1.JVM内存模型
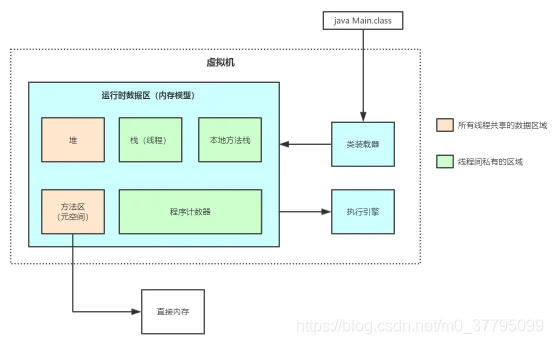
JVM内存模型主要分为三大块:类装载器、运行时数据区(重点)、执行引擎。
--类装载器:代码被编译器编译后生成的二进制字节流(.class)文件后,类加载器把Class文件加载到内存,并进行验证、准备、解析、初始化,能够形成被JVM直接使用的Java类型。
--运行时数据区:主要分为栈、本地方法栈、程序计数器、堆、方法区五个部分
--执行引擎:类加载器将Class文件读取后,放到运行时数据区,然后执行引擎执行或调用本地接口、本地库。
2. 理解栈内存模型
先上一段简单的代码:
public class Main {
public static void main(String[] args) {
Main main = new Main();
main.test();
}
public int test(){
int a = 1;
int b = 2;
int c = (a+b)*3;
return c;
}
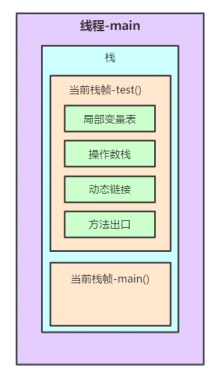
}程序启动后虚拟机会给main线程分配一个栈内存,用于存放线程运行时生成的局部变量。mian()方法的局部变量和test()方法的局部变量是私有的,即不能相互访问的。栈帧就是用来区分同一个线程中不同方法的局部变量的作用域范围。
用javap命令反汇编Main.class文件,观察java底层是如何运行代码的,以及内存的分配情况。在编译器打开terminal窗口,cd到Main.class所在的路径,在terminal中输入指令:javap -c Main.class。(javap指令的用法可以参考官方文档:https://docs.oracle.com/javase/7/docs/technotes/tools/windows/javap.html)
Compiled from "Main.java"
public class Main {
public Main();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public int test();
Code:
