
一、Lex & Yacc简介
Lex & Yacc 是用来生成词法分析器和语法分析器的工具,与GNU用户所熟知Flex&Bison所对应(Flex是由Vern Paxon实现的一个Lex,Bison则是GNU版本的YACC)。除了编译器领域,Lex & Yacc对于DSL或者SQL解析领域也大有用处。
Lex (A Lexical Analyzer Generator)用于生成词法分析器,用于把输入分割成一个个有意义的词块(称为token)。
Yacc(Yet Another Compiler-Compiler)用于生成语法解析器,用于确定上述分隔好的token之间的关联。
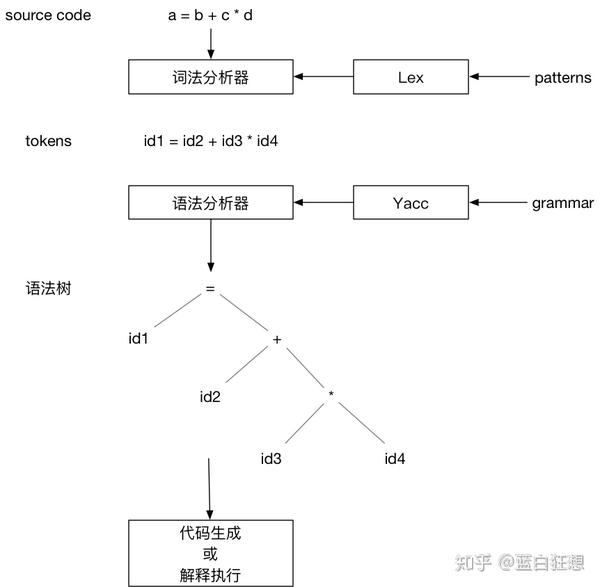
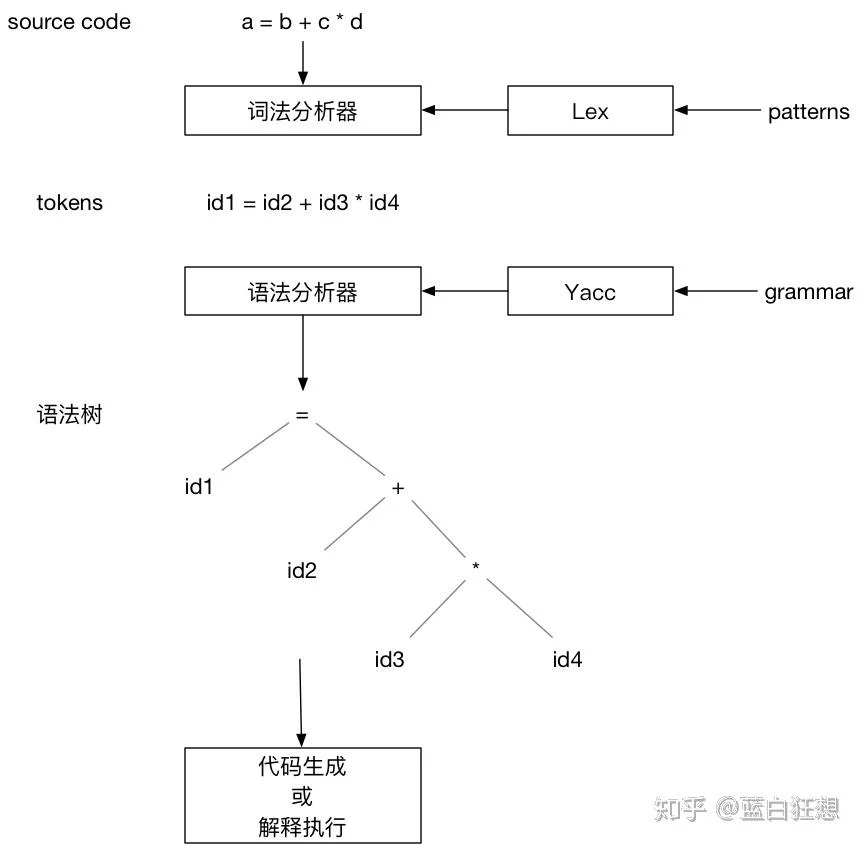
下图描述了整个处理的流程:
- Lex根据输入的patterns生成词法分析器。
- 词法分析器根据patterns将输入的源代码转换为tokens输出。
- Yacc根据定义的语法规则,生成语法分析器。
- 语法分析器根据语法规则,并以tokens为输入,创建出语法树。
二、词法分析器
词法分析器用于获取一个token流。通过调用yylex()读取输入,然后返回相应的token,之后循环调用,持续返回解析好的token。每个token有两部分组成:
- token类型,一个整数值。该值为yylex()的返回值。
- token取值。结果保存到yylval中。
如下是计算器词法分析器的规则定义。该定义由三部分组成,由%%分隔。
- 第一部分为声明部分。%{、%}之间的代码,会被原样拷贝到C文件中。其中定义了token类型,以及token值的变量
- 第二部分模式匹配部分。每行开头是匹配的模式,接着是要执行的代码。
- 例如,[0-9]+行表示:当匹配为数字时,则转换成整型复制给yylval,并返回token类型为NUMBER。
- 第三部分为主程序代码,负责调用词法分析函数yylex(),并输出结果。
// 计算器词法分析器
%{
enum yytokentype {
NUMBER = 258,
ADD = 259,
SUB = 260,
MUL = 261,
DIV = 262,
ABS = 263,
EOL = 264
};
int yylval;
%}
%%
"+" {return ADD;}
"-" {return SUB;}
"*" {return MUL;}
"/" {return DIV;}
"|" {return ABS;}
[0-9]+ {yylval = atoi(yytext); return NUMBER;}
