组键对应的值
的
钥匙
删除键
增量
键,三角洲
将 delta 添加到键中,如果值不是数字,则抛出异常。如果 value 不存在,则 value u003d delta
列表
界面
范围
描述
轻推
键、值
附加键数组中的值
LLP推
键、值
将值附加到键数组的前面
流行音乐
键、值
从键数组中删除所有值元素
范围
键、偏移量、限制
按数组顺序遍历keys,从0开始。如果offsetu003d-1,则从后向前遍历
存在
键、值
确定键数组中是否存在值
LDEL
钥匙
删除一个键数组
计数
钥匙
返回key数组的元素个数,时间复杂度高,不推荐
会员
钥匙
按数组顺序遍历键。时间复杂度高,不推荐
套
界面
范围
描述
推
键、值
向键集合添加值
流行音乐
键、值
从键集合中删除所有值元素
性存在
键、值
确定键集中是否存在值
斯德尔
钥匙
删除密钥集
计数
钥匙
返回key set的元素个数,时间复杂度高,不推荐
会员
钥匙
按值大小迭代键。时间复杂度高,不推荐
排序集
界面
范围
描述
住口
键,元组
将值添加到键排序集中,按 tuple.score 从小到大排序
流行音乐
键、值
从键排序集中删除所有值元素
Z范围
键、偏移量、限制
根据分数大小,从小到大对键进行迭代。如果offset u003d -1,开始按score从大到小遍历
存在
键、值
确定键排序集中是否存在值
德尔
钥匙
删除一个键排序集
ZCount
钥匙
返回排序后的key集合中的元素个数,时间复杂度高,不推荐
会员
钥匙
根据分数大小,从小到大对键进行迭代。时间复杂度高,不推荐
布隆过滤器
界面
范围
描述
BF创建
键,n,p
创建布隆过滤器,n为元素个数,p为误报率
BF德尔
钥匙
删除关键布隆过滤器
BFAdd
键、值
向布隆过滤器添加值。未创建布隆过滤器时会抛出异常
BF存在
键、值
确定键布隆过滤器中是否存在值
超级日志日志
界面
范围
描述
HLL创建
钥匙
创建超级日志日志
HLLDEL
钥匙
删除一个超级日志日志
HLL
键、值
将值添加到超级日志日志。未创建超级日志日志时会抛出异常
HLL计数
钥匙
获取超级日志日志的去重元素的数量
位组
界面
范围
描述
VS德尔
钥匙
删除一个位集
BSSetRange
键、开始、结束、值
将键 [start, end) 范围位设置为值
BSM 集
键、位、值
将关键位设置为值
BSGetRange
关键,开始,结束
获取键 [start, end) 范围内的位
BSMGet
钥匙,位
获得关键位
BSM 计数
钥匙
获得密钥位数 u003d 1
BSM 计数范围
关键,开始,结束
得到键的数量 [start, end) bit u003d 1
地图
界面
范围
描述
MPush
钥匙,对
将pairs KV对添加到键映射
流行音乐
钥匙,钥匙
删除键映射中的所有键元素
墨西哥存在
钥匙,钥匙
确定键映射中是否存在键
MDEL
钥匙
删除地图
MCount
钥匙
返回key map中的元素个数,时间复杂度高,不推荐
成员
钥匙
按 pair.key 大小迭代对。时间复杂度高,不推荐
地理哈希
界面
范围
描述
GH创造
关键,精准
创建一个地理哈希,precision 代表精度。
欺骗
钥匙
删除地理哈希
他加了
关键点
将点添加到地理哈希中,点中的 id 是唯一标识符
流行音乐
钥匙,身份证
删除点
GHGetBoxes
关键
返回与关键地理哈希中的点在同一框中的点列表,按距离从小到大排序
GHGetNeighbors
关键
返回与关键地理哈希中的点最近的点列表,按距离从小到大排序
GH计数
钥匙
返回key geo hash中的元素个数,时间复杂度高,不推荐
GHM会员
钥匙
返回关键地理哈希中所有点的列表。时间复杂度高,不推荐
页
界面
范围
描述
列表
数据类型、键、偏移量、限制
查询数据类型下的现有元素。如果key不为空,则获取该dataType下key的元素。
酒吧子
界面
范围
描述
订阅
话题
订阅一个主题
发布
主题,有效载荷
将有效负载发布到主题
集群
界面
范围
描述
中信
获取集群中的节点信息
