
gengine是一款基于golang和AST(抽象语法树)开发的规则引擎,使用一套自定义的简单语法来定义规则来实现语言无关,并且还执行规则执行的各种模式,功能也很强大。
核心API对于gengine的使用,我们先掌握几个核心的API。
DataContextRuleBuilderDataContextGengineRuleBuilderGenginePoolGengineGenginePoolgengine的使用大致分为下面的步骤:
DataContextDataContextRuleBuilderGengine接下来就以一个示例快速了解gengine的使用。
快速使用Usertype User struct {
Name string
Age int64
Male bool
}
func (u *User) GetNum(i int64) int64 {
return i
}
func (u *User) Print(s string) {
fmt.Println(s)
}
func (u *User) Say() {
fmt.Println("hello world")
}
我们在规则中就需要使用这个结构体的实例来进行一些操作
const rule1 = `
rule "name test" "i can" salience 0
begin
if 7 == User.GetNum(7) {
User.Age = User.GetNum(89767) + 10000000
User.Print("6666")
} else {
User.Name = "yyyy"
}
end
`
按照上一部分的使用步骤,我们来编写代码。
DataContext//规则要修改结构体数据,所以要传入指针
user := &User{
Name: "Calo",
Age: 0,
Male: true,
}
// 创建数据上下文,用来向规则中传入数据
dataContext := context.NewDataContext()
dataContext.Add("User", user)
RuleBuilderruleBuilder := builder.NewRuleBuilder(dataContext)
err := ruleBuilder.BuildRuleFromString(rule1)
if err != nil {
log.Fatal(err)
}
Gengineeng := engine.NewGengine()
err = eng.Execute(ruleBuilder, true) // true表示有多个规则的时候,其中一个执行失败也会继续执行其余的规则
if err != nil {
log.Fatal(err)
}
log.Printf("%v\n", user)
使用起来并不复杂,甚至相当简单。对于Gengine的使用有了初步了解,接下来我们就进一步了解规则的语法。
规则语法gengine使用的自定义的简单语法,整体框架如下:
const rule = `
rule "rulename" "rule-description" salience 10
begin
//规则体
end`
- rulename:规则名,必须唯一。多个同名的规则编译后会只剩下一个。
- rule-description:规则描述,非必须。
- salience:关键字,后跟数字表示优先级,数字越大优先级越高。
- begin和end包裹的就是规则体,规则的具体逻辑在这里编写。
规则体支持基本的数据类型,与go语言的基本类型一致。此外还支持了string类型。对于运算,规则体支持基本的算术四则运算,逻辑运算,比较运算,还有string的加法运算。
这些类型和运算的编写与go语言基本一致,不过规则体需要使用内置的isNil()函数来判断是否为nil。
const rule_else_if_test =`
rule "elseif_test" "test"
begin
a = 8
if a < 1 {
println("a < 1")
} else if a >= 1 && a <6 {
println("a >= 1 && a <6")
} else if a >= 6 && a < 7 {
println("a >= 6 && a < 7")
} else if a >= 7 && a < 10 {
println("a >=7 && a < 10")
} else {
println("a > 10")
}
end`
规则体还支持conc并发语法块
const rule_conc_statement = `
rule "conc_test" "test"
begin
conc {
a = 3.0
b = 4
c = 6.8
d = "hello world"
e = "you will be happy here!"
}
println(a, b, c, d, e)
end`
conc块中的语句会并发执行,需要用户自己保证conc中调用的api是线程安全的。
多级调用
.注释
规则体支持单行注释,与go语言一样以双斜杠(//)开头。
内置变量
- @name: 指代当前规则名
- @id:如果规则名是可以转为整数的字符串,那么@id就是这个整数,否则就是0.