\n {return EOL;}
[ \t] {/*忽略空白字符*/}
%%
main(int argc, char **argv) {
int tok;
while(tok = yylex()) {
printf("%d", tok);
if (tok == NUMBER) {
printf(" = %d\n", yylval);
} else {
print("\n");
}
}
}
// 运行
/// 输入:
34 + 45
/// 输出:
258 = 34
259
258 = 45三、语法分析器
语法分析器用于找出输入token之间的关系,使用巴科斯范式(BNF, Backus Naur Form)来书写。同词法分析器规则一样,也是三部分组成。
- 声明部分:
- %{、%}声明部分原样拷贝到C文件。
- %token声明,用于告诉yacc在语法分析程序中token的类型。任何没有声明为token的语法符号,必须出现在至少一条规则的左边。
- 规则部分:通过BNF定义规则。每一条规则中语法符号都有一个语义值。
- 目标符号(冒号左边的语法符号)用$$代替。
- 右边语法符号的语义值以此用$1 $2代替。
- C代码部分
样例:
%{
#include <stdio.h>
%}
/*declare tokens*/
%token NUMBER
%token ADD SUB MUL DIV ABS
%token EOL
%%
calclist: /*空规则*/
| calclist exp EOL { printf("= %d\n", $2); }
;
exp: factor defalut $$ = $1
| exp ADD factor { $$ = $1 + $3; }
| exp SUB factor { $$ = $1 - $3; }
;
factor: term default $$ = $1
| factor MUL term { $$ = $1 * $3; }
| factor DIV term { $$ = $1 / $3; }
;
term: NUMBER default $$ = $1
| ABS term { $$ = $2 >=0 ? $2 : - $2; }
;
%%
main(int argc, char **argv) {
yyparse();
}
yyerror(char *s) {
fprintf(stderr, "error: %s\n", s);
}四、yacc语法规范
整体结构
由三部分组成,其中前两部分必须。
...定义部分...
%%
...规则部分...