监视器
安装docker版本grafana、prometheus(可跳过)
- 启动脚本/运行_monitor.sh
Grafana 配置
-
打开grafana:http://localhost:3000(注意替换ip地址)
-
创建新的prometheus datasources:http://host.docker.internal:9090(如果使用docker安装,就是这个地址。如果host.docker.internal无法访问,只需替换prometheus.yml文件host.docker.internal 是你自己的ip地址)
-
将脚本/dashboard.json文件导入 grafana 仪表板
最终效果可以参考:性能测试的grafana图
配置参数
范围
描述
默认值
存储引擎
存储引擎,可选鹅卵石,水平,獾
卵石
存储路径
存储目录
./master/db/
server.grpc_port
grpc 端口
10000
server.http_port
http端口,prometheus使用
11000
服务器速率
每秒 qps 限制
30000
集群路径
raft日志存放的目录
./主/筏
cluster.node_id
raft协议标识的节点id,必须唯一
1
集群地址
筏通信地址
127.0.0.1:12000
集群主控
现有集群中master节点的地址是通过master节点暴露的http[http_port]接口添加的。如果是新集群,则为空。
集群超时
raft协议申请超时,单位是ms
10000
集群加入
作为从节点,是否加入主节点;第一次加入需要设置为true,加入后重新开始设置为false
错误的
SDB原理-存储引擎选择
SDB项目的核心问题是数据存储方案的问题。
首先,我们不能手工编写存储引擎。这工作量太大而且不可靠。我们必须
在开源项目中找到适合SDB定位的存储方案。
SDB需要能够提供高性能读写能力的存储引擎。
常用的单机存储引擎方案有B+树、LSM树、B树。
还有一个背景,golang在云原生上的表现非常好,它的表现是
媲美C语言,开发效率也高,所以SDB更喜欢用pure
golang 用于开发。
所以现在问题变成了:用纯golang开发的存储引擎比较难找
版本。在收集了一系列资料后,我找到了以下开源解决方案:
- LSM
*go-leveldb
*syndtr-goleveldb
*獾
*鹅卵石
- B+树
*商店 pc-shop
*etcd-螺栓
综合来看,golangdb、badger、pebble这三个存储引擎都非常不错。
为了兼容这三种存储引擎,SDB 提供了一个
抽象接口
,然后适配三种存储引擎。
SDB原理——数据结构设计
SDB通过前面三个存储引擎解决了数据存储的问题。但是如何
支持 KV 存储引擎上丰富的数据结构?
以 pebble 为例,首先 pebble 提供如下接口能力:
-
集(k, v)
-
得到(k)
-
德尔(k)
-
批
-
迭代器
下面我以对List数据结构的支持为例来分析SDB是如何支持List的
通过 pebble 存储引擎。
List数据结构提供以下接口:LRPush、LLPush、LPop、LExist、LRange、
L计数。
如果一个List的key是:[hello],List的元素是:[aaa, ccc, bbb],那么每个
List 的元素存储在 pebble 中:
鹅卵石钥匙
卵石价值
l/hello/{unique_ordering_key1}
啊啊啊
l/hello/{unique_ordering_key2}
ccc
l/hello/{unique_ordering_key3}
bbb
List 元素的 pebble 密钥生成策略:
-
数据结构前缀:List以l字符为前缀,Set以s为前缀...
-
list key部分:List的key是hello
-
unique_ordering_key:生成方式采用雪花算法实现,保证局部自增
-
pebble值部分:List元素的真实内容,如aaa、ccc、bbb
为什么List的插入顺序有保证?
