
注:本文基于Windos系统上Go SDK v1.16进行讲解
1.前言
我们已经介绍过堆内存,知道堆内存被划分为一个一个的arena,分别进行管理。为了降低碎片化内存的影响,又进一步划分出多个span,每个span按某种规格划分成等大的内存块。
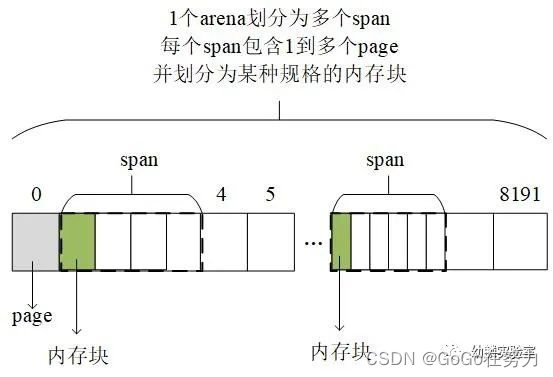
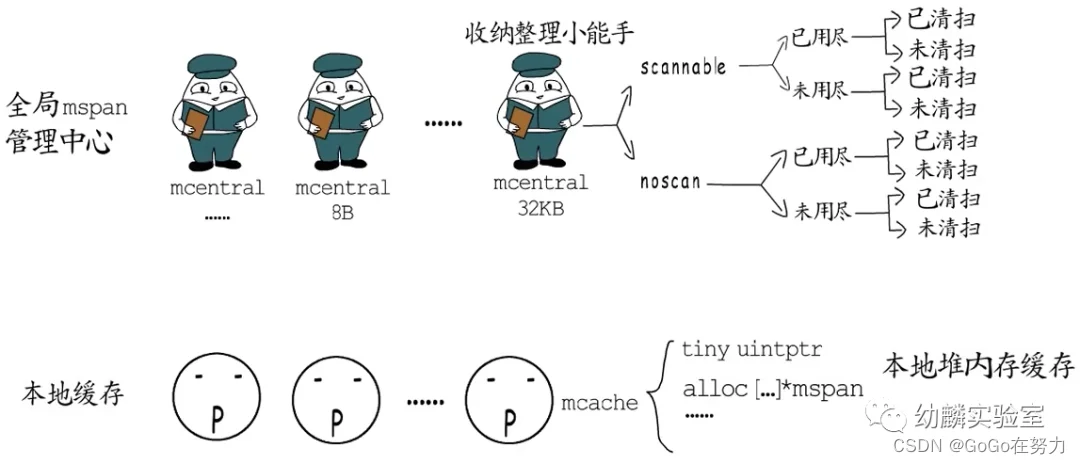
全局mspan管理中心分门别类管理着所有span。不过,要是都从这里获取内存块,竞争就太激烈了。所以每个P这里都会放一个本地mspan缓存,先紧着本地的用,不行再去全局管理中心这里竞争。
2.栈分配
2.1栈分配
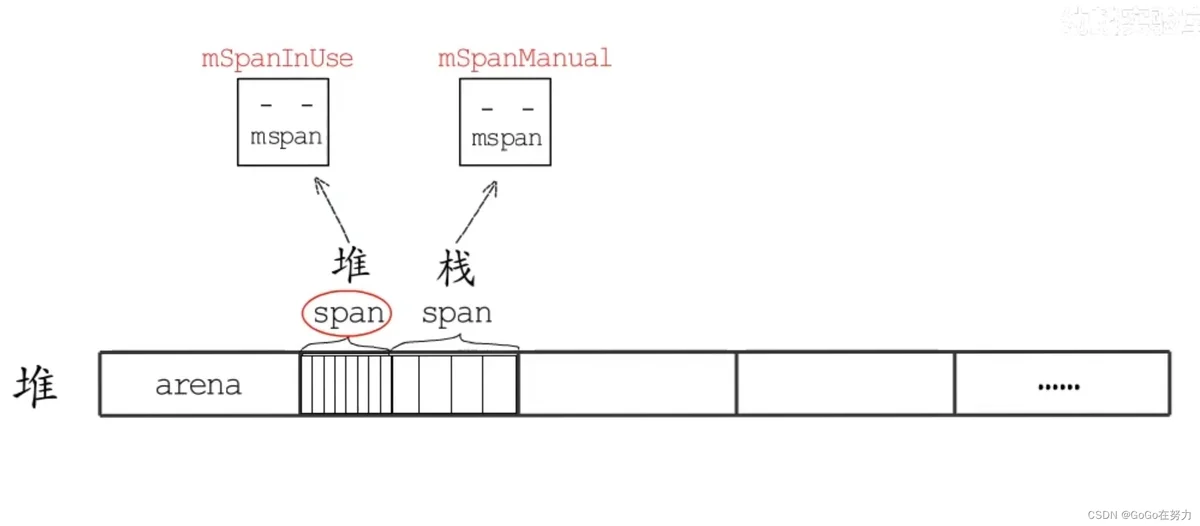
其实,span除了用作堆内存分配外,也用于栈内存分配,只是用途不同的span对应的mspan状态不同。用做堆内存的mspan状态为mSpanInUse,而用做栈内存的状态为mSpanManual。
为提高栈内存分配效率,调度器初始化时会初始化两个用于栈分配的全局对象:stackpool 和stackLarge。
2.2stackpool
var stackpool [_NumStackOrders]struct {
item stackpoolItem
// 省略掉用于内存对齐的填充空间
}
//go:notinheap
type stackpoolItem struct {
mu mutex
span mSpanList
}
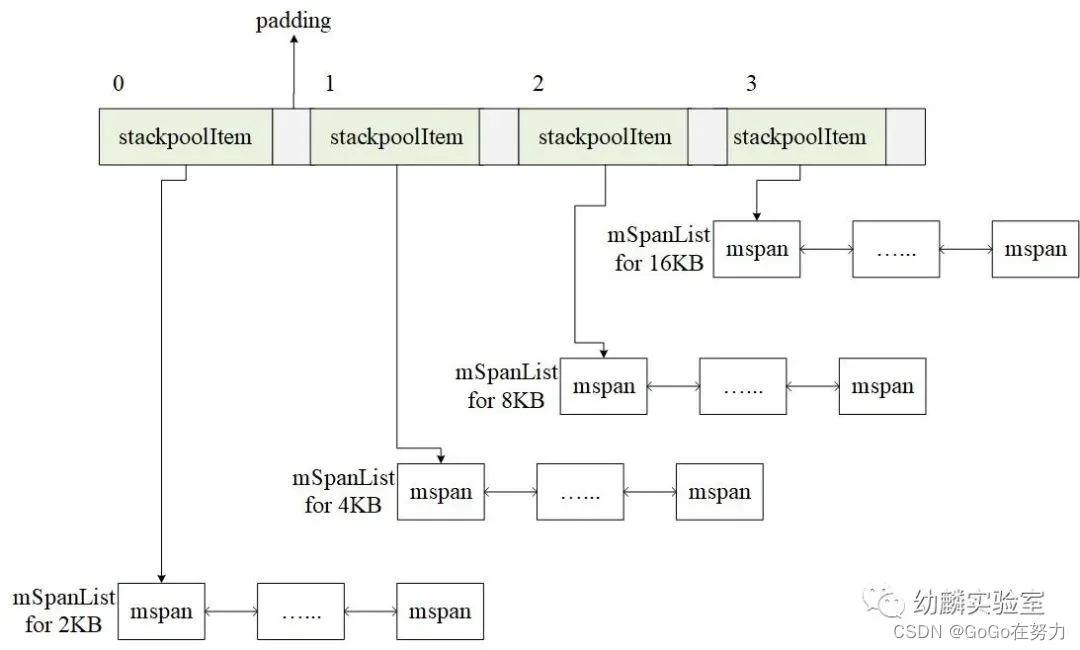
