堆栈(内存分配)
堆(Heap)和栈(Stack) 都是在计算机中不同的数据结构的抽象类型。在应用程序内存分配中,一般来说,堆栈一类特殊的存储区域,用来存放数据和地址。
- 堆(Heap)
在编程中,堆(Heap)是应用程序在运行的时候请求操作系统分配给自己内存,以 C/C++ 程序为例,使用时需要我们主动申请(通过 malloc/New),用完主动释放,或者是程序结束时由操作系统回收,会产生内存碎片。
- 栈(Stack)
栈(Stack)是计算机内存的特定区域,一般 CPU 自动分配释放,数据结构特点是先进先出(FIFO—first in first out)。由于 CPU 可以高效组织内存,读写栈变量会非常快,并且不会产生内存碎片。
- 堆(Heap)和栈(Stack)的区别
- 栈一般由操作系统来分配和释放,堆由程序员通过编程语言来申请创建与释放;
- 栈用来存放函数的参数、返回值、局部变量、函数调用时的临时上下文等,只要是局部的、占用空间确定的数据,一般都存放在 Stack,否则就放在 Heap;
- 栈的访问速度相对比堆快;
- 一般来说,Stack 是线程独占的,Heap 是线程共用的;
- Stack 创建的时候,大小是确定的,Heap 的大小是不确定的,可以自由增加。
现在写程序变负担变得越来越小,很大原因是在传统的 C/C++ 语言中,我们申请的内存空间要自己管理或释放,稍微不严谨,就会造成内存泄露。尤其在混合了多线程编程之后,更容易犯错。
在 Java、Go 等语言中,提供了一种主动释放申请的内存空间的功能,这就是垃圾回收机制,具有这种机制的语言大大解放了程序员负担。
Go 的堆栈
C/C++ 线程中,多数架构上默认线程栈大小都在 2MB ~ 4MB 左右,如果程序同时运行几百个甚至几千个线程,会占用大量的内存空间并带来其他的额外开销,Go 语言在设计时认为执行上下文是轻量级的,所以它在用户态实现 Goroutine 作为执行上下文,最小的栈空间只有 2KB。所以非常高效。
在 C 语言中,这样一段代码是错误的:
#include "stdio.h"
int *test(void)
{
int a = 1;
return &a;
}
int main()
{
}

