
介绍一些微服务中的常见问题,包括常见概念,中间件,系统平台等。
限流器
某些业务需要针对 IP 或者用户来进行一个限流操作,减少恶意请求,减轻服务器压力或者根据业务需求来进行频率控制。 限流可以在很多层面去做,比如 nginx+lua, API Gateway,或者在接口层直接来做,一般可以结合 redis 来做为计数器。 限流有一下一些实现方式,可以根据业务场景选择:
常见的几种方式是信号量、漏桶算法、令牌桶算法。
- token bucket。令牌桶算法。允许突发流量。https://github.com/juju/ratelimit 或者 go 自带的 https://github.com/golang/time
- leaky bucket。漏桶算法。以恒定速率处理(恒定速率漏水) https://github.com/uber-go/ratelimit
- redis incr/expire。最简单的一种方式,通过 redis 针对用户或者 ip key 来计数,可以加上用户信息作为 key
- redis zset。可以实现基于时间窗口来限流。不过不适合短期内大量 qps 限流,适合用户行为限流
你可以在网上很方便的搜索 『rate limiter』 来找到对应的实现。
断路器/熔断器(Circuit Breaker)
在分布式系统中,为了防止级联错误,导致服务雪崩,经常需要使用断路器来保护系统。断路器原理如下:
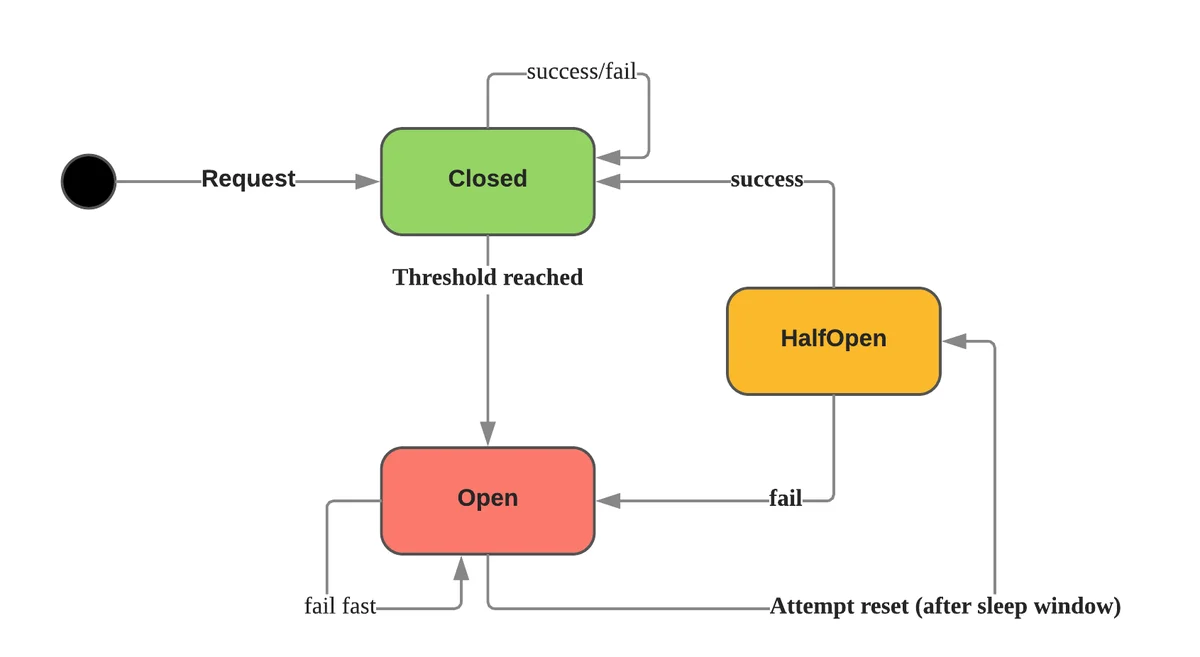
Netflix 开源的 Hystrix 是比较流行的开源实现,对应的有各种其他语言的实现,比如 Hystrix-go
参考:
分布式 id 生成器(发号器)
单机 mysql 一般我们直接使用 mysql 提供的自增 id 作为主键,但是分布式系统下需要别的算法来保证多机 mysql 全局自增唯一 id。 一般有如下一些实现方式,各有优劣,可以根据自己的业务灵活选取:
- 发号器(snowflake 算法)
- uuid
一般来说单调递增整形 id 对于索引更加友好,所以一般我们可以使用 snowflake 之类的算法来分配 id,其大致原理如下:

网上依旧很多开源实现,你可以搜索到一些 snowflake 的 golang 实现,注意依赖时间戳有些可能有时钟回拨问题。
RPC
在分布式系统中,不同业务模块之间可以通过消息队列或者 rpc 来进行通信。
服务发现
配置中心
健康检查
日志聚合(ELK)
分布式跟踪
异常跟踪
应用程序指标
分布式锁
单机上可以使用 go 提供的 sync 包加锁,分布式情况下一般有几种方式:
- redis: 借助 setnx。性能较高
- zookpeer: 适合分布式调度,不适合高频率持有时间短的抢锁场景