stackpool面向32KB以下的栈分配,栈大小必须是2的幂,最小2KB,在Linux环境下,stackpool提供了2kB、4KB、8KB、16KB四种规格的mspan链表。
2.3stackLarge
var stackLarge struct {
lock mutex
free [heapAddrBits - pageShift]mSpanList
}
大于等于32KB的栈,由stackLarge来分配,这也是个mspan链表的数组,长度为25。
mspan规格从8KB开始,之后每个链表的mspan规格,都是前一个的两倍。
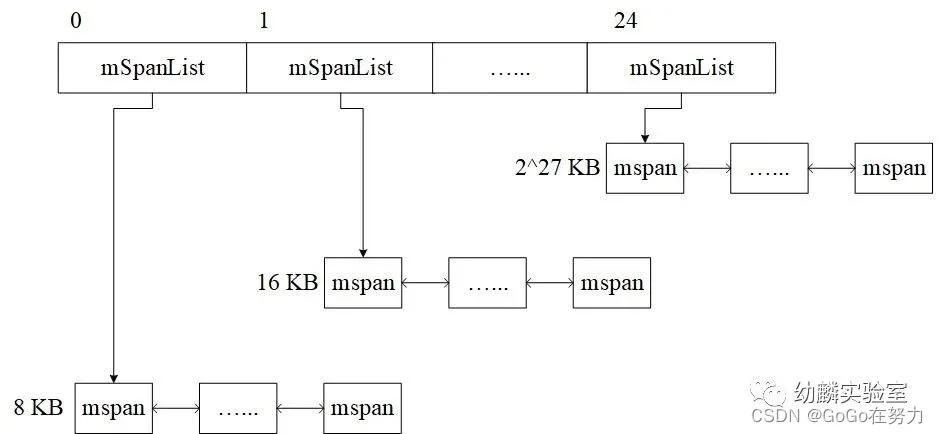
8KB和16KB这两个链表,实际上会一直是空的, 留着它们是为了方便使用mspan包含页面数的(以2为底)对数作为数组下标。

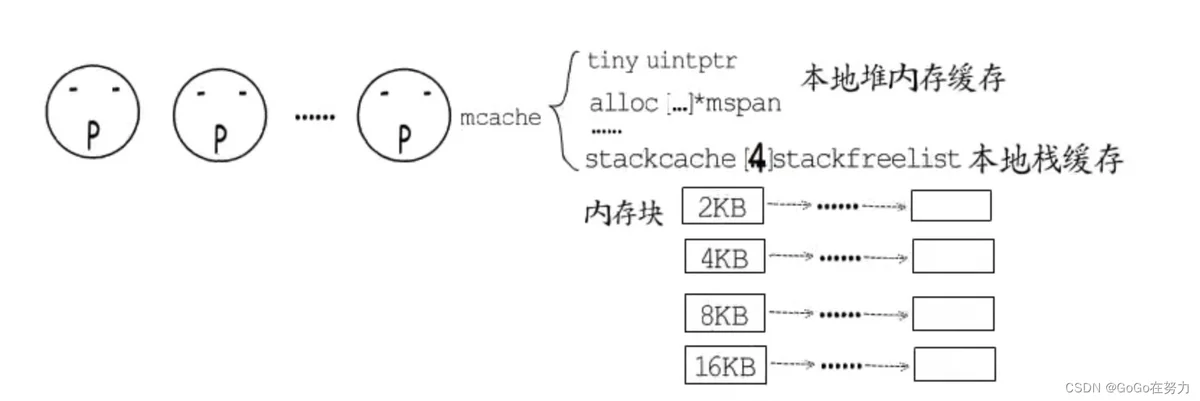
初始化以后,这些链表都还是空的,接下来它们会作为全局栈缓存来使用。同堆内存分配一样,每个P也有用于栈分配的本地缓存(mcache.stackcache),这相当于是stackpool的本地缓存,
type mcache struct {
nextSample uintptr
scanAlloc uintptr
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan
stackcache [_NumStackOrders]stackfreelist
flushGen uint32
}