%%
...用户子程序...符号
由词法分析器产生的符号称为终结符或者token。
在规则左侧定义的的符号称为非终结符。
定义部分
%start somename规则部分
包括语法规则和语义动作代码。动作即yacc匹配语法中的一条规则时之行的代码。例如:
date: month '/' day '/' year { $$ = sprintf("date %d-%d-%d", $1, $3, $5); }用户子程序
原样被拷贝到C文件的代码片段。
移进/归约
移进(shift):语法分析器读取token时,当读取的token无法匹配一条规则时,则将其压入一个内部堆栈(union为压入堆栈的结构体),然后切换到一个新的状态,这个新的状态能够反映出刚刚读取的token。
归约(reduction):当发现压入的token已经能够匹配规则时,则把匹配的符号从堆栈中取出,然后将左侧符号压入堆栈。
fred = 12 + 13// 规则
statement: NAME '=' expression
expression: NUMBER + NUMBER
// 处理过程
fred
fred =
fred = 12
fred = 12 +
fred = 12 + 13 //匹配expression: NUMBER + NUMBER,可以归约
fred = expression //匹配statement: NAME '=' expression
statement但是如果引入乘法后,可能会产生冲突,造成如下不同的语法结构。
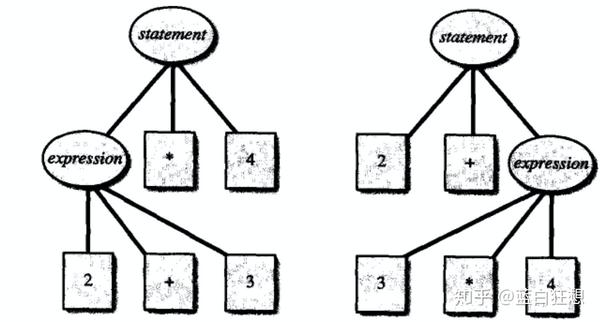
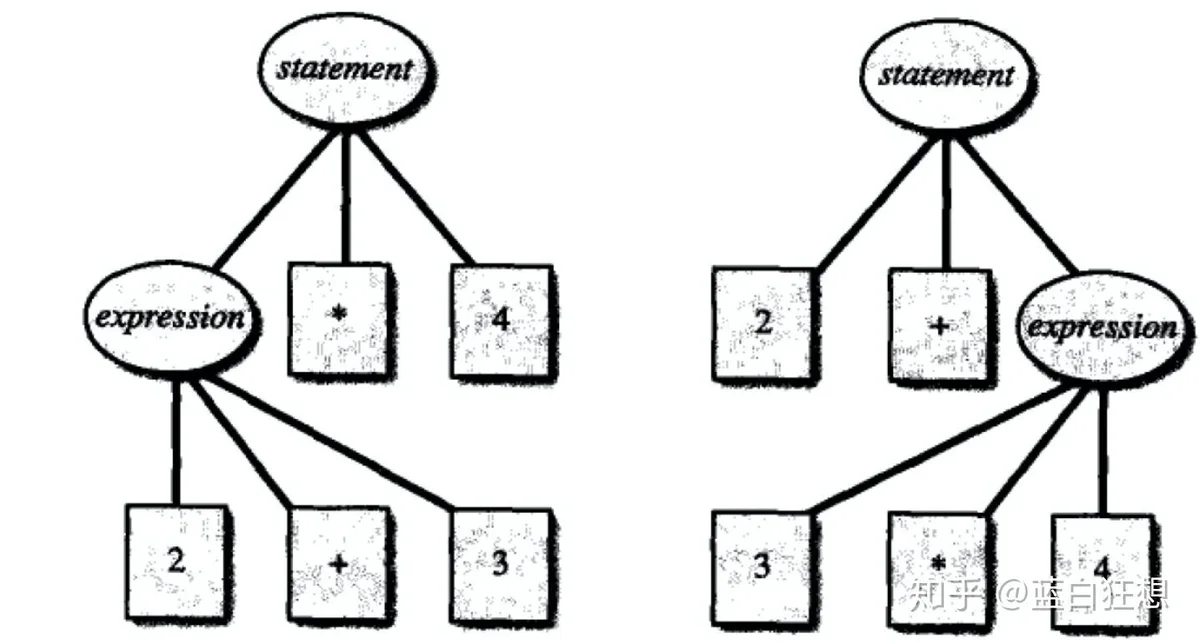
对于这种情况需要显示指定优先级和结合性来解决冲突:
- 优先级:决定了那个操作符先执行。例如,乘除法的优先级高于加减法。
- 结合性:表示具有相同优先级的操作符的结合顺序。
- 自左向右: a-b-c等价于(a-b)-c。
- 自右向左:a=b=c等价于a=(b=c)。
// 意义:+ - * /都是左结合,* /的优先级高于+ -。
%left '+' '-'
%left '*' '/'五、goyacc
YaccYaccgoyaccgoyaccyyParsetype yyLexer interface {
Lex(lval *yySymType) int
Error(e string)
}或者
type yyLexerEx interface {
yyLexer
// Hook for recording a reduction.
