
hash简介
作为后端开发,说HashMap是我们最经常接触到的数据结构都不为过,而HashMap如其名最主要依赖的算法就是hash散列算法来存储和读取数据。
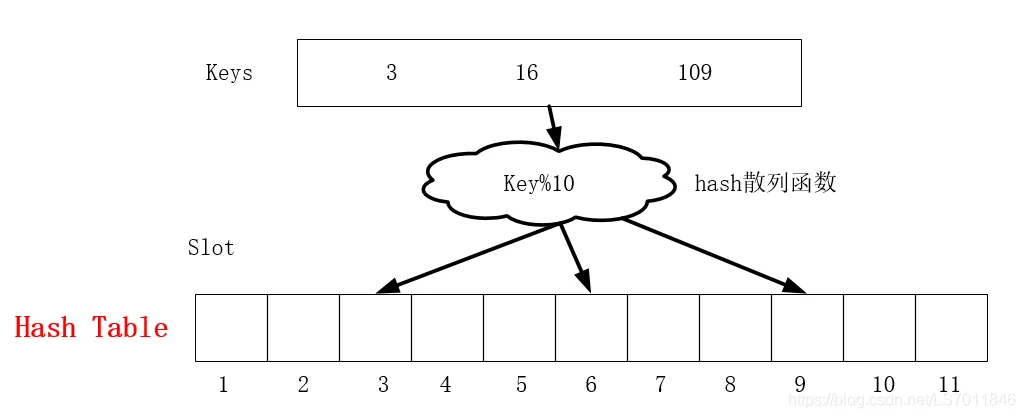
以关键码值K为自变量,通过一定的函数关系h(K)(称为散列函数),计算出对应的函数值来,把这个值解释为结点的存储地址,将结点存入到此存储单元中。检索时,用同样的方法计算地址,然后到相应的单元里去取要找的结点。通过散列方法可以对结点进行快速检索。
按散列存储方式构造的存储结构称为散列表(hash table)。散列表中的一个位置称为槽(slot)。散列技术的核心是散列函数(hash function)。 对任意给定的动态查找表DL,如果选定了某个“理想的”散列函数h及相应的散列表HT,则对DL中的每个数据元素X。函数值h(X.key)就是X在散列表HT中的存储位置。插入(或建表)时数据元素X将被安置在该位置上,并且检索X时也到该位置上去查找。由散列函数决定的存储位置称为散列地址。 因此,散列的核心就是:由散列函数决定关键码值(X.key)与散列地址h(X.key)之间的对应关系,通过这种关系来实现组织存储并进行检索。
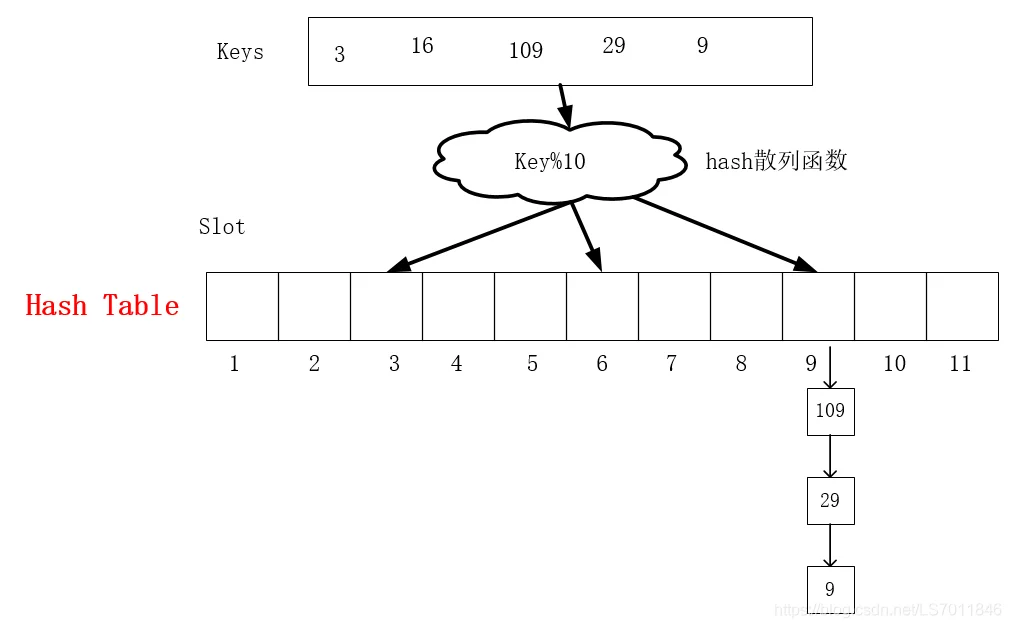
没有完美的hash散列函数,当元素变多的时候必然会出现slot冲突的问题,那么hash散列后的元素冲突解决也是一个问题,常见的散列方法有:线性探测法、二次散列、拉链法等。如下图所示是一个常用的链地址法解决hash冲突的示意图,在9的slot中,后续进入的key为29和9的元素,会通过生成一个链表链接在该slot上。