在Linux环境下,每个P本地缓存有四种规格的空闲内存块链表(2KB,4KB,8KB,16KB)。
3.小于32KB的栈分配
小于32KB的栈分配:
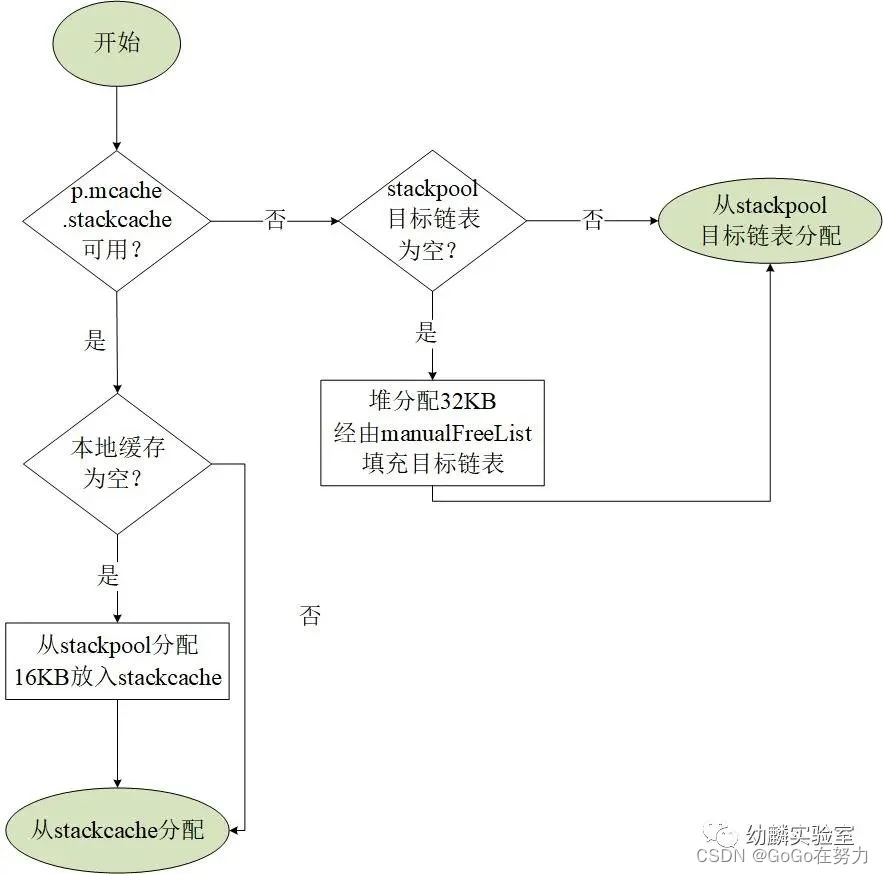
(1)对于小于32KB的栈空间,会优先使用当前P的本地缓存。
(2)如果本地缓存中,对应规格的内存块链表为空,就从stackpool这里分配16KB的内存放到本地缓存(stackcache)中,然后继续从本地缓存分配。
(3)若是stackpool中对应链表也为空,就从堆内存直接分配一个32KB的span划分成对应的内存块大小放到stackpool中。
不过有些情况下,是无法使用本地缓存的,在不能使用本地缓存的情况下,就直接从stackpool分配。
4.大于等于32KB的栈分配
大于等于32KB的栈分配:
如果要分配大于等于32KB的栈空间,就计算需要的page数目,并以2为底求对数(log2page),将得到的结果作为stackLarge数组的下标,找到对应的空闲mspan链表。若链表不为空,就拿一个过来用。
如果链表为空,就直接从堆内存分配一个拥有这么多个页面的span,并把它整个用于分配栈内存;
例如想要分配64KB的栈,68/8是8个page,log2page=log2(8)=3
这就是栈内存分配的大致过程
5.栈增长
栈内存初始分配发生在goroutine创建时,由于初始栈大小都是2KB,在实际业务中可能会不够用,所以需要实现一种在运行阶段动态增长栈的机制。
goroutine的栈增长,是通过编译器和runtime合作实现的,编译器会在函数的头部安插检测代码,检查当前剩余的栈空间是否够用。
