
src/runtime/chan.go:hchan定义了channel的数据结构:
qcount uint // 当前队列中剩余元素个数
dataqsiz uint // 环形队列长度,即可以存放的元素个数
buf unsafe.Pointer // 环形队列指针
elemsize uint16 // 每个元素的大小
closed uint32 // 标识关闭状态
elemtype *_type // 元素类型
sendx uint // 队列下标,指示元素写入时存放到队列中的位置
recvx uint // 队列下标,指示元素从队列的该位置读出
recvq waitq // 等待读消息的goroutine队列
sendq waitq // 等待写消息的goroutine队列
lock mutex // 互斥锁,chan不允许并发读写}
复制代码Slice
源码包中src/runtime/slice.go:slice定义了Slice的数据结构:
type slice struct {
array unsafe.Pointer
len int
cap int
}
复制代码从数据结构看Slice很清晰, array指针指向底层数组,len表示切片长度,cap表示底层数组容量。
扩容容量的选择遵循以下规则:
- 如果原Slice容量小于1024,则新Slice容量将扩大为原来的2倍;
- 如果原Slice容量大于等于1024,则新Slice容量将扩大为原来的1.25倍;
使用append()向Slice添加一个元素的实现步骤如下:
- 假如Slice容量够用,则将新元素追加进去,Slice.len++,返回原Slice
- 原Slice容量不够,则将Slice先扩容,扩容后得到新Slice
-
- 将新元素追加进新Slice,Slice.len++,返回新的Slice。
Tips
- 创建切片时可根据实际需要预分配容量,尽量避免追加过程中扩容操作,有利于提升性能;
- 切片拷贝时需要判断实际拷贝的元素个数
- 谨慎使用多个切片操作同一个数组,以防读写冲突
Slice总结
- 每个切片都指向一个底层数组
- 每个切片都保存了当前切片的长度、底层数组可用容量
- 使用len()计算切片长度时间复杂度为O(1),不需要遍历切片
- 使用cap()计算切片容量时间复杂度为O(1),不需要遍历切片
- 通过函数传递切片时,不会拷贝整个切片,因为切片本身只是个结构体而已
- 使用append()向切片追加元素时有可能触发扩容,扩容后将会生成新的切片
map
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
复制代码bucket数据结构由runtime/map.go:bmap定义:
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
data byte[1] //key value数据:key/key/key/.../value/value/value...
overflow *bmap //溢出bucket的地址}
复制代码每个bucket可以存储8个键值对。
- tophash是个长度为8的数组,哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈希值的高位存储在该数组中,以方便后续匹配。
- data区存放的是key-value数据,存放顺序是key/key/key/…value/value/value,如此存放是为了节省字节对齐带来的空间浪费。
- overflow 指针指向的是下一个bucket,据此将所有冲突的键连接起来。
注意:上述中data和overflow并不是在结构体中显示定义的,而是直接通过指针运算进行访问的。