Reduced(rule, state int, lval *yySymType) (stop bool) // Client should copy *lval.
}Lex应该返回token类型,并将token值放到放在lval中(与yacc的yylval对应)。Error相当于原yacc中的yyerror。
六、goyacc样例
电话号码解析
- 功能实现
- 支持电话号码4085551212、408-555-1212解析。
- 语法解析器定义parser.y
# 定义部分
%{
package jsonparser
func setResult(l yyLexer, v Result) {
l.(*lex).result = v
}
%}
%union{
result Result
part string
ch byte
}
%token <ch> D
%type <result> phone
%type <part> area part1 part2
%start main
%%
# 规则部分
main: phone
{
setResult(yylex, $1)
}
phone:
area part1 part2
{
$$ = Result{area: $1, part1: $2, part2: $3}
}
| area '-' part1 '-' part2
{
$$ = Result{area: $1, part1: $3, part2: $5}
}
area: D D D
{
$$ = cat($1, $2, $3)
}
part1: D D D
{
$$ = cat($1, $2, $3)
}
part2: D D D D
{
$$ = cat($1, $2, $3, $4)
}- 生成parser.go (goyacc -l -o parser.go parser.y自动生成)。比较关键的定义:
// 对应.y中union的结构体
type yySymType struct {
yys int
result Result
part string
ch byte
}
//token类型
const (
yyDefault = 57347
yyEofCode = 57344
D = 57346
yyErrCode = 57345
yyMaxDepth = 200
yyTabOfs = -7
)
//词法分析器接口
type yyLexer interface {
Lex(lval *yySymType) int
Error(s string)
}
type yyLexerEx interface {
yyLexer
Reduced(rule, state int, lval *yySymType) bool
}
//语法解析入口
func yyParse(yylex yyLexer) int {
}
// Result is the type of the parser result
type Result struct {
area string
part1 string
part2 string
}
// 解析的总入口。输入电话号码,输出为Result的解析结果。
func Parse(input []byte) (Result, error) {
l := newLex(input)
_ = yyParse(l)
return l.result, l.err
}
// 手动定义词法解析器
type lex struct {
input *bytes.Buffer
result Result
err error
}
func newLex(input []byte) *lex {
return &lex{
input: bytes.NewBuffer(input),
}
}
// 词法分析器满足Lex接口。能够逐个读取token。
// 如果是有效的电话号码数字,返回D类型,并赋值lval.ch。
func (l *lex) Lex(lval *yySymType) int {
b := l.nextb()
if unicode.IsDigit(rune(b)) {
lval.ch = b
return D
}
return int(b)
}
func (l *lex) nextb() byte {
b, err := l.input.ReadByte()
if err != nil {
return 0
}
return b
}
// Error satisfies yyLexer.
func (l *lex) Error(s string) {
l.err = errors.New(s)
}
func cat(bytes ...byte) string {
var out string
for _, b := range bytes {
out += string(b)
}
return out
}