闭包函数内部如果需要栈增长的话,会直接调用runtime.morestack(),而一般的函数会调用runtime.morestack_noctxt(),它会先显式的将DX寄存器清零,然后调用morestack()。
morestack()也是一个用汇编语言实现的函数,它会先进行一些检查工作,因为不能增长g0和gsignal的栈,然后它会把调用者的PC、SP等存入g.sched中,然后调用newstack()来增长栈。newstack函数执行流程如下图所示:
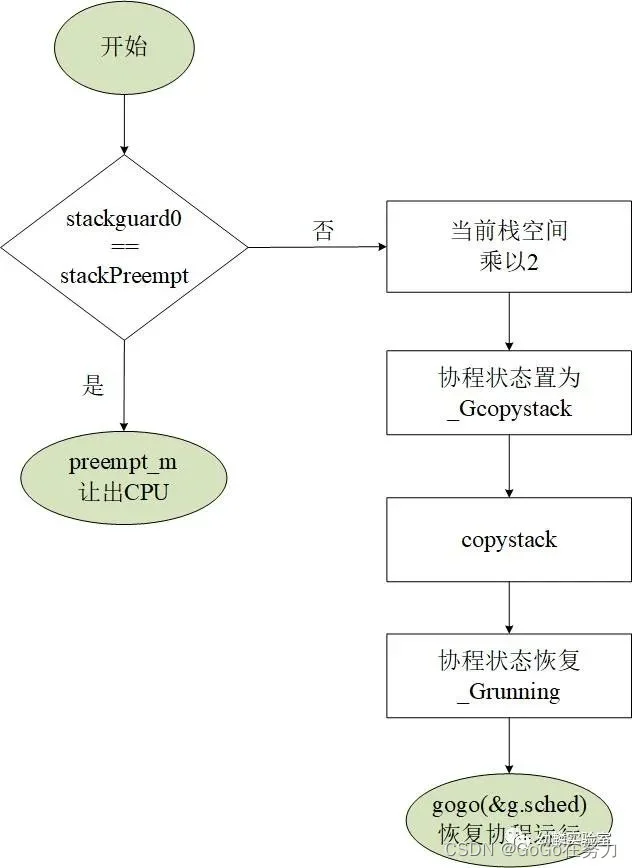
栈空间是成倍增长的,需要增长时,先把当前的栈空间大小乘以2,并把协程状态置为_Gcopystack。接下来调用copystack函数,分配新的栈空间,拷贝旧栈上的数据,释放旧栈空间,最后通过gogo(&g.sched)来恢复协程运行(_Grunning),这就是栈增长的大致逻辑。
6.栈收缩
其实栈不仅能增长,还可以收缩,只是不会缩到比2KB还小就是了。
唯一发起栈收缩的地方就是 GC。GC通过scanstack函数寻找标记root节点时,如果发现可以安全的收缩栈,就会执行栈收缩,不能马上执行时,就设置栈收缩标识(g.preemptShrink = true),等到协程检测到抢占标识(stackPreempt)。在让出CPU之前会检查这个栈收缩标识,为true的话就会先进行栈收缩,再让出CPU。
栈收缩可以减少运行中的协程对栈空间的浪费,但是结束运行的那些协程的栈空间,该怎么回收利用呢?
