
https://zhuanlan.zhihu.com/p/76802887
http://goog-perftools.sourceforge.net/doc/tcmalloc.html
这篇文章主要介绍Go内存分配和Go内存管理,会轻微涉及内存申请和释放,以及Go垃圾回收。从非常宏观的角度看,Go的内存管理就是下图这个样子,我们今天主要关注其中标红的部分。
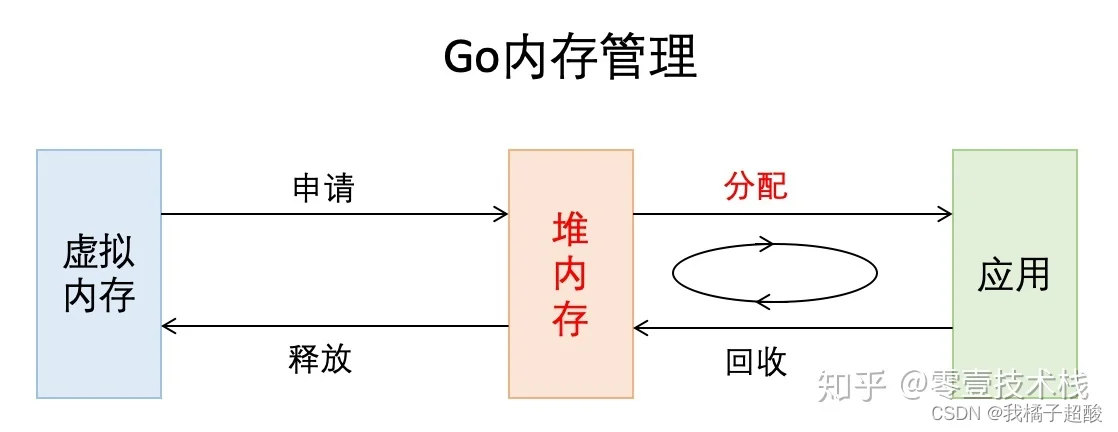
Go这门语言抛弃了C/C++中的开发者管理内存的方式,实现了主动申请与主动释放管理,增加了逃逸分析和GC,将开发者从内存管理中释放出来,让开发者有更多的精力去关注软件设计,而不是底层的内存问题。这是Go语言成为高生产力语言的原因之一。
我们不需要精通内存的管理,因为它确实很复杂,但掌握内存的管理,可以让你写出更高质量的代码,另外,还能助你定位Bug。这篇文章采用层层递进的方式,依次会介绍关于存储的基本知识,Go内存管理的 “前辈” TCMalloc,然后是Go的内存管理和分配,最后是总结。这么做的目的是,希望各位能通过全局的认识和思考,拥有更好的编码思维和架构思维。
正文1. 存储基础知识回顾
这部分我们简单回顾一下计算机存储体系、虚拟内存、栈和堆,以及堆内存的管理,这部分内容对理解和掌握Go内存管理比较重要。
1.1. 存储金字塔
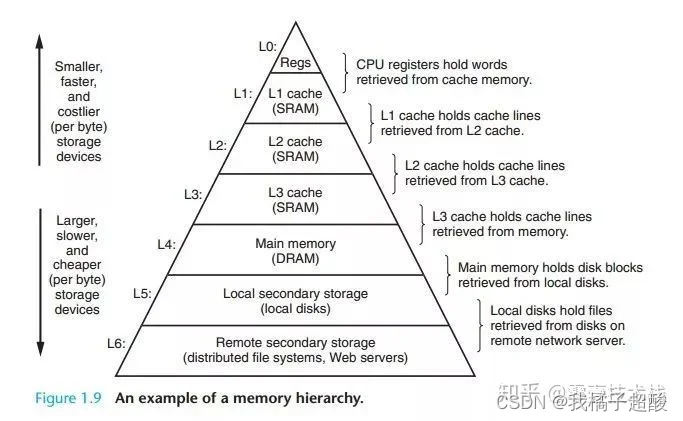
这幅图表达了计算机的存储体系,从上至下的访问速度越来越慢,访问时间越来越长。从上至下依次是:
- CPU寄存器
- CPU Cache
- 内存
- 硬盘等辅助存储设备
- 鼠标等外接设备
你有没有思考过下面2个简单的问题,如果没有不妨想想:
- 如果CPU直接访问硬盘,CPU能充分利用吗?