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: iload_1
5: iload_2
6: iadd
7: iconst_3
8: imul
9: istore_3
10: iload_3
11: ireturn
public static void main(java.lang.String[]);
Code:
0: new #2 // class Main
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: aload_1
9: invokevirtual #4 // Method test:()I
12: istore_2
13: return
}2.1 test()方法栈内存分析
以上述程序test()方法前7行为例的栈内存变化图解(JVM字节码在oracle官网:https://docs.oracle.com/javase/specs/jvms/se7/html/index.html中6.5节有详细说明。不过是英文版,这里找了一篇中文参考博客:https://www.cnblogs.com/dreamroute/p/5089513.html)
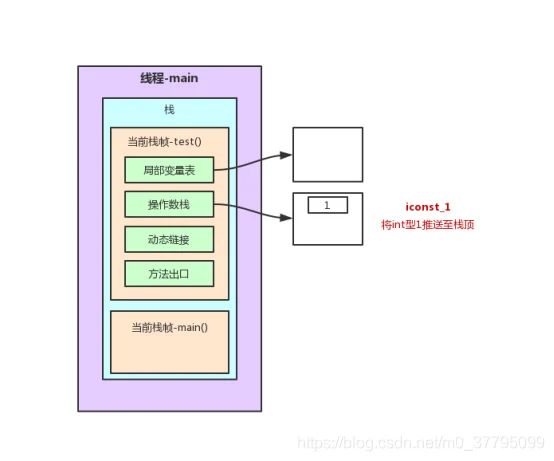
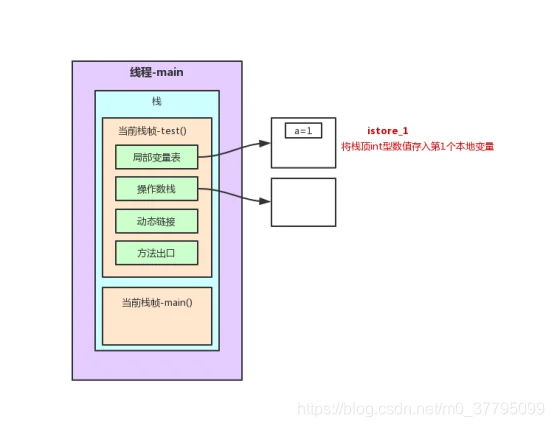
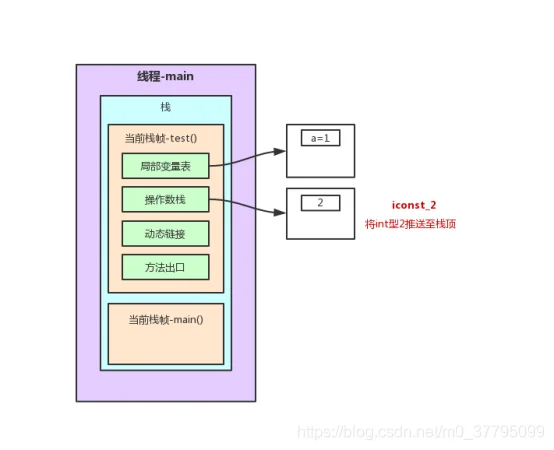
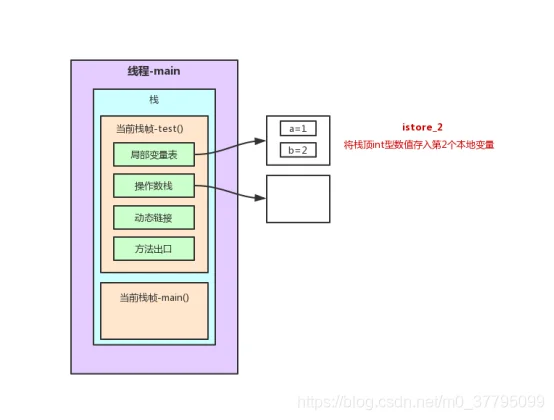
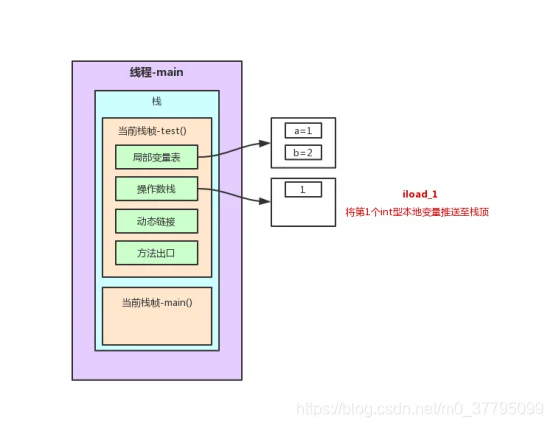
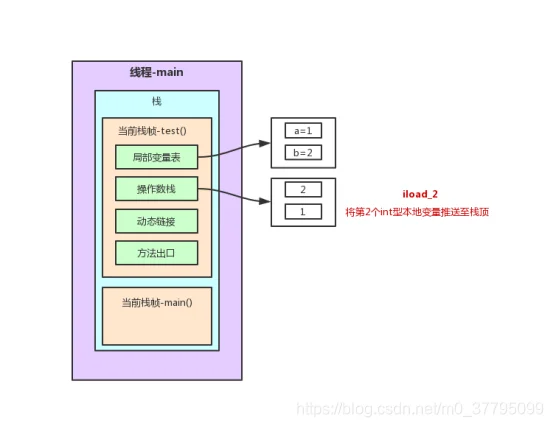
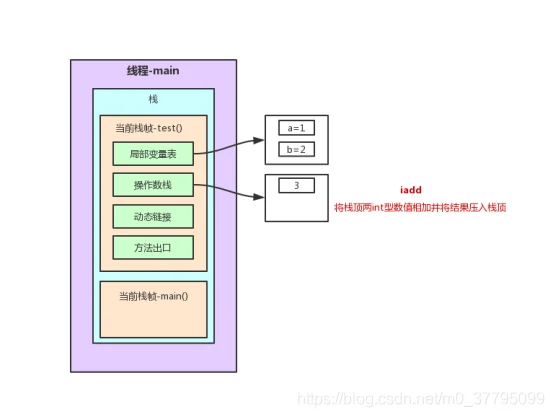
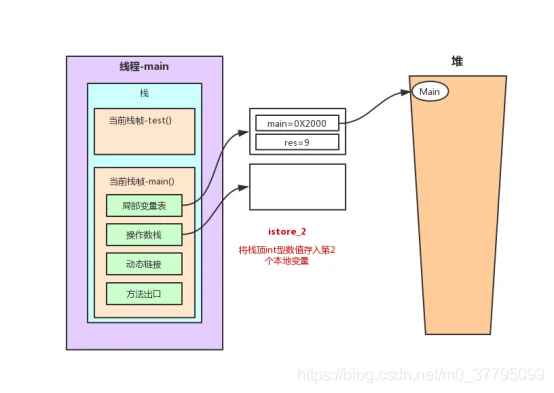
在这个过程中,程序计数器记录正在执行的虚拟机字节码指令的地址。为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,这类内存区域为“线程私有”的内存。
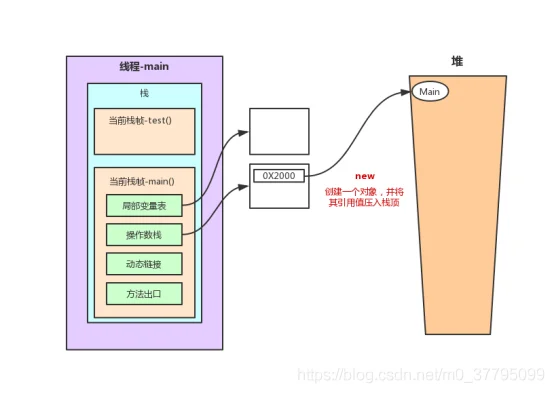
