
布尔型的值只可以是true或者false。
在golang中,布尔类型只占一个字节。
适用于 逻辑运算,一般用于程序 流程控制 和 条件判断。Go 语言 bool 类型 的 true 表示条件为真, false 表示条件为假。并且==和<等比较操作也会产生布尔型的值。
由于Golang是静态编译语言,不是Python这种的动态语言,所以可以认为当你的变量定义后,类型就是固定不变了,不像动态语言那样可以变来变去,所以肯定是相同类型之间才可以进行比较。
当变量的类型是接口(interface),则他们之间必须都实现了相同的接口。
所谓的变量类型相同,包括常量和非常量之间的比较也是可以的。
数字类型数字类型包含以下的类型:
uint8: 无符号8位整形(0~255)
uint16: 无符号16位整形(0~65535)
uint32: 无符号32位整形(0~4294967295)
uint64: 无符号64位整形(0~18446744073709551615)
int8: 有符号8位整形(-128~127)
int16: 有符号16位整形(-32768~32767)
int32: 有符号32位整形(-2147483648~2147483647)
int64: 有符号64位整形(-9223372036854775808~9223372036854775807)
float32: IEEE-754 32位浮点型数
float64: IEEE-754 64位浮点型数
complex64: 32位实数和虚数
complex128: 64位实数和虚数
byte: 和uint8等价,另外一种名称
rune: 和int32等价,另外一种名称
uint: 32位或64位的无符号整型,与操作系统有关(32/64)
int: 32位或64位的有符号整型,与操作系统有关(32/64)
uintptr: 无符号整形,用于存放一个指针
Golang的数据类型中支持整形与浮点型数字,而且原生的就支持复数,这是较其他语言的一个优势,其中位的运算采用补码。
在上面的记录的类型中,int、uint是根据操作系统决定的,当操作系统是32位时,int和uint的长度都是32位,当操作系统是64位时,int和uint的长度都是64位。
uintptr是无符号整型,用户存放指针,也是根据操作系统来决定长度的。
字符串类型字符串是由一串固定长度的字符连接起来的字符序列。Go语言的字符串是由单个字节连接起来的,也就是说对于传统的字符串是由字符组成的,而Go的字符串不同,它是由字节组成的。
Go语言中的字符串的字节使用UTF-8编码来表示Unicode文本。UTF-8是一种被广泛使用的编码格式,是文本文件的标准编码。包括XML和JSON在内都使用该编码。
维基百科:UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用一至四个字节对Unicode字符集中的所有有效编码点进行编码,属于Unicode标准的一部分,最初由肯·汤普逊和罗布·派克提出。[2][3]由于较小值的编码点一般使用频率较高,直接使用Unicode编码效率低下,大量浪费内存空间。UTF-8就是为了解决向后兼容ASCII码而设计,Unicode中前128个字符,使用与ASCII码相同的二进制值的单个字节进行编码,而且字面与ASCII码的字面一一对应,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字优先采用的编码方式。
维基百科:Unicode,联盟官方中文名称为统一码[1],台湾官方中文名称为万国码[2][3],也译为国际码、单一码,是计算机科学领域的业界标准。它整理、编码了世界上大部分的文字系统,使得电脑可以用更为简单的方式来呈现和处理文字。
Unicode伴随着通用字符集的标准而发展,同时也以书本的形式[4]对外发表。Unicode至今仍在不断增修,每个新版本都加入更多新的字符。目前最新的版本为2021年9月公布的14.0.0[5],已经收录超过14万个字符(第十万个字符在2005年获采纳)。Unicode除了视觉上的字形、编码方法、标准的字符编码资料外,还包含了字符特性(如大小写字母)、书写方向、拆分标准等特性的资料库。
由于UTF-8编码占用字节长度的不确定性,所以在Go语言中,字符串也需要占用1~4字节,这与其他编程语言,如C++、Java或者Python不同(Java始终使用2字节)。
Go语言这种解决方案不仅减少了内存和硬盘空间占用,而且也不像其他语言那样需要对使用UTF-8字符集的文本进行编码和解码。
字符串的声明和初始化
str := "hello string"
上面的代码声明了字符串变量str,内容为"hello string"
字符的转义
在Golang中,字符串的创建允许使用双引号(")或者反引号(`)来创建。
当然还有字符串的单引号。
双引号
双引号用来创建可解析的字符串,支持转义,但不能用来引用多行。
