



Go语言同时提供了有符号和无符号类型的整数运算。这里有int8、int16、int32和int64四种截然不同大小的有符号整数类型,分别对应8、16、32、64bit大小的有符号整数,与此对应的是uint8、uint16、uint32和uint64四种无符号整数类型。
Unicode字符rune类型是和int32等价的类型,通常用于表示一个Unicode码点。这两个名称可以互换使用。同样byte也是uint8类型的等价类型,byte类型一般用于强调数值是一个原始的数据而不是一个小的整数。
下面是Go语言中关于算术运算、逻辑运算和比较运算的二元运算符,它们按照优先级递减的顺序排列:
* / % << >> & &^
+ - | ^
== != < <= > >=
&&
||
两个相同的整数类型可以使用下面的二元比较运算符进行比较;比较表达式的结果是布尔类型。
== // 等于
!= // 不等于
< // 小于
<= // 小于等于
> // 大于
>= // 大于等于
Go语言提供了两种精度的浮点数,float32和float64。它们的算术规范由IEEE754浮点数国际标准定义,该浮点数规范被所有现代的CPU支持。
float32类型的浮点数可以提供大约6个十进制数的精度,而float64则可以提供约15个十进制数的精度;通常应该优先使用float64类型,因为float32类型的累计计算误差很容易扩散,
var f float32 = 212213
fmt.Println(f == f + 1)
Go语言提供了两种精度的复数类型:complex64和complex128,分别对应float32和float64两种浮点数精度。内置的complex函数用于构建复数,内建的real和imag函数分别返回复数的实部和虚部:
var x complex128 = complex(1, 2) // 1+2i
var y complex128 = complex(3, 4) // 3+4i
fmt.Println(x*y) // "(-5+10i)"
fmt.Println(real(x*y)) // "-5"
fmt.Println(imag(x*y)) // "10"
一个布尔类型的值只有两种:true和false。if和for语句的条件部分都是布尔类型的值,并且==和<等比较操作也会产生布尔型的值, 布尔值可以和&&(AND)和||(OR)操作符结合
!true // flase
a := 10
a > 1 // true

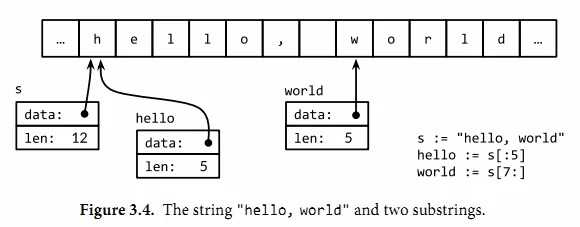
一个字符串是一个不可改变的字节序列。字符串可以包含任意的数据,包括byte值0,但是通常是用来包含人类可读的文本。文本字符串通常被解释为采用UTF8编码的Unicode码点(rune)序列
s := "hello, world"
fmt.Println(len(s)) // "12" len() 长度
fmt.Println(s[0], s[7]) // "104 119" ('h' and 'w')
字符串值也可以用字符串面值方式编写,只要将一系列字节序列包含在双引号即可:
"Hello, 世界"
因为Go语言源文件总是用UTF8编码,并且Go语言的文本字符串也以UTF8编码的方式处理,因此我们可以将Unicode码点也写到字符串面值中。
a 响铃
b 退格
f 换页
n 换行
r 回车
t 制表符
v 垂直制表符
' 单引号 (只用在 ''' 形式的rune符号面值中)
" 双引号 (只用在 "..." 形式的字符串面值中)
\ 反斜杠
5.1.Unicode
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte)。一个字节能表示的最大的整数就是255(2^8-1=255),而ASCII编码,占用0 - 127用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
类似的,日文和韩文等其他语言也有这个问题。为了统一所有文字的编码,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。
5.2.UTF-8
UTF-8(8位元,Universal Character Set/Unicode Transformation Format)是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容,使得原来处理ASCII字符的软件无须或只进行少部份修改后,便可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。
5.3. 字符串和Byte切片
标准库中有四个包对字符串处理尤为重要:bytes、strings、strconv和unicode包。
c:foobar5.4. 字符串和数字的转换
除了字符串、字符、字节之间的转换,字符串和数值之间的转换也比较常见。由strconv包提供这类转换功能。
将一个整数转为字符串,一种方法是用fmt.Sprintf返回一个格式化的字符串;另一个方法是用strconv.Itoa(“整数到ASCII”):
x := 123
y := fmt.Sprintf("%d", x)
fmt.Println(y, strconv.Itoa(x)) // "123 123"
FormatInt和FormatUint函数可以用不同的进制来格式化数字:
fmt.Println(strconv.FormatInt(int64(x), 2)) // "1111011"
fmt.Printf函数的%b、%d、%o和%x等参数提供功能往往比strconv包的Format函数方便很多,特别是在需要包含附加额外信息的时候:
s := fmt.Sprintf("x=%b", x) // "x=1111011"
如果要将一个字符串解析为整数,可以使用strconv包的Atoi或ParseInt函数,还有用于解析无符号整数的ParseUint函数:
x, err := strconv.Atoi("123") // x is an int
y, err := strconv.ParseInt("123", 10, 64) // base 10, up to 64 bits
ParseInt函数的第三个参数是用于指定整型数的大小;例如16表示int16,0则表示int。在任何情况下,返回的结果y总是int64类型,你可以通过强制类型转换将它转为更小的整数类型。
6. 常量常量表达式的值在编译期计算,而不是在运行期。每种常量的潜在类型都是基础类型:boolean、string、浮点型或整型。常量不可改变,一个常量的声明也可以包含一个类型和一个值,但是如果没有显式指明类型,那么将从右边的表达式推断类型。
const 声明:
const a = 10 // 整型
const p = 3.1415926 // 浮点型
const str = "zhaohaiyu" // 字符串
const flag = true // 布尔型
如果是批量声明的常量,除了第一个外其它的常量右边的初始化表达式都可以省略,如果省略初始化表达式则表示使用前面常量的初始化表达式写法,对应的常量类型也一样的。
const (
a = 1
b
c = 2
d
)
fmt.Println(a, b, c, d) // "1 1 2 2"
6.1.iota 常量生成器
常量声明可以使用iota常量生成器初始化,它用于生成一组以相似规则初始化的常量,但是不用每行都写一遍初始化表达式。在一个const声明语句中,在第一个声明的常量所在的行,iota将会被置为0,然后在每一个有常量声明的行加一。
const (
a = 1 + iota
b
c
d
)
fmt.Println(a,b,c,d) // 1,2,3,4
- 还没有人评论,欢迎说说您的想法!