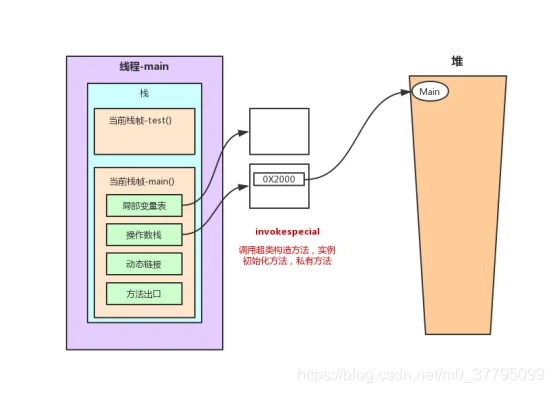
2.2 main()方法栈内存分析
main()方法的指令(这里涉及堆和栈在线程运行时的关系图解)
public static void main(java.lang.String[]);
Code:
0: new #2 // class Main
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: aload_1
9: invokevirtual #4 // Method test:()I
12: istore_2
13: return
3. 栈内存优化
public class StackTest {
public static void main(String[] args) {
int i=0;
cycle(i);
}
public static void cycle(int i){
cycle(++i);
}
}
上面是一段无限递归的代码,最终将导致栈内存溢出。有了上面的栈内存图解基础,我们很容易知道为什么无限递归会导致栈内存溢出。因为不断有新的操作数入栈,超过了栈内存的最大容量,于是发生了栈内存溢出。
实际项目中,如果真的有必须要使用几千次以上的递归的话,可以通过加大-Xss 这个参数的数组进行调优。如果不设置的话,默认- Xss 1M。但是这个值并不是越大越好,因为JVM本身的内存是有限的,增大每个栈的容量,那么一个进程中可以容纳的线程数就会越少。更合理的方案是项目中尽量少用递归,将Xss参数控制在128K或更小,这样在相同的JVM内存下,可以支撑更多的线程。
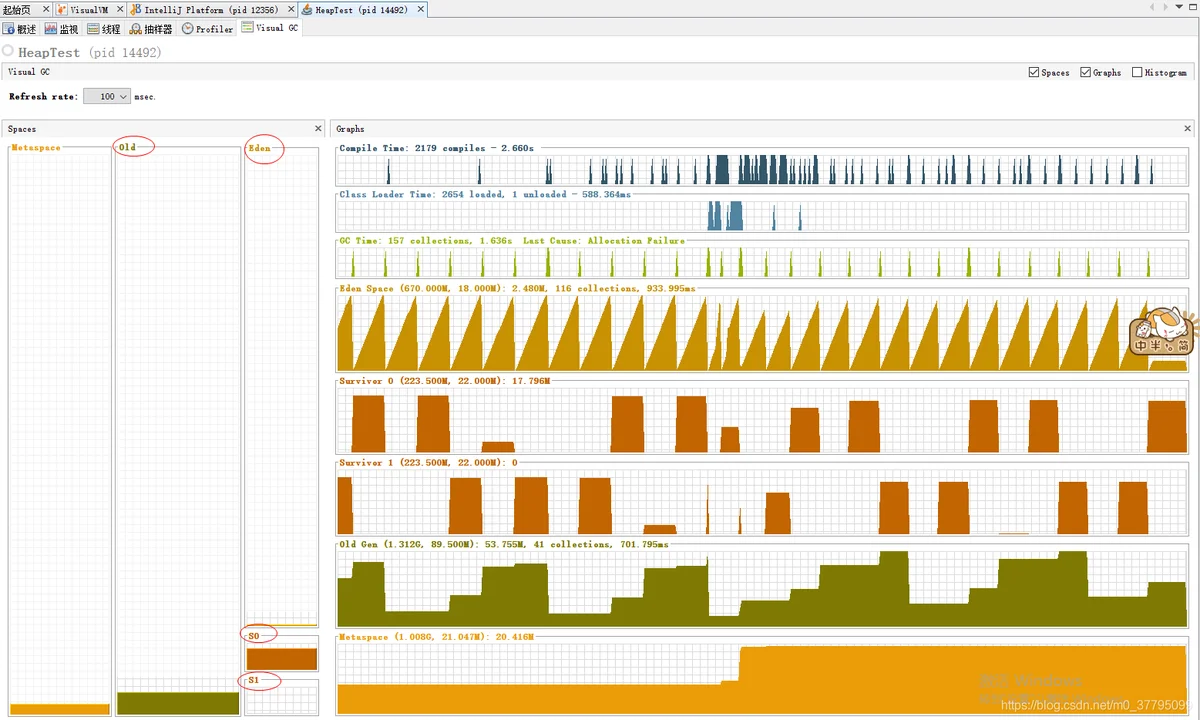
4. 理解堆内存模型
堆内存分为年轻代和老年代。年轻代又分为Eden和Survivor区。默认情况下,老年代占整个堆内存的2/3;年轻代占1/3。Eden占年轻代的80%;from区(S0区)占10%,to区(S1区)占10%。
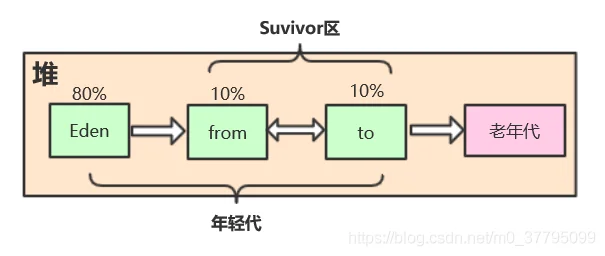