- @desc:当前规则的描述信息。
- @sal:当前规则的优先级,类型为int64。
自定义变量
DataContextreturn支持
return可以用来直接返回规则执行,并且gengine的return可以返回不同类型的结果。
rule := `
rule "return_in_statements"
begin
if a < 100 {
return 5 + 6 * 6
} else if a >= 100 && a < 200{
return "hello world"
} else {
return true
}
end
`
当规则数量少的时候,每次修改规则后重新编译所有的规则并没有什么问题。但是当规则数量成千上万之后,如果每次修改一个规则,就要重新编译全部的规则,那么就会造成资源的浪费。
于是Gengine支持两种更新方式,全量更新与增量更新。并且规则更新是线程安全的。
- 全量更新:无论是新增还是修改一个规则,都会移除上一次所有规则,然后重新编译这一批传递过来的所有规则
//单实例时
ruleBuilder := builder.NewRuleBuilder(dataContext)
e1 := ruleBuilder.BuildRuleFromString(rulesString) //这里全量更新
//pool中全量更新
//第一处
pool初始化的时候是全量更新的
//第二处
func (gp *GenginePool) UpdatePooledRules(ruleStr string) error
- 增量更新:只对新增或者更新的规则进行编译,其余的规则则不进行任何操作
//单实例 rule_builder.go
func (builder *RuleBuilder)BuildRuleWithIncremental(ruleString string) error
//pool中的增量更新接口
func (gp *GenginePool) UpdatePooledRulesIncremental(ruleStr string) error
当规则数量很大时,使用增量更新可以显著提高效率,降低资源消耗。
- 批量删除
//ruleBuilder中
func (builder *RuleBuilder) RemoveRules(ruleNames []string) error
//pool中
func (gp *GenginePool) RemoveRules(ruleNames []string) error