双引号中定义的字符串将支持转义字符。比如\n将输出换行。
这与python中的str类型比较相似
反引号
用反引号编码的字符串是原始文本字符串,不接受任何形式的转义。原生的字符串字面量多用于书写多行消息、HTML以及正则表达式。可以表示除了反引号外的所有字符。
这有些类似于python中(r’’)的结构。
单引号
单引号用来定义一个 byte或者rune。
Go语言中byte和rune实质上就是uint8和int32类型。
byte用来强调数据是raw data,而不是数字;
而rune用来表示Unicode的code point。
当我们定义 byte时必须要指定类型,如果不指定类型,默认为 rune。一个单引号只允许一个字符。
字符的连接
Golang的字符是不可改变的,但是字符串支持级联操作(+)和追加操作(+=)。
百度百科:重复性的操作十分烦琐,尤其是在处理多个彼此关联对象情况下,此时我们可以使用级联(Cascade)操作。级联 在关联映射中是个重要的概念,指当主动方对象执行操作时,被关联对象(被动方)是否同步执行同一操作。
级联还指用来设计一对多关系。例如一个表存放老师的信息:表A(姓名,性别,年龄),姓名为主键。还有一张表存放老师所教的班级信息:表B(姓名,班级)。他们通过姓名来级联。级联的操作有级联更新,级联删除。 在启用一个级联更新选项后,就可在存在相匹配的外键值的前提下更改一个主键值。系统会相应地更新所有匹配的外键值。如果在表A中将姓名为张三的记录改为李四,那么表B中的姓名为张三的所有记录也会随着改为李四。级联删除与更新相类似。如果在表A中将姓名为张三的记录删除,那么表B中的姓名为张三的所有记录也将删除。
字符串的操作符
字符串的内容(纯字节)可以通过标准索引进行获取,例如在方括号[]内写入索引,索引从0开始。
通过下面的示例,可以理解字符串的常用方法:
str := "programming"
fmt.Println(str[1]) //获取字符串索引位置为1的原始字节,比如r为114
fmt.Println(str[1:3]) //截取字符串索引位置为1和2的字符串(不包括最后一个)
fmt.Println(str[1:]) //截取字符串索引位置为1到len(str)-1的字符串
fmt.Println(str[:3]) //截取字符串索引位置为0到2的字符串(不包括3)
fmt.Println(len(str)) //获取字符串的字节数
fmt.Println(utf8.RuneCountInString(str)) //获取字符串的字符个数
fmt.Println([]rune(str)) //将字符串的每一个字节转换为码点值
fmt.Println(string(str[1])) //获取字符串索引位置为1的字符值
以上代码的运行结果如下:
114
ro
rogramming
pro
11
11
[112 114 111 103 114 97 109 109 105 110 103]
r
可以发现当使用索引取出指定单个位置的字符时,取出的是原始字节,也就是码点值。
Unicode码点对应Go语言中的rune整数类型。
倒数第四句和倒数第三句虽然都是11,但是代表的含义不同,上面提到过golang中不像其他语言定宽表示字符,是1~4个字节变宽,所以同样的11个字符,内容改变,可能使用len()得到的字节数超过11,而字符就是字面意思,依然保持为11。
字符串的比较
Golang的字符串支持常规的比较操作(<, >, ==< !=, <=, >=),在进行比较时,实际上是对内存中的原始数据字节进行逐个比较,因为当两个字符串的内容完全相同时,其内部字节也必是完全相同的,这是编码决定的。
字符串的遍历
通常情况下可以通过索引提取字符,例如:
str := "go web"
fmt.Println(string(str[0])) //获取索引值为0的字符
但是这种方式存在一定的风险,因为并非所有的字符串都是单字节的,如果是多字节的字符使用这种方式显然并不是太理想,因为取出的数据并不完整。
所以在应用时更常使用的是字符串切片,这样返回的就是一个字符,或者可以这么理解,字符串切片返回的单位是字符,可能返回的字节数是一个,也可能是多个,而第一种方法返回的单位是字节,返回的结果可能是一个完整的字符,也可能是一个字符的一部分字节。
str := "i love go web"
chars := []rune(str) //把字符串转为rune切片
for _, char := range chars {
fmt.Println(string(char))
}
这里的fmt.Println()中的Println是Print和line的组合,所以在打印时会自动换行,不用手动添加。
遍历
如果要将字符串一个一个字符的迭代出来,可以通过for-range循环:
str := "love go web"
for index, char := range str{
