

新智元报道
【新智元导读】谷歌研究人员对自家BERT模型进行了「语法测试」,结果显示,BERT确实学会了遵循「主谓一致」的语法,但并未将其视作规则,而当成了一种偏好。模型的具体表现取决于动词出现的频率和形式。
近年来,预训练的语言模型,如 BERT 和 GPT-3,在自然语言处理 (NLP) 中得到了广泛应用。通过对大量文本进行训练,语言模型获得了关于世界的广泛知识,在各种 NLP 基准测试中取得了强劲的表现。
然而,这些模型通常是不透明的,不清楚这些模型为何表现如此出色,这就限制了对这些模型进行进一步由假设驱动的改进。要搞清楚这个问题,首先要确定这些模型中包含哪些语言知识。
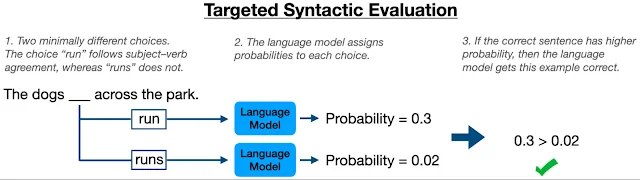
分析这个问题的基础主题是英语中的主谓一致语法规则,要求动词的语法与主语的语法一致。
例如,句子“「The dogs run」符合语法,因为“dogs”和“run”都是复数形式,但「The dogs runs就不合语法,因为「runs」是动词的单数形式,而主语dogs是复数形式。
目标句法评估 (TSE)是评估语言模型的语言知识的一种框架。该框架会向语言模型显示差异最小的句子对,一个合乎语法的,一个不合语法的,模型必须确定哪一个句子合乎语法。
这样,TSE可用于测试英语主谓一致规则的知识。
根据这个原则,在 EMNLP 2021 发表的「Frequency Effects on Syntactic Rule-Learning in Transformers」中,谷歌的研究人员考察了 BERT 模型正确应用英语主谓一致规则的能力,如何受单词出现次数的影响模型在预训练期间看到的。

为了测试特定条件,研究人员使用精心控制的数据集,从头开始预训练 BERT 模型。结果发现,BERT在预训练数据中没有一起出现的主谓对句子上取得了良好的表现,这表明模型确实学会了应用主谓一致。
不过,当错误的语法形式比正确形式出现得更频繁时,模型倾向于预测错误形式,这表明 BERT 没有将语法一致性视为必须遵循的规则。这些结果有助于研究人员更好地了解预训练语言模型的优势和局限性。
先前工作回顾:「自然句」与「人造句」