- 如果CPU直接访问内存,CPU能充分利用吗?
CPU速度很快,但硬盘等持久存储很慢,如果CPU直接访问磁盘,磁盘可以拉低CPU的速度,机器整体性能就会低下,为了弥补这2个硬件之间的速率差异,所以在CPU和磁盘之间增加了比磁盘快很多的内存。
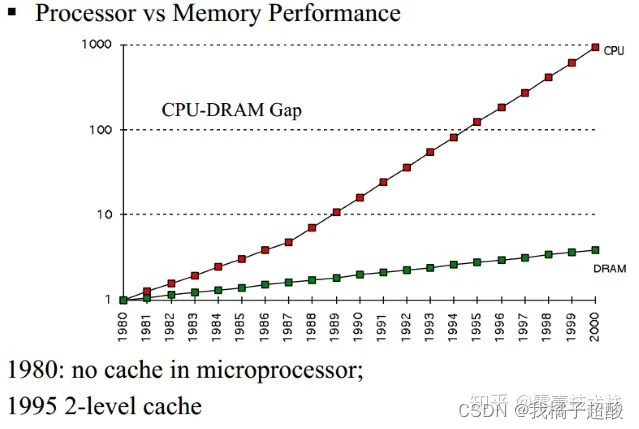
然而,CPU跟内存的速率也不是相同的,从上图可以看到,CPU的速率提高的很快(摩尔定律),然而内存速率增长的很慢,虽然CPU的速率现在增加的很慢了,但是内存的速率也没增加多少,速率差距很大,从1980年开始CPU和内存速率差距在不断拉大,为了弥补这2个硬件之间的速率差异,所以在CPU跟内存之间增加了比内存更快的Cache,Cache是内存数据的缓存,可以降低CPU访问内存的时间。
三级Cache分别是L1、L2、L3,它们的速率是三个不同的层级,L1速率最快,与CPU速率最接近,是RAM速率的100倍,L2速率就降到了RAM的25倍,L3的速率更靠近RAM的速率。
看到这了,你有没有Get到整个存储体系的分层设计?自顶向下,速率越来越低,访问时间越来越长,从磁盘到CPU寄存器,上一层都可以看做是下一层的缓存。看了分层设计,下面开始正式介绍内存。
1.2. 虚拟内存
虚拟内存是当代操作系统必备的一项重要功能,对于进程而言虚拟内存屏蔽了底层了RAM和磁盘,并向进程提供了远超物理内存大小的内存空间。我们看一下虚拟内存的分层设计。
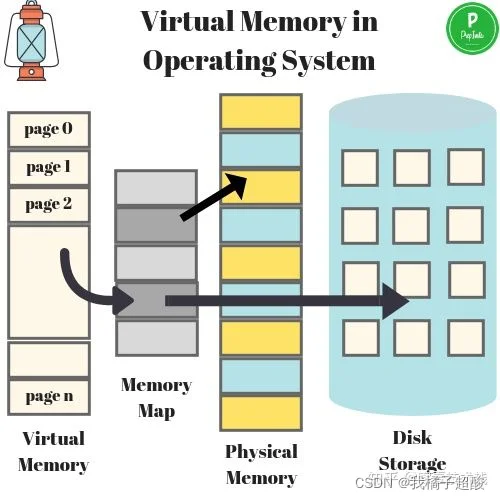
上图展示了某进程访问数据,当Cache没有命中的时候,访问虚拟内存获取数据的过程。在访问内存,实际访问的是虚拟内存,虚拟内存通过页表查看,当前要访问的虚拟内存地址,是否已经加载到了物理内存。如果已经在物理内存,则取物理内存数据,如果没有对应的物理内存,则从磁盘加载数据到物理内存,并把物理内存地址和虚拟内存地址更新到页表。
物理内存就是磁盘存储缓存层,在没有虚拟内存的时代,物理内存对所有进程是共享的,多进程同时访问同一个物理内存会存在并发问题。而引入虚拟内存后,每个进程都有各自的虚拟内存,内存的并发访问问题的粒度从多进程级别,可以降低到多线程级别。
1.3. 栈和堆
我们现在从虚拟内存,再进一层,看虚拟内存中的栈和堆,也就是进程对内存的管理。
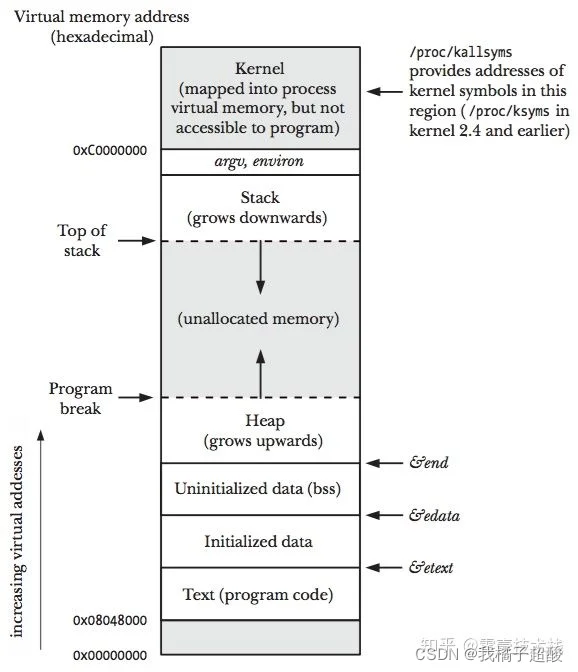