fmt.Printf("%d %U %c \n",index, char, char)
}
累加
直接使用运算符
由于golang的字符串是不可改变的,这是最开始就说了的,所以当简单的使用+=或者+进行累加时,会生成很多的临时无用字符串,当涉及的字符串长度越大时,这一情况越发严重,所以在处理大批量数据的字符串时,这并不是十分建议的。
fmt.Sprintf()
内部使用 []byte 实现,不像直接运算符这种会产生很多临时的字符串,但是内部的逻辑比较复杂,有很多额外的判断,还用到了 interface,所以性能也不是很好
而且最重要的是在一些场景下并不是很实用,这是很容易理解的。
strings.Join()
join会先根据字符串数组的内容,计算出一个拼接之后的长度,然后申请对应大小的内存,一个一个字符串填入,在已有一个数组的情况下,这种效率会很高,但是本来没有,去构造这个数据的代价也不小
a := "hahaha"
b := "hehehe"
c := strings.Join([]string{a,b},",")
println(c)
buffer.WriteString()
这个比较理想,可以当成可变字符使用,对内存的增长也有优化,如果能预估字符串的长度,还可以用 buffer.Grow() 接口来设置 capacity
hello := "hello"
world := "world"
for i := 0; i < 1000; i++ {
var buffer bytes.Buffer
buffer.WriteString(hello)
buffer.WriteString(",")
buffer.WriteString(world)
_ = buffer.String()
}
strings.Builder()
不过使用bytes模块来操作string难免让人产生迷惑,所以在go1.10中新增了第三种方法:strings.Builder,官方鼓励尽量在string的拼接时使用Builder,byte拼接时使用Buffer
// strings.Builder的0值可以直接使用
var builder strings.Builder
// 向builder中写入字符/字符串
builder.Write([]byte("Hello"))
builder.WriteByte(' ')
builder.WriteString("World")
// String() 方法获得拼接的字符串
builder.String() // "Hello World"
从上面的代码中可以看到,strings.Builder和bytes.Buffer的操作几乎一样,不过strings.Builder仅仅实现了write类方法,而Buffer是可读可写的。
所以strings.Builder仅用于拼接/构建字符串
Buffer和Builder性能相差无几,Builder在内存的使用上要略优于Buffer
字符串的修改
在Golang中,字符串类型是不可以修改的,所以不能像其他语言那样通过str[i]这样的方式进行修改,想要修改时只能先复制到可写的[]bute或者[]rune中,然后再进行修改,Golangf中进行修改时会自动复制数据。
修改字节([]byte)
如果是单字节的,可以使用这种方式,但是注意!!!Golang的字符串不是定宽的,是1~4个字节,所以当涉及到多字节的字符时,就会发生问题了。
str := "Hi 世界! "
by := []byte(str) //转换为[]byte,数据被自动复制
by[2] = ',' //把空格改为半角逗号
修改字符([]rune)
str := "Hi 世界"
by := []rune(str) //转换为[]rune,数据自动复制
by[3] = '中'
by[4] = '国'
指针类型介绍
指针类型是指变量存储的是一个内存地址的变量类型/如下的使用示例:
var b int = 66 //定义一个普通类型(int)
var p * int = &b //定义一个指针类型
指针的使用
%p&*数组类型
相同唯一类型声明数组
Goalng的数组声明需要制定元素类型和元素个数,语法格式如下:
var name[size] type
name: 数组名
size: 声明数组的元素个数,或者也可以说数组长度
type: 声明数组的类型,例如int
初始化数组
初始化数组的示例如下:
var nums = [5]int32(100, 8, 9, 6, 20)
{}[]...{}var nums = [...]int{100, 9, 8, 7, 6}
这里的数组的长度也依然是5.
访问数组元素
在访问数组元素时,可以直接使用索引进行访问
数组的使用
golang中的数组是这样说的: Arrays are values, not implicit pointers as in C.
数组做参数时, 需要被检查长度.