- etcd
消息队列
延时队列
在分布式系统中经常需要触发一些延后执行的任务,比如启动取消未支付订单、定时给预定会的人员发送消息、外卖下单后提醒小哥即将超时, 这个使用一般会使用到延时队列。常见的实现方式是使用 redis zset/死信队列/时间轮等。 有一些语言框架直接帮我们实现好了, 比如 python celery, golang 的 machinery 等,也可以直接拿来用,一般需要一个消息度列作为broker.
分布式缓存
常见缓存使用模式
- Cache Aside: 如果数据在缓存中直接读取缓存;如果没有缓存 应用从数据库读取 ;更新数据到缓存(下次直接可以从缓存读取了)
- Read Through: 如果数据在缓存中直接读取缓存;如果不存在 缓存负责从数据库读取 ;缓存返回给应用。应用只和缓存交互
- Write Through: 应用写到缓存;缓存直接写到数据库
- Write Back (Write Behind): 应用直接写到缓存;缓存定期把更新刷新到数据库
参考:
缓存问题(击穿,雪崩)
- 缓存和数据库双写一致性问题
- 缓存雪崩: 缓存同一时间全部失效导致数据库瞬间压力陡增引起雪崩。缓存宕机,设置相同过期时间可能导致。(热数据集中淘汰)
- 缓存时间加上超时随机,防止同时大量缓存失效
- 加锁或者队列的方式保证不会同时对数据库进行读写
- 缓存击穿: 某个key缓存过期的那一刻,同时大量请求击穿打到数据库,瞬时数据库压力陡增。
- 缓存穿透: 大量查询 key 不存在导致请求回源到数据库,导致数据库压力增大甚至宕机。
- 可以把所有可能存在的数据放到足够到的bitmap 或者布隆过滤器中,查询之前如果不在其中则过滤掉
- 查询不到的值也放到缓存中加上较短的失效时间
- 缓存污染:爬虫批量抓取导致缓存了很多冷数据
- 缓存并发竞争
- 缓存预热。上线之前可以通过脚本来进行预热,定期刷新
- 热点key。热点 key 导致单机 redis 压力陡增,通过 key hash分散热点或者使用进程缓存的方式(多级缓存),减小 redis 压力
双写不一致性问题
搜索引擎(Elasticsearch)
业务边界划分(领域驱动设计)
笔者感觉微服务的业务划分不光是一个技术问题,还是一个业务问题。笔者经历过的一些项目有时候感觉拆分太细,不像是微服务,反而 是微函数或者微接口了,维护和部署成本急剧升高。粒度太粗了可能又成了一个大的单体项目。 微服务有自己的优势,但也有缺点,比如需要较高的 devops 水平,良好的基础设施,合理的业务代码划分等,如果做不好可能微 服务带来的问题会比收益要多。所以微服务可能也不是银弹,需要根据当前的业务合理选择。
参考:
- 《微服架构设计模式》 一本比较好的讲微服务架构实现的书籍