这是因为 pebble 是 LSM 的一种实现,它使用键的字典顺序
内部。 SDB为了保证插入顺序,给pebble添加了unique_ordering_key
key 作为排序的依据,从而保证了插入顺序。
使用 pebble 密钥生成策略,一切都变得更容易。我们来看看核心逻辑
Lush、PLush、Lop 和 ORange:
LRP推
func LRPush(key []byte, values [][]byte) (bool, error) {
batchAction := store.NewBatchAction()
defer batchAction.Close()
for _, value := range values {
batchAction.Set(generateListKey(key, util.GetOrderingKey()), value)
}
return batchAction.Commit()
}
进入全屏模式 退出全屏模式
LLPush
LLPush 的逻辑与 LRPush 的逻辑非常相似。不同的是,只要
{unique_ordering_key} 为负数,成为最小值。为了确保值
是内部排序的,我们必须 - 索引。逻辑如下:
func LLPush(key []byte, values [][]byte) (bool, error) {
batch := store.NewBatch()
defer batch.Close()
for i, value := range values {
batch.Set(generateListKey(key, -(math.MaxInt64 - util.GetOrderingKey())), value)
}
return batch.Commit()
}
进入全屏模式 退出全屏模式
LPop
写入 pebble 时,密钥是通过 unique_ordering_key 方案生成的。找不到
pebble 中 List 的元素直接在 pebble 键中。删除元素时,需要
遍历List的所有元素,找到valueu003dvalue的元素要删除,然后
删除它。核心逻辑如下:
func LPop(key []byte, values [][]byte) (bool, error) {
batchAction := store.NewBatchAction()
defer batchAction.Close()
store.Iterate(&store.IteratorOption{Prefix: generateListPrefixKey(key)},
func(key []byte, value []byte) {
for i := range values {
if bytes.Equal(values[i], value) {
batchAction.Del(key)
}
}
})
return batchAction.Commit()
}
进入全屏模式 退出全屏模式
LRange
与删除逻辑类似,通过 iterator 接口为
穿越了。对反向迭代的额外支持在这里
允许offset传入-1,表示从后面迭代。
func LRange(key []byte, offset int32, limit uint32) ([][]byte, error) {
index := int32(0)
res := make([][]byte, limit)
store.Iterate(&engine.PrefixIteratorOption{
Prefix: generateListPrefixKey(key), Offset: offset, Limit: limit},
func(key []byte, value []byte) {
res[index] = value
index++
})
return res[0:index], nil
}
进入全屏模式 退出全屏模式
以上实现了对List数据结构的支持。
其他数据结构在逻辑上大体相似,其中
其中排序_set
更复杂。你可以自己检查。
LPop优化
聪明的人可以看出LPop的逻辑在大容量的情况下会消耗大量的性能
数据量。这是因为我们无法知道存储中的值对应的key
引擎,我们需要将List中的所有元素加载出来后,再一一判断
删除。
为了降低时间复杂度和提高性能。以列表:[hello] -> [aaa, ccc, bbb] 为
一个例子。存储模型将更改为以下内容:
正行索引结构[不变]:
鹅卵石钥匙
卵石价值
l/hello/{unique_ordering_key1}
啊啊啊
l/hello/{unique_ordering_key2}
ccc
l/hello/{unique_ordering_key3}
bbb
二级索引结构
鹅卵石钥匙
卵石价值
l/hello/aaa/{unique_ordering_key1}
啊啊啊
l/hello/ccc/{unique_ordering_key2}
ccc
l/hello/bbb/{唯一_ordering_key3}
bbb
有了这个辅助索引,我们就可以判断是否存在某个值的元素
通过前缀检索列出。这降低了时间复杂度并提高了性能。也是
写元素的时候需要写辅助索引,所以核心逻辑会变
至:
func LRPush(key []byte, values [][]byte) (bool, error) {
batch := store.NewBatch()
defer batch.Close()
for _, value := range values {
id := util.GetOrderingKey()
batch.Set(generateListKey(key, id), value)
batch.Set(generateListIdKey(key, value, id), value)
}
return batch.Commit()
}