看一张官方的图,gengine支持的执行模式如何所示
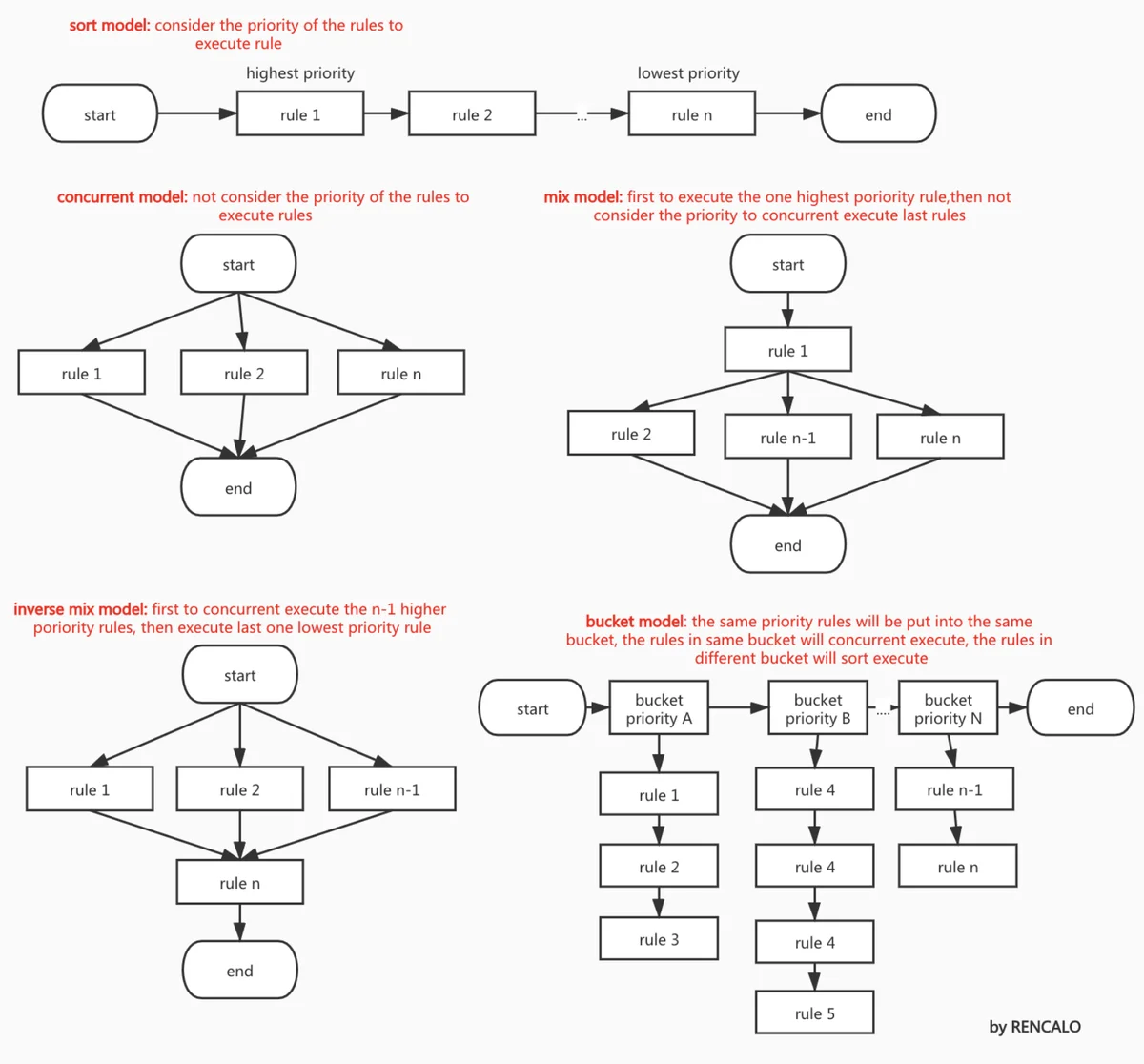
这些执行模式都是基于gengine定义的规则的优先级。
- 顺序执行模式:按照优先级从高到低的顺序依次执行。不过要注意:没有显式制定规定的优先级,那么规则的优先级不确定,相同优先级的执行顺序不一致。
- 并发执行模式:不考虑优先级,全部并发执行。
- 混合模式:选择一个优先级最高先执行,剩下的n-1个并发执行。
- 逆混合模式:选择优先级高的n-1个并发执行,最后执行剩下的一个优先级最低的规则。
顺序模式下有如下的API:
ExecuteExecuteWithStopTagDirectExecuteExecuteSelectedRules并发模式下API:
ExecuteConcurrentExecuteSelectedRulesConcurrent混合模式API:
ExecuteMixModelExecuteMixModelWithStopTagDirectExecuteSelectedRulesMixModel逆混合模式API:
ExecuteInverseMixModelExecuteSelectedRulesInverseMixModelGengine//must default false
stag := &engine.Stag{StopTag: false}
dataContext.Add("stag", stag)
eng := engine.NewGengine()
e2 := eng.ExecuteWithStopTagDirect(ruleBuilder, true, stag)
NM执行模式
这是衍生出来的一种模式。按照优先级高低将规则分为两部分。第一阶段为前N个最高优先级的规则,剩下M个规则为第二阶段。
按照两个阶段执行模式的不同,产生了如下子模式
| 执行模式 | 说明 |
|---|---|
| nSort - mConcurrent | 前n个顺序执行,后m个并发执行 |
| nConcurrent - mSort | 前n个并发执行,后m个顺序执行 |
| nConcurrent - mConcurrent | 前n个并发执行,后m个也并发执行 |
| nSort - mSort | 就是普通的顺序执行 |
实际上就只有3个子模式,也就是3个api