以前,研究人员使用 TSE 来衡量 BERT 模型遵守英语语法中主谓一致的能力。给定动词的单数和复数形式(「runs」和「run」),如果模型正确地学会了应用主谓一致规则,那么它应该始终为使句子在语法上正确的动词形式分配更高的概率。
之前的研究使用「自然句」和「人造句」对 BERT 进行评估,后者是人为构造的语法正确、但在语义上无意义的句子。
这种人造句在测试模型语法能力时很有用,因为模型不能仅仅要依靠表面的语料库统计数据。比如「dogs run」比「dogs running」更常见,但「dogs publish」和「dogs publishes」都是非常罕见的,因此模型不可能简单地记住某些句子出现概率更高这一事实。
BERT 在「人造句」上实现了超过 80% 的准确率(远好于 50% 的随机基线水平),这可以视作模型已经学会应用主谓一致规则的证据。
而在这篇新发表的论文中,研究人员通过在特定数据条件下预训练 BERT 模型,超越了之前的水平,可以更深入地研究这些结果,了解预训练数据中的某些模式如何影响BERT的性能。
没见过的「主语-动词」对
研究人员首先研究了模型在预训练期间在主语-动词对上的表现,以及主语和动词未出现在同一个句子中的示例的表现:
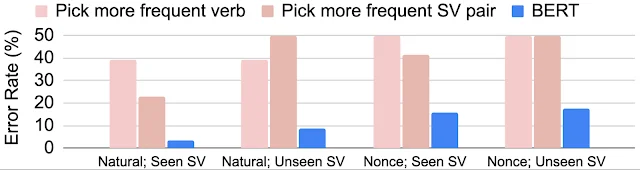
BERT 在「自然句」和「人造句」评估上的错误率,根据训练期间是否在同一句子中看到特定的主谓 (SV) 对进行分层。
BERT 的错误率在看不见的主谓句子对时略有增加,但它的表现仍然比朴素的启发式算法好得多,这表明,BERT模型不是只能简单反应其看到的东西,它能够实际学会主谓一致的语法规则。
动词出现频率对BERT性能的影响
接下来,研究人员考察单词的出现频率对BERT正确使用主谓一致规则的影响。
研究人员选择了一组 60 个动词,然后创建了多版本的预训练数据,每个版本都设计为包含特定频率的 60 个动词,确保单复数形式出现相同的次数。然后从这些不同的数据集中训练BERT模型,并在主谓一致任务上对其进行了评估:
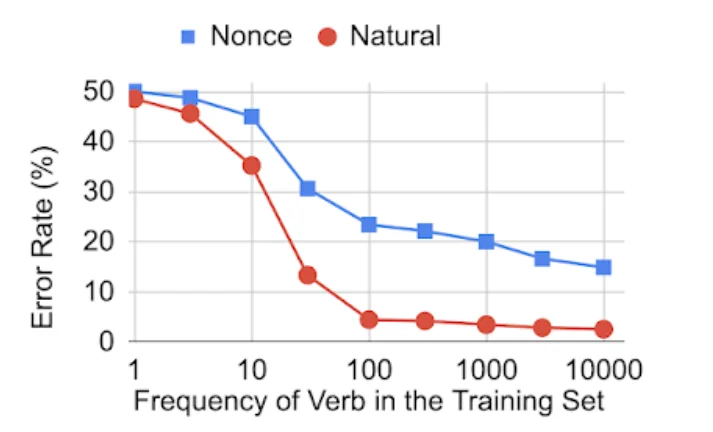
BERT 遵循主谓一致规则的能力,取决于训练集中动词出现的频率
这些结果表明,虽然 BERT 能够对主谓一致规则进行建模,但它需要看到一个动词大约 100 次才能可靠地将它与规则一起使用。
动词形式差异对BERT的影响
最后考察动词单复数形式的相对频率如何影响 BERT 的预测。例如,如果动词的一种形式(如combat)比另一种动词形式(combats)出现在预训练数据中的频率高得多,那么 BERT 可能更有可能分配一个高概率到更频繁的形式,即使它在语法上不正确。
为了评估这个指标,再次使用相同的 60 个动词,但这次创建了预训练数据的改动版本,动词形式之间的频率比从 1:1 到 100:1 不等。下图显示了 BERT 在这些不同级别的频率不平衡下的性能:
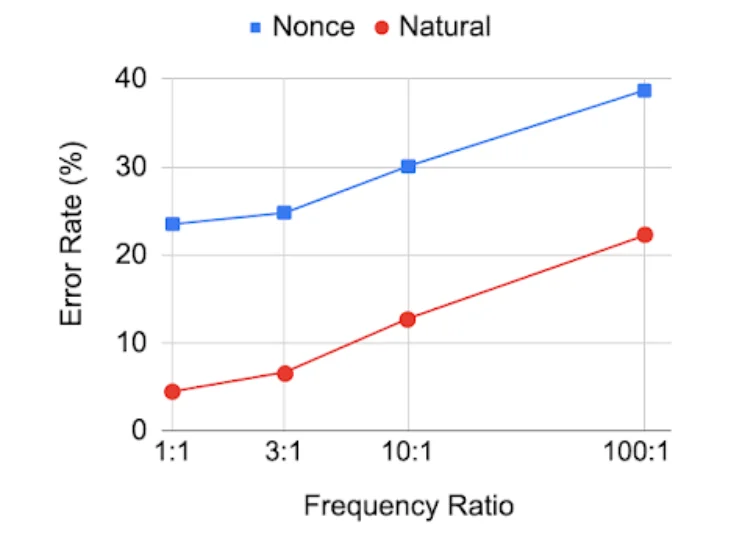
可见,随着训练数据中动词形式之间的频率比变得更加不平衡,BERT 在合乎语法地使用这些动词的能力出现了下降。
这些结果表明,当两种形式在预训练期间被模型看到相同的次数时,BERT 在预测正确的动词形式方面取得了良好的准确性,但随着动词出现频率的差异增加,模型性能会逐步下滑。
这意味着,即使 BERT 已经学会了如何应用主谓一致性,它也不一定将其当做一个「规则」,而是更倾向于预测高频词,不管它们是否违反了主谓一致性。
结论
本研究使用 TSE 来评估 BERT 的性能,揭示了模型在语法任务上的语言能力。此外还揭示了 BERT 处理判断任务优先级的方式:模型知道主语和动词应该一致,面对高频词时尤为如此,但模型不理解这种一致是必须遵循的规则,而只是当成一种偏好。
研究人员希望,这项工作会对语言模型反映训练数据集的属性方面提供新的见解。
参考资料:
https://ai.googleblog.com/2021/12/evaluating-syntactic-abilities-of.html
https://arxiv.org/pdf/1901.05287.pdf
https://arxiv.org/abs/2109.07020