上图展示了一个进程的虚拟内存划分,代码中使用的内存地址都是虚拟内存地址,而不是实际的物理内存地址。栈和堆只是虚拟内存上2块不同功能的内存区域:
- 栈在高地址,从高地址向低地址增长
- 堆在低地址,从低地址向高地址增长
栈和堆相比有这么几个好处:
- 栈的内存管理简单,分配比堆上快。
- 栈的内存不需要回收,而堆需要进行回收,无论是主动free,还是被动的垃圾回收,这都需要花费额外的CPU。
- 栈上的内存有更好的局部性,堆上内存访问就不那么友好了,CPU访问的2块数据可能在不同的页上,CPU访问数据的时间可能就上去了。
1.4. 对内存管理
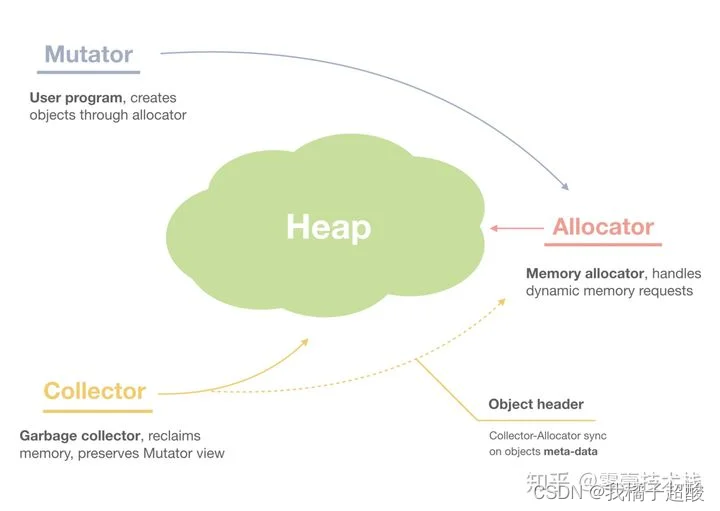
我们再进一层,当我们说内存管理的时候,主要是指堆内存的管理,因为栈的内存管理不需要程序去操心,这小节看下堆内存管理到底完成了什么。如上图所示主要是3部分,分别是分配内存块,回收内存块和组织内存块。
在一个最简单的内存管理中,堆内存最初会是一个完整的大块,即未分配任何内存。当发现内存申请的时候,堆内存就会从未分配内存分割出一个小内存块(block),然后用链表把所有内存块连接起来。需要一些信息描述每个内存块的基本信息,比如大小(size)、是否使用中(used)和下一个内存块的地址(next),内存块实际数据存储在data中。
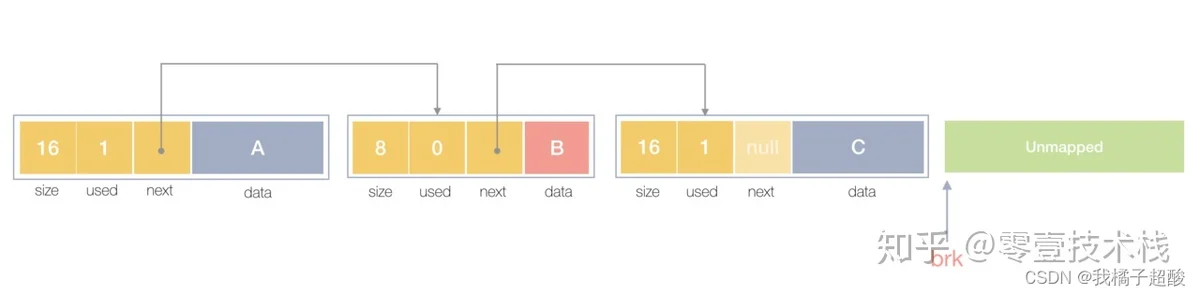
一个内存块包含了3类信息,如下图所示,元数据、用户数据和对齐字段,内存对齐是为了提高访问效率。下图申请5Byte内存的时候,就需要进行内存对齐。
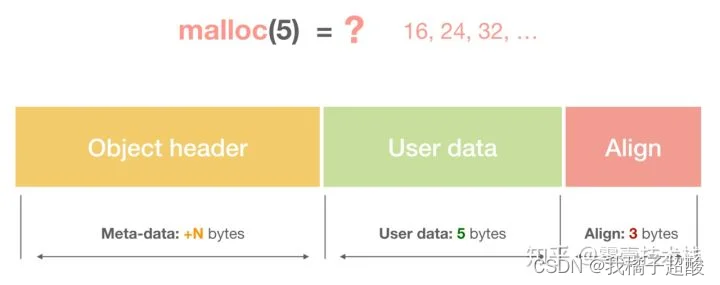
释放内存实质是把使用的内存块从链表中取出来,然后标记为未使用,当分配内存块的时候,可以从未使用内存块中优先查找大小相近的内存块,如果找不到,再从未分配的内存中分配内存。
上面这个简单的设计中还没考虑内存碎片的问题,因为随着内存不断的申请和释放,内存上会存在大量的碎片,降低内存的使用率。为了解决内存碎片,可以将2个连续的未使用的内存块合并,减少碎片。
2.TCMalloc
TCMalloc是Thread Cache Malloc的简称,是Go内存管理的起源,Go的内存管理是借鉴了TCMalloc,随着Go的迭代,Go的内存管理与TCMalloc不一致地方在不断扩大,但其主要思想、原理和概念都是和TCMalloc一致的,如果跳过TCMalloc直接去看Go的内存管理,也许你会似懂非懂。