func LLPush(key []byte, values [][]byte) (bool, error) {
batch := store.NewBatch()
defer batch.Close()
for i, value := range values {
id := -(math.MaxInt64 - util.GetOrderingKey())
batch.Set(generateListKey(key, id), value)
batch.Set(generateListIdKey(key, value, id), value)
}
return batch.Commit()
}
func LPop(key []byte, values [][]byte) (bool, error) {
batch := store.NewBatch()
defer batch.Close()
for i := range values {
store.Iterate(&engine.PrefixIteratorOption{Prefix: generateListIdPrefixKey(key, values[i])},
func(storeKey []byte, storeValue []byte) {
if bytes.Equal(storeValue, values[i]) {
batch.Del(storeKey)
infos := strings.Split(string(storeKey), "/")
id, _ := strconv.ParseInt(infos[len(infos)-1], 10, 64)
batch.Del(generateListKey(key, id))
}
})
}
return batch.Commit()
}
进入全屏模式 退出全屏模式
SDB原理——关系模型到KV模型的映射
通过上面的解决方案,你大概知道了KV存储引擎是如何支持数据结构的。但
这种方法很粗糙,不能一概而论。
参考TiDB Design,SDB 设计了一个
关系模型到 KV 结构。
在 SBD 中,数据由集合和行构成。在:
- 收藏
类似于数据库的表是一个逻辑概念。每个dataType(如List)对应一个
收藏。一个集合包含多个行。
- A Row包含唯一键:key、id、value、indexes,**是实际存储在KV中的数据
{dataType} + {key} + {id}- 每行包含N个索引,每个索引都有indexKey作为唯一值,indexKey
{dataType} + {key} + idx_{indexName} + {indexValue} + {id}以ListCollection为例,List的key为[l1],假设Collection有4个
rows of Row,每行 Row 都有 value 和 score 的索引
那么每一行的Row结构如下:
{ {key: l1}, {id: 1.1}, {value: aaa}, {score: 1.1}, indexes: [ {name: "value", value: aaa}, {name: "score", value: 1.1} ] }
{ {key: l1}, {id: 2.2}, {value: bbb}, {score: 2.2}, indexes: [ {name: "value", value: bbb}, {name: "score", value: 2.2} ] }
{ {key: l1}, {id: 3.3}, {value: ccc}, {score: 3.3}, indexes: [ {name: "value", value: ccc}, {name: "score", value: 3.3} ] }
{ {key: l1}, {id: 4.4}, {value: aaa}, {score: 4.4}, indexes: [ {name: "value", value: aaa}, {name: "score", value: 4.4} ] }
进入全屏模式 退出全屏模式
1/l1/1.11/l1/idx_value/aaa/1.11/l1/idx_score/1.1/1.1 rowKey: 1/l1/1.1 -> { {key: l1}, {id: 1.1}, {value: aaa}, {score: 1.1}, indexes: [ {name: "value", value: aaa}, {name: "score", value: 1.1} ] }
valueIndexKey: 1/l1/idx_value/aaa/1.1, -> 1/l1/1.1
scoreIndexKey: 1/l1/idx_score/1.1/1.1 -> 1/l1/1.1
进入全屏模式 退出全屏模式
这样,数据结构、KV存储、关系模型就连接起来了。
SDB原理-通讯协议方案
解决了存储和数据结构的问题后,深发展面临“最后一公里”的问题
这是通信协议的选择。
SDB的定位是支持多种语言,所以需要选择一种通信方式
支持多种语言的框架。
grpc 是一个非常好的选择。只需要使用 SDB proto 文件即可自动生成
各种语言的客户端,通过protoc命令行工具,解决了
开发不同的客户。
SDB原理-主从架构
在解决了以上所有问题之后,SDB 已经是一个可靠的独立 NoSQL 数据库了。
为了进一步优化SDB,SDB增加了主从架构。
golang语言下的raft协议有3种选择,分别是:
-
hashcorp/筏
-
etcd/筏
-
龙舟/筏
为了支持中国项目,选择了龙舟。 PS:谢谢中国人!
使用 raft 协议后,整个集群的吞吐量略有下降,但随着读取能力的横向扩展,好处还是很明显的。
版本更新记录
vz.0.0
- commit基于raft实现的主从架构
v1.7.0
- commit使用sharding存储bitset,bitset不再需要初始化,具有[自动扩容]的功能