变量名不等于数组开始指针!
不支持C中的*(ar + sizeof(int))方式的指针移动. 需要使用到unsafe包
如果p2array为指向数组的指针, *p2array不等于p2array[0]
数组做参数时, 需要被检查长度
func use_array(args [4]int) {
args[1] = 100
}
func main() {
var args = [5]int{1, 2, 3, 4, 5}
use_array(args)
fmt.Println(args)
}
cannot use args (type [5]int) as type [4]int in argument to use_array变量名不等于数组开始指针
func use_array(args [5]int) {
args[1] = 100
}
func main() {
var args = [5]int{1, 2, 3, 4, 5}
use_array(args)
fmt.Println(args)
}
输出结果:[1 2 3 4 5]
因为这里的数组名不再是数组开始的指针,所以这里传入的不再是地址,而是数组的一份拷贝,所以在复制的数组内进行值的改变并不会影响原地址的数组内的值。
// 有长度检查, 也为地址传参
func use_array(args *[4]int) {
args[1] = 100 //但是使用还是和C一致,不需要别加"*"操作符
}
func main() {
var args = [4]int{1, 2, 3, 4}
use_array(&args) // 数组名已经不是表示地址了, 需要使用"&"得到地址
fmt.Println(args)
}
&结构体类型(struct)
结构体介绍
集合0个多个任意类型成员拥有自己的类型和值
成员名必须唯一
成员的类型也可以是结构体,甚至是成员所在结构体的类型
使用关键字type,可以讲各种基本类型定义为自定义类型。
基本类型包括整形、字符串、布尔等。
结构体是一种复合的基本类型,通过type定义为自定义类型,可以使结构体更便于使用。
结构体的定义
语法如下:
type 类型名 struct {
成员1 类型1
成员2 类型2
//。。。
}
含义:
自定义type 类型名 struct{}当一个结构体被定义后,就可以像使用其他数据类型那样对其进行变量的定义、初始化等操作。因为他也是数据类型的一种,区别在于int、float这些是Golang定义好的,自定义结构体是你自定义出来的。
访问结构体成员
.结构体.成员名
结构体作为函数参数
既然已经说了自定的结构体类型也是一种数据类型,那么当然也是支持像其他数据类型那样当作参数传入函数内部使用。
结构体指针
与其他数据类型一样,结构体也可以使用指针,一般称为结构体指针,定一语法如下:
type Books struct {
title string
author string
subject string
press string
}
var structPoint *Books
以上定义的指针变量可以存储结构体变量的内存地址。
&.切片类型
片段片段切片的结构体由3部分构成,
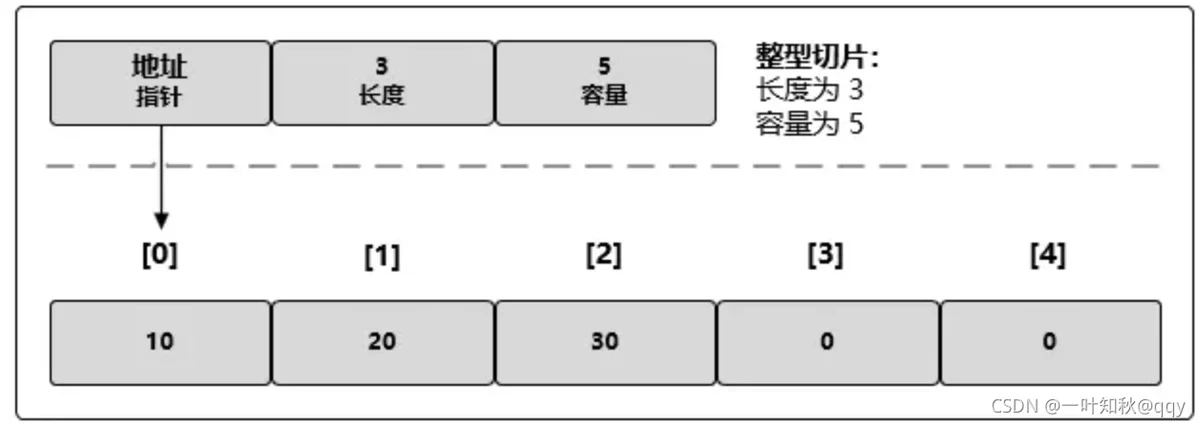
地址指针(pointer):指向一个数组的指针
长度(len):代表当前切片的长度
容量(cap):当前切片的容量
cap的总是大于等于len。
切片默认指向一段连续内存区域,可以使数组,也可以是切片本身。从连续内存区域生成切片是常见的操作。
语法:
slice [开始位置:结束位置]
含义:
slice: 目标切片对象
开始位置:对应目标切片对象的起始索引
结束位置:对应目标切片的结束索引
例子:
var a = [3]int{1, 2, 3}
fmt.Println(a, a[1:2])
从数组或切片生成新的切片拥有如下特性:
取出的元素数量为 “结束位置-开始位置”