掌握TCMalloc的理念,无需去关注过多的源码细节,就可以为掌握Go的内存管理打好基础,基础打好了,后面知识才扎实。
- 在Linux操作系统中,其实有不少的内存管理库,比如glibc的ptmalloc,FreeBSD的jemalloc,Google的tcmalloc等等,为何会出现这么多的内存管理库?本质都是在多线程编程下,追求更高内存管理效率:更快的分配是主要目的
我们前面提到引入虚拟内存后,让内存的并发访问问题的粒度从多进程级别,降低到多线程级别。然而同一进程下的所有线程共享相同的内存空间,它们申请内存时需要加锁,如果不加锁就存在同一块内存被2个线程同时访问的问题。
TCMalloc的做法是什么呢?为每个线程预分配一块缓存,线程申请小内存时,可以从缓存分配内存,这样有2个好处:
- 为线程预分配缓存需要进行1次系统调用,后续线程申请小内存时直接从缓存分配,都是在用户态执行的,没有了系统调用,缩短了内存总体的分配和释放时间,这是快速分配内存的第二个层次。
- 多个线程同时申请小内存时,从各自的缓存分配,访问的是不同的地址空间,从而无需加锁,把内存并发访问的粒度进一步降低了,这是快速分配内存的第三个层次。
2.1. 基本原理
下面就简单介绍下TCMalloc,细致程度够我们理解Go的内存管理即可。
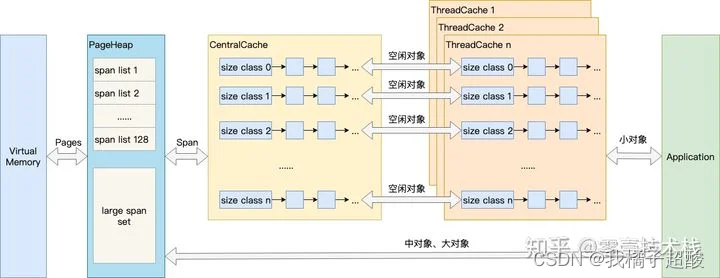
结合上图,介绍TCMalloc的几个重要概念:
-
Page
操作系统对内存管理以页为单位,TCMalloc也是这样,只不过TCMalloc里的Page大小与操作系统里的大小并不一定相等,而是倍数关系。《TCMalloc解密》里称x64下Page大小是8KB。 -
Span
一组连续的Page被称为Span,比如可以有2个页大小的Span,也可以有16页大小的Span,Span比Page高一个层级,是为了方便管理一定大小的内存区域,Span是TCMalloc中内存管理的基本单位。 -
ThreadCache
ThreadCache是每个线程各自的Cache,一个Cache包含多个空闲内存块链表,每个链表连接的都是内存块,同一个链表上内存块的大小是相同的,也可以说按内存块大小,给内存块分了个类,这样可以根据申请的内存大小,快速从合适的链表选择空闲内存块。由于每个线程有自己的ThreadCache,所以ThreadCache访问是无锁的。 -
CentralCache