new出来的对象存储在Eden,当Eden满的时候,就会做一次minorGC。清理无效对象,剩下的有效对象进入from区。当from区满的时候,又会触发一次minorGC,剩余有效对象进入to区。当to区满的时候,同样触发一次minorGC,剩余有效对象进入from区,from区和to区的GC是一个循环过程,没触发一次GC年龄值增加1,年龄达到15次的对象会进入老年区。当老年区满的时候,会触发一次fullGC。
下面一段代码最终会导致堆内存溢出。
import java.util.ArrayList;
public class HeapTest {
byte[] a = new byte[1024*100];
public static void main(String[] args) throws Exception{
ArrayList<HeapTest> heapList = new ArrayList<>();
int i = 0;
while (true){
heapList.add(new HeapTest());
System.out.println(i++);
Thread.sleep(10);
}
}
}
分析原因:每次new一个对象就会开辟一块100K的内存空间,heapList列表的元素指向这块堆内存。while (true)死循环里面不断new出新的对象,对象又被heapList列表引用而无法释放进入老年代,最终老年代满了进行fullGC。但是很不幸,所有对象都被引用,没有可以释放的对象,于是堆内存溢出了。
5.堆内存调优
-Xms:设置初始分配大小,默认为物理内存的“1/64”
-Xmx:最大分配内存,默认为物理内存的“1/4”
可以通过下面代码查看物理内存信息:
System.out.println("Max_memory="+Runtime.getRuntime().maxMemory()/(double)1024/1024+"M");
System.out.println("Total_memory="+Runtime.getRuntime().totalMemory()/(double)1024/1024+"M");如果程序中存在大量的大对象时,就需要分配更大的堆内存空间。一般将-Xms和-Xmx设置成同样的值,让伸缩区的大小为0,因为内存伸缩可能会导致程序性能的下降。
可以利用jdk自带的JVisualvm工具实时查看程序运行过程中的对内存变化。(需要安装VisualGC插件,在工具-插件中直接搜索安装即可)。