负载因子
负载因子用于衡量一个哈希表冲突情况,公式为:
负载因子 = 键数量/bucket数量例如,对于一个bucket数量为4,包含4个键值对的哈希表来说,这个哈希表的负载因子为1.
哈希表需要将负载因子控制在合适的大小,超过其阀值需要进行rehash,也即键值对重新组织:
- 哈希因子过小,说明空间利用率低
- 哈希因子过大,说明冲突严重,存取效率低
每个哈希表的实现对负载因子容忍程度不同,比如Redis实现中负载因子大于1时就会触发rehash,而Go则在在负载因子达到6.5时才会触发reh
mutex2.1 Mutex结构体
源码包src/sync/mutex.go:Mutex定义了互斥锁的数据结构:
state int32
sema uint32}
复制代码- Mutex.state表示互斥锁的状态,比如是否被锁定等。
- Mutex.sema表示信号量,协程阻塞等待该信号量,解锁的协程释放信号量从而唤醒等待信号量的协程。
我们看到Mutex.state是32位的整型变量,内部实现时把该变量分成四份,用于记录Mutex的四种状态。
下图展示Mutex的内存布局:
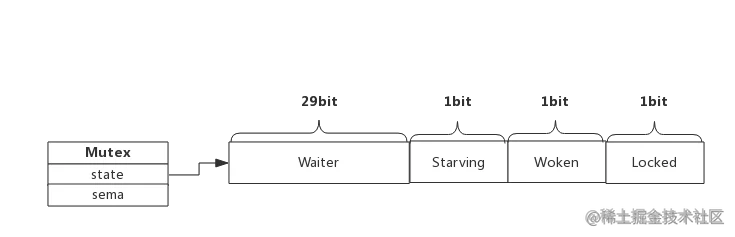
- Locked: 表示该Mutex是否已被锁定,0:没有锁定 1:已被锁定。
- Woken: 表示是否有协程已被唤醒,0:没有协程唤醒 1:已有协程唤醒,正在加锁过程中。
- Starving:表示该Mutex是否处于饥饿状态,0:没有饥饿 1:饥饿状态,说明有协程阻塞了超过1ms。
- Waiter: 表示阻塞等待锁的协程个数,协程解锁时根据此值来判断是否需要释放信号量。
协程之间抢锁实际上是抢给Locked赋值的权利,能给Locked域置1,就说明抢锁成功。抢不到的话就阻塞等待Mutex.sema信号量,一旦持有锁的协程解锁,等待的协程会依次被唤醒。
Woken和Starving主要用于控制协程间的抢锁过程,后面再进行了解。
2.2 Mutex方法
Mutex对外提供两个方法,实际上也只有这两个方法:
- Lock() : 加锁方法
- Unlock(): 解锁方法
下面我们分析一下加锁和解锁的过程,加锁分成功和失败两种情况,成功的话直接获取锁,失败后当前协程被阻塞,同样,解锁时根据是否有阻塞协程也有两种处理。
- 加解锁过程 3.1 简单加锁
假定当前只有一个协程在加锁,没有其他协程干扰,那么过程如下图所示:
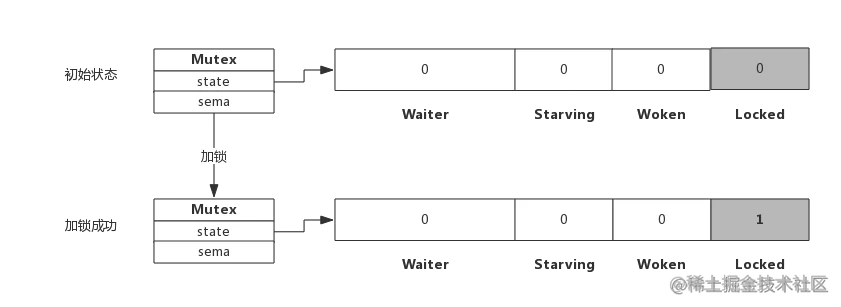 加锁过程会去判断Locked标志位是否为0,如果是0则把Locked位置1,代表加锁成功。从上图可见,加锁成功后,只是Locked位置1,其他状态位没发生变化。
加锁过程会去判断Locked标志位是否为0,如果是0则把Locked位置1,代表加锁成功。从上图可见,加锁成功后,只是Locked位置1,其他状态位没发生变化。
3.2 加锁被阻塞
假定加锁时,锁已被其他协程占用了,此时加锁过程如下图所示:
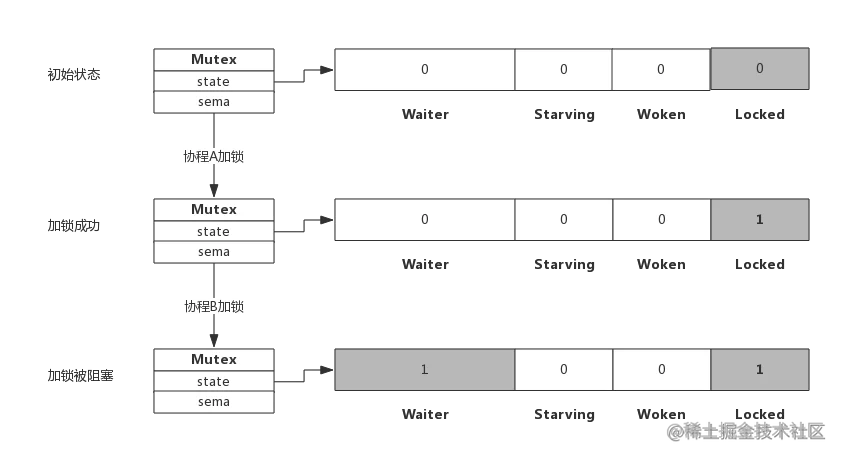
从上图可看到,当协程B对一个已被占用的锁再次加锁时,Waiter计数器增加了1,此时协程B将被阻塞,直到Locked值变为0后才会被唤醒。
3.4 解锁并唤醒协程
假定解锁时,有1个或多个协程阻塞,此时解锁过程如下图所示:
 协程A解锁过程分为两个步骤,一是把Locked位置0,二是查看到Waiter>0,所以释放一个信号量,唤醒一个阻塞的协程,被唤醒的协程B把Locked位置1,于是协程B获得锁。
协程A解锁过程分为两个步骤,一是把Locked位置0,二是查看到Waiter>0,所以释放一个信号量,唤醒一个阻塞的协程,被唤醒的协程B把Locked位置1,于是协程B获得锁。