CentralCache是所有线程共享的缓存,也是保存的空闲内存块链表,链表的数量与ThreadCache中链表数量相同,当ThreadCache的内存块不足时,可以从CentralCache获取内存块;当ThreadCache内存块过多时,可以放回CentralCache。由于CentralCache是共享的,所以它的访问是要加锁的。 -
PageHeap
PageHeap是对堆内存的抽象,PageHeap存的也是若干链表,链表保存的是Span。当CentralCache的内存不足时,会从PageHeap获取空闲的内存Span,然后把1个Span拆成若干内存块,添加到对应大小的链表中并分配内存;当CentralCache的内存过多时,会把空闲的内存块放回PageHeap中。
如下图所示,分别是1页Page的Span链表,2页Page的Span链表等,最后是large span set,这个是用来保存中大对象的。毫无疑问,PageHeap也是要加锁的。
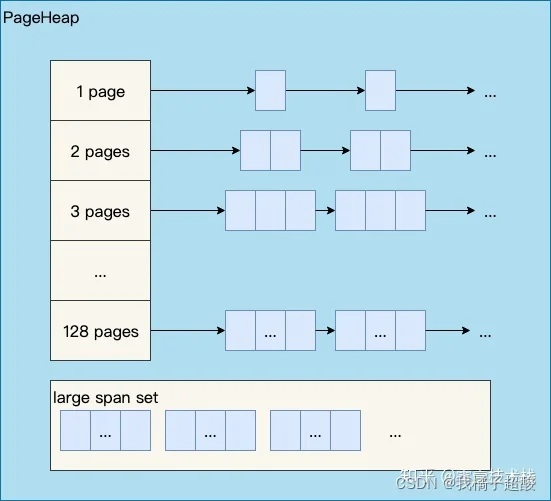
前文提到了小、中、大对象,Go内存管理中也有类似的概念,我们看一眼TCMalloc的定义:
- 小对象大小:0~256KB
- 中对象大小:257~1MB
- 大对象大小:>1MB
小对象的分配流程:ThreadCache -> CentralCache -> HeapPage,大部分时候,ThreadCache缓存都是足够的,不需要去访问CentralCache和HeapPage,无系统调用配合无锁分配,分配效率是非常高的。
中对象分配流程:直接在PageHeap中选择适当的大小即可,128 Page的Span所保存的最大内存就是1MB。
大对象分配流程:从large span set选择合适数量的页面组成span,用来存储数据。
通过本节的介绍,你应当对TCMalloc主要思想有一定了解了,我建议再回顾一下上面的内容。
3. Go内存管理
前文提到Go内存管理源自TCMalloc,但它比TCMalloc还多了2件东西:逃逸分析和垃圾回收,这是2项提高生产力的绝佳武器。这一大章节,我们先介绍Go内存管理和Go内存分配,最后涉及一点垃圾回收和内存释放。
3.1. Go内存管理的基本概念
Go内存管理的许多概念在TCMalloc中已经有了,含义是相同的,只是名字有一些变化。先给大家上一幅宏观的图,借助图一起来介绍。
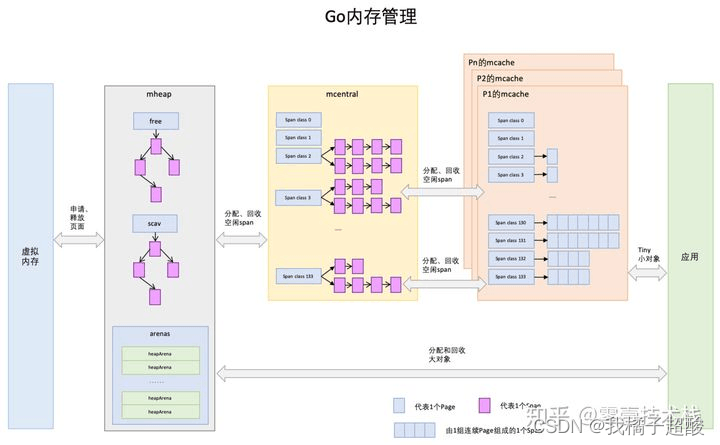
-
Page
与TCMalloc中的Page相同,x64架构下1个Page的大小是8KB。上图的最下方,1个浅蓝色的长方形代表1个Page。 -