在 Go 中, 却完全没有问题。
在 Go 中, 却完全没有问题。
package main
import "fmt"
func test() *int {
a := 1
return &a
}
func main() {
intVal := test()
fmt.Println(intVal)
}通过分析我们可以发现:
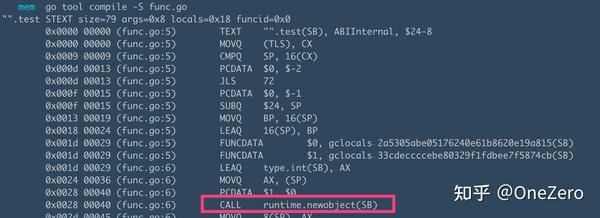
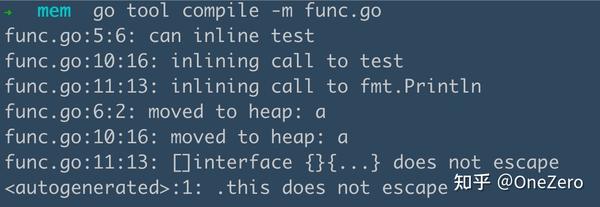
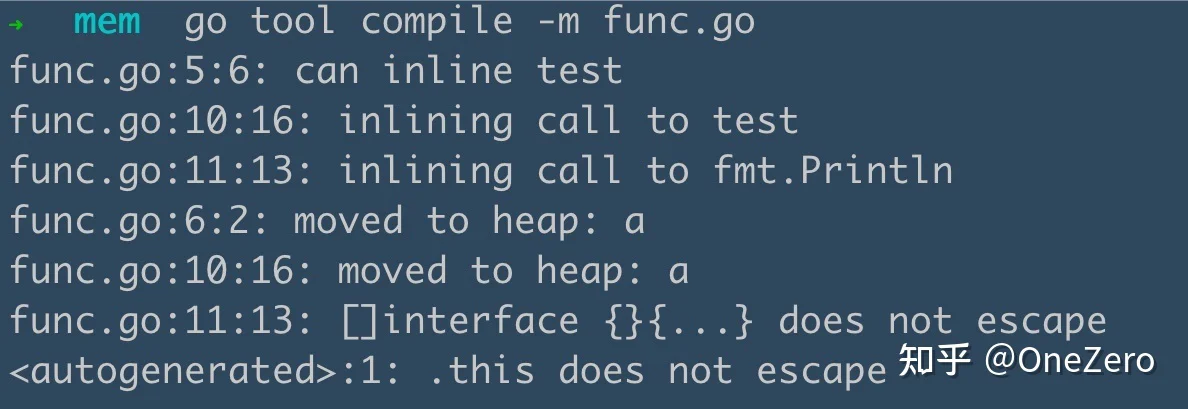
第 6 行代码的的变量 a 分配到了堆上。
这是为什么呢?
Go 中变量分配在栈还是堆上完全由编译器决定,而看起来应该分配在栈上的变量,如果生命周期发生改变,被分配在了堆上,就说它发生了逃逸。编译器会自动地去判断变量的生命周期是否延长,整个判断的过程就叫逃逸分析。
Go 内存逃逸分析的情况
- 切片扩容或容量太大,栈空间不足,逃逸到堆上。
package main
func main() {
s1 := make([]int, 10000, 10000)
_ = s1
}

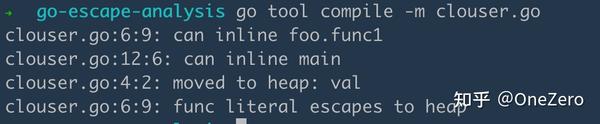
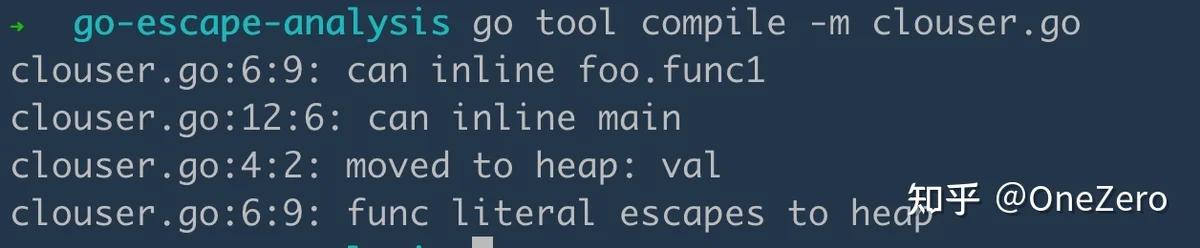
- 局部变量在函数调用完后还被其他地方使用 比如函数返回了局部变量的指针,函数形成闭包。
package main
func foo() func() int {
val := 1
return func() int {
val += 1
return val
}
}
func main() {
foo()
}
- 在 slice 或 map 中存储指针
package main
func main() {
intVal := 10
var ls []*int
ls = append(ls, &intVal)
}

- 向 channel 发送指针数据 在编译时,编译器无法知道channel 中的数据会被哪个 goroutine 接收,无法知道什么时候释放。
package main
func main() {
ch1 := make(chan *int, 1)
y := 5
py := &y
ch1 <- py
}

- 在 interface 类型上调用方法。
在 interface 类型上调用方法时会把 interface 变量使用堆分配,因为方法的真正实现只能在运行时知道。
package main
type foo interface {
fooFunc()
}
type foo1 struct{}
func (f1 foo1) fooFunc() {}
func main() {
var f foo
f = foo1{}
f.fooFunc()
}