ExecuteNSortMConcurrentExecuteNConcurrentMSortExecuteNConcurrentMConcurrent与前面的api一样,这三个api也有对应的选择式,也就是使用规则名过滤出一部分规则,然后按照对应的执行模式执行。分别是:
ExecuteSelectedNSortMConcurrentExecuteSelectedNConcurrentMSortExecuteSelectedNConcurrentMConcurrentDAG执行模式
DAG是有向无环图执行模式,图的存储主要有邻接矩阵和临接连表两种方式,但是图的存储都是比较复杂的,gengine对此进行了优化。看官网上的图很容易就理解
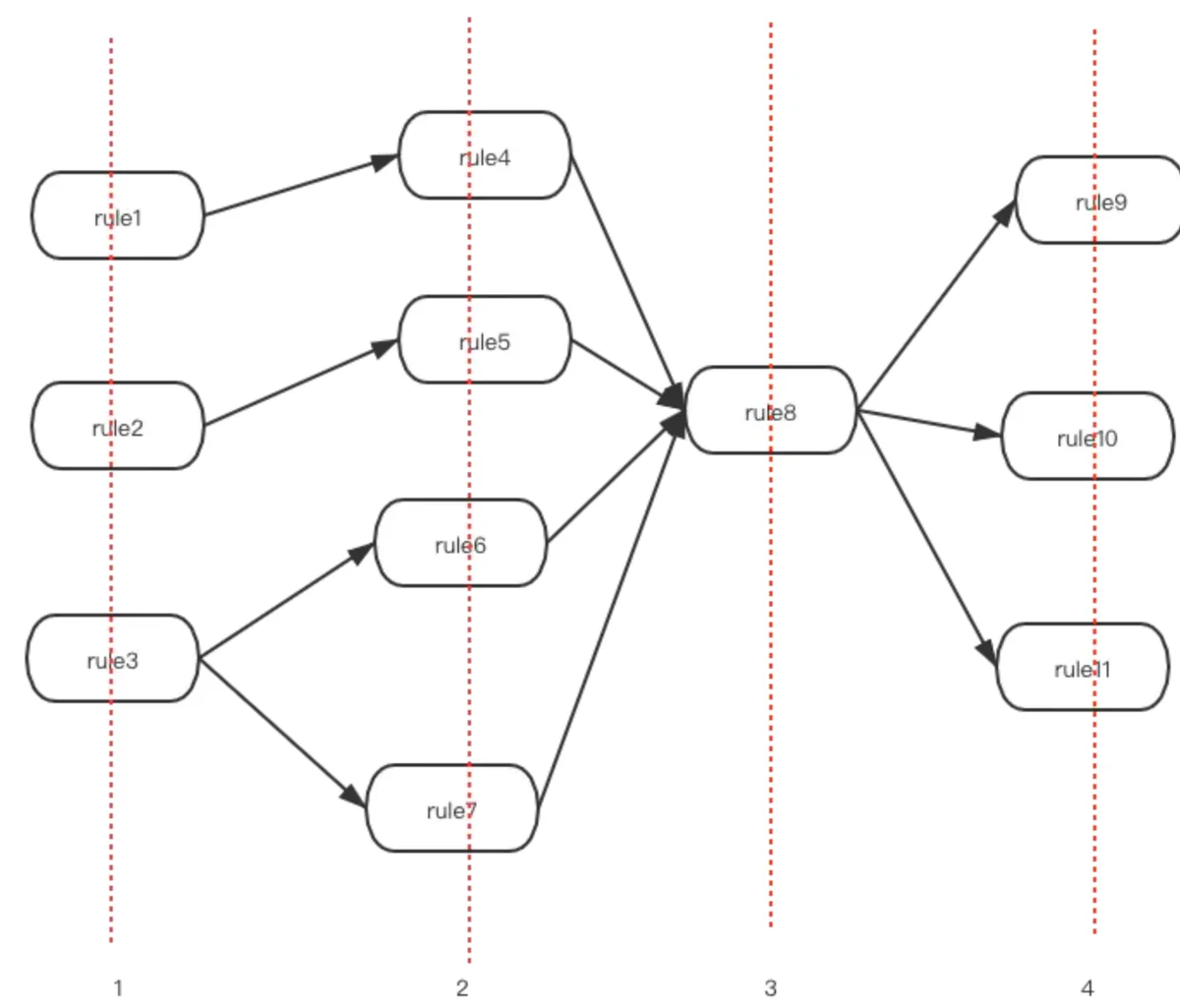
将DAG抽象为了图层,层内规则并发执行,层间规则顺序执行。用代码的语言来说就是
func (g *Gengine) ExecuteDAGModel(rb *builder.RuleBuilder, dag [][]string) error
func (gp *GenginePool) ExecuteDAGModel(dag [][]string, data map[string]interface{}) (error, map[string]interface{})
dag[0], dag[1]dag[0]dag[1]池化都是为了解决性能和并发安全问题的,例如数据库连接池。
gengine在执行规则的过程中是有状态的,因此不能在一个请求的规则执行结束之前就执行下一个请求的规则,否则会破坏当前请求执行结果的正确性。
为了提高性能和并发问题,引入了引擎池,提供的所有api都是线程安全的。
//初始化一个规则引擎池
func NewGenginePool(poolMinLen ,poolMaxLen int64, em int, rulesStr string, apiOuter map[string]interface{})
参数说明:
ExecuteSelectedRulesExecuteSelectedRulesConcurrent对于单实例的gengine的执行api,都有对应的引擎池版本的api。以其中一个为例
func (gp *GenginePool) Execute(data map[string]interface{}, b bool) (error, map[string]interface{})
data