这得从协程运行结束时说起。
7.栈释放
7.1什么时候释放栈?
我们知道常规goroutine在运行结束时,会被放到调度器对象这里的空闲G队列中(sched.gFree)。这里的空闲协程分两种:
一种有协程栈(sched.gFree.stack)
一种没有协程栈(sched.gFree.noStack)
创建协程时,会先看看这里有没有空闲的协程可以用,优先使用有栈的协程
省得额外再分配。不过,常规goroutine运行结束时都有协程栈,应该进到哪个队列呢?
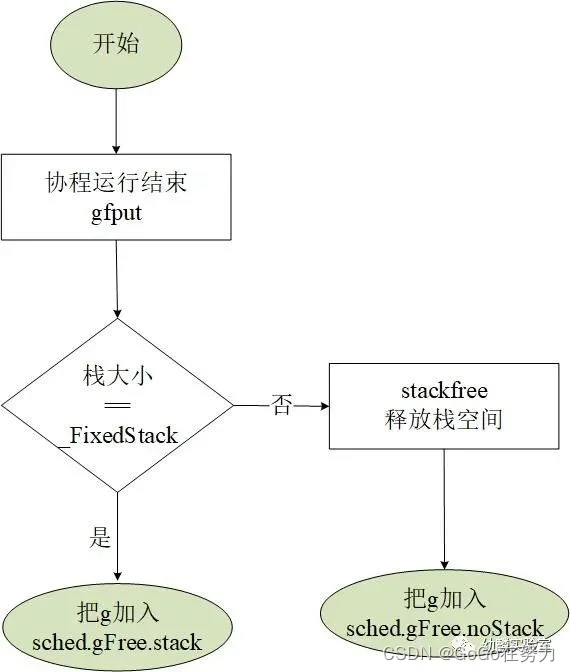
(1)如果协程栈没有增长过(还是2KB),就把这个协程放到有栈的空闲G队列中;
(2)如果协程栈增长过,就把协程栈释放掉,再把协程放入到没有栈的空闲G队列中。
而这些空闲协程的栈,也会在GC执行markroot时被释放掉,到时候这些协程也会加入到没有栈的空闲协程队列中。
所以,常规goroutine栈的释放,一是发生在协程运行结束时,gfput会把增长过的栈释放掉,栈没有增长过的g会被放入sched.gFree.stack中;二是GC会处理sched.gFree.stack链表,把这里面所有g的栈都释放掉,然后把它们放入sched.gFree.noStack链表中。
7.2这些栈释放到了哪里?
协程栈释放时是放回当前P的本地缓存?还是放回全局栈缓存?(stackpool/stackLarge)抑或是直接还给堆内存?
其实都有可能,要视情况而定~
同栈分配时一样,小于32KB和大于等于32KB的栈,在释放的时候也会区别对待。
(1)小于32KB的栈,释放时会先放回到本地缓存中。如果本地缓存对应链表中栈空间总和大于32KB了,就把一部分放回stackpool中,本地这个链表只保留16KB。
如果本地缓存不可用,也会直接放回stackpool中。
而且,如果发现这个mspan中所有内存块都被释放了,就会把它归还给堆内存。
(2)对于大于等于32KB的栈释放,如果当前处在GC清理阶段(gcphase == _GCoff),就直接释放到堆内存,否则就先把它放回stackLarge这里。
这就是栈释放的大致逻辑~
8.总结
这一次我们简单介绍了协程栈的管理,知道了协程栈也是从堆内存分配的,也有全局缓存和本地缓存,同时了解到栈不仅可以增长,还可以收缩,当然也需要释放继而回收利用,关于协程栈的管理就先到这里~