取出元素不包含结束位置对应的索引,切片最后一个元素使用slice[len(slice)]获取;
如果缺省开始位置,则表示从连续区域开头到结束位置
如果缺省结束位置,则表示从开始位置到整个区域的末尾
如果两者同时缺省,则新生成的切片与原切片等效
如果两者同时为0,则等效于空切片,一般用于切片复位
在根据索引位置取切片slice元素值时,取值范围是(0~len(slice) - 1)。如果超界,则会报运行时错误。在生成切片时,结束位置可以填写len(slice),不会报错。
从指定范围中生成切片
切片和数组密不可分。如果将数组理解为一栋办公楼,那么切片就是把不同的连续楼层出租给使用者。在出租过程中需要选择开始楼层和结束楼层,这个过程就会生成切片。
切片的使用有点像C语言里的指针,但是C的指针可以做运算,但是有内存越界的风险,所以c的指针既是高效的东西但是也存在风险。
切片在指针的基础上增加了大小,约束了切片对应的内存区域。在切片使用过程中,无法对切片内部的地址和大小进行手动调整,因此切片比指针更安全、强大。
表示原有的切片
如果开始位置和结束位置都被忽略,则新生成的切片与原有切片一模一样,并且生成的切片与原切片在数据内容上也是一致的。
b := []int{6, 7, 8}
fmt.Println(b[:])
输出:
[6, 7, 8]
充值切片,清空拥有的元素
如果把切片的开始和结束位置都设置为0,则生成的切片将变空
b := []int{6, 7, 8}
fmt.Println(b[0:0])
输出:
[]
直接声明新的切片
除了可以从原有的数组或者切片中生成新的切片外,当然也是支持直接声明新的切片。其他类型也可以声明为切片类型,用来表示多个相同类型元素的连续集合。因此,切片类型也可以被声明。
语法如下:
var name []Type
其中name表示切片的变量名,Type表示切片的元素类型。
还记得数组是如何声明的吗
var name [10]string
var name = [...]string{"sss", "fff", "fff"}
对比下切片的声明:
var name [string]
var name = []string{"djeda", "fjeaf", "fdhadha"}
这是不是非常清晰,二者语法十分相近,只不过切片在声明时,方括号内部是空的,而数组是非空的。
map类型
map定义
元素对(pair)关联数组字典var name map[key_type]value_type
其中,name为map的变量名,key_type为键类型,value_type为健对应的值的类型。
在[key_type]和value_type之间允许有空格。
map可以动态增长,为初始化时,map的值为nil,使用len()可以获取map中的键值对的数目。
可以使用make()函数来构造map,但不能使用new()函数来构造map。
如果错误的使用new()函数分配了一个引用对象,则会获得一个空引用的指针,相当于声明了一个未初始化的变量,并取了它的地址。
map容量
与数组不同,map可以根据新增的元素对来动态的伸缩,因此不存在固定长度或者最大限制。
但是可以标明map的初始容量capacity。
语法如下:
make(map[key_type]value_type, cap)
当map容量增长到容量上限时,如果在增加新的元素对,则map的大小会自动加一,所以出于性能的考虑,对于map的大数据量或者扩充快的,最后实现注明容量。
这时会在定义时,直接申请这么大的容量,虽然可能不用,但是如果不这样做,就会在每次增加时进行内存的申请。
切片作为map的值
可以将value定义为切片类型,例如[]int等,就可以实现一个key对应一组值,这和python内的dict的value为list相同。
同理在切片内也可以嵌套map,形成复杂的数据结构。
但是在数据量大时,并不建议这么做,这时处于性能的考虑。