上面有说到hashmap的一些基本实现原理及解决冲突的方式,那么可以看到hash函数在元素数量过多时会采用不同的冲突解决方案,很明显会对hashmap (o1)的查找插入时间复杂度带来挑战,因此除了优化hash散列算法,在恰当的时候(即元素个数负载因子达到一定的阈值,比如slot为10,元素达到7的时候)对散列表hash table进行扩容也是一个必须采用的方式,这篇文件就想跟大家一起聊一聊在不同领域(语言、软件)中hashmap扩容实现机制。
扩容机制
JavaGolangRedisJava中HashMap扩容
同步Golang中HashMap扩容
增量扩容Redis中HashMap扩容
渐进式hash 接着当哈希表的容量到达一个阈值后,需要进行扩容,于是执行渐进式扩容,如下两个图,当有修改操作到当前slot时对旧hashtable中的元素进行rehash至新的hashtable,直至所有元素迁移完成后,再将h0的指针指向h1,h1重置为null,完成操作。
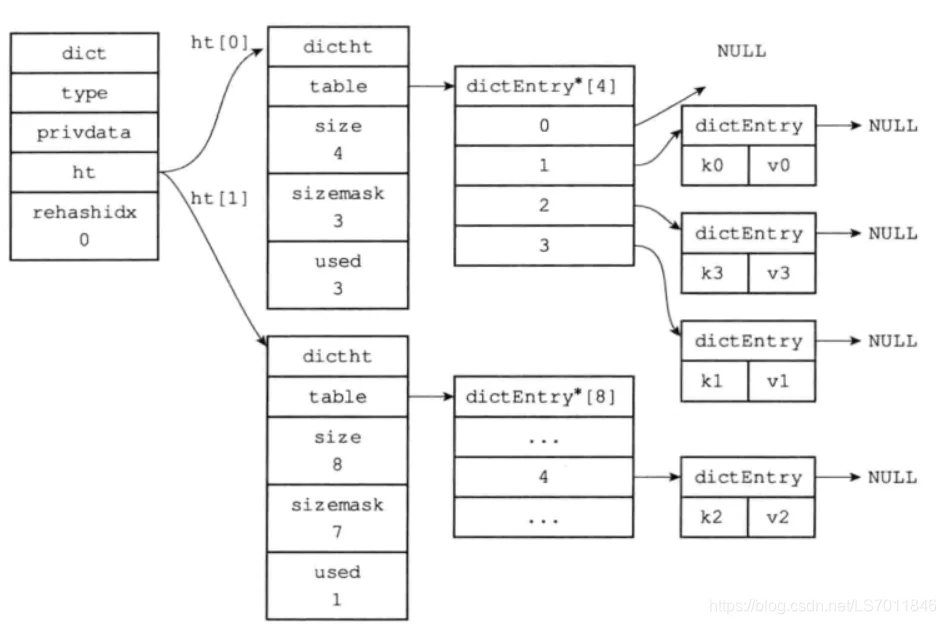
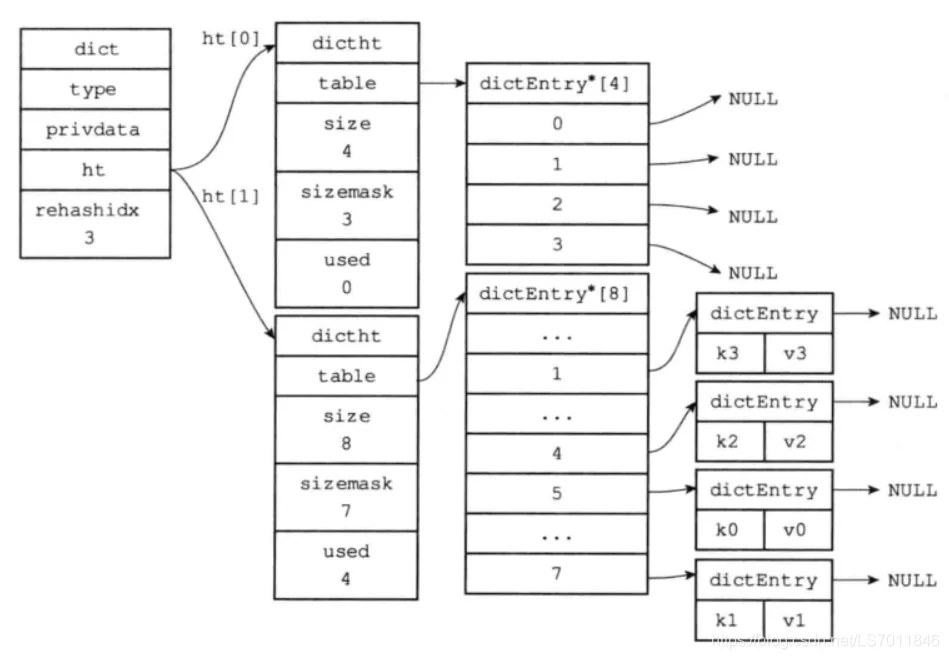
在进行渐进式哈希扩容的过程中,redis会同时使用h0和h1两个哈希表。对于查找操作,会先在h0进行查找,如果没找到的话,会继续在h1的表里进行查找、而新增操作则会都保存到h1中,也保证了h0中的数量不会继续增加。
总结扩容参考资料:
《redis设计与实现》4.5节渐进式哈希
golang map扩容