Span
Span与TCMalloc中的Span相同,Span是内存管理的基本单位,代码中为mspan,一组连续的Page组成1个Span,所以上图一组连续的浅蓝色长方形代表的是一组Page组成的1个Span,另外,1个淡紫色长方形为1个Span。 -
mcache
mcache与TCMalloc中的ThreadCache类似,mcache保存的是各种大小的Span,并按Span class分类,小对象直接从mcache分配内存,它起到了缓存的作用,并且可以无锁访问。但是mcache与ThreadCache也有不同点,TCMalloc中是每个线程1个ThreadCache,Go中是每个P拥有1个mcache。因为在Go程序中,当前最多有GOMAXPROCS个线程在运行,所以最多需要GOMAXPROCS个mcache就可以保证各线程对mcache的无锁访问,线程的运行又是与P绑定的,把mcache交给P刚刚好。 -
mcentral
mcentral与TCMalloc中的CentralCache类似,是所有线程共享的缓存,需要加锁访问。它按Span级别对Span分类,然后串联成链表,当mcache的某个级别Span的内存被分配光时,它会向mcentral申请1个当前级别的Span。
但是mcentral与CentralCache也有不同点,CentralCache是每个级别的Span有1个链表,mcache是每个级别的Span有2个链表,这和mcache申请内存有关,稍后我们再解释。
- mheap
mheap与TCMalloc中的PageHeap类似,它是堆内存的抽象,把从OS申请出的内存页组织成Span,并保存起来。当mcentral的Span不够用时会向mheap申请内存,而mheap的Span不够用时会向OS申请内存。mheap向OS的内存申请是按页来的,然后把申请来的内存页生成Span组织起来,同样也是需要加锁访问的。
但是mheap与PageHeap也有不同点:mheap把Span组织成了树结构,而不是链表,并且还是2棵树,然后把Span分配到heapArena进行管理,它包含地址映射和span是否包含指针等位图,这样做的主要原因是为了更高效的利用内存:分配、回收和再利用。
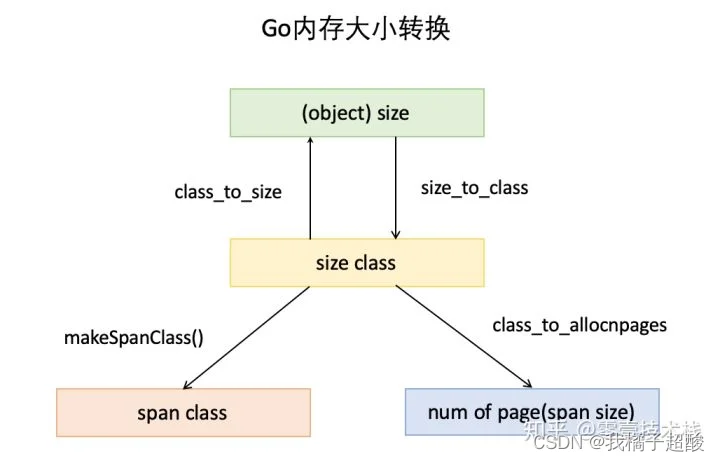
- object size:代码里简称size,指申请内存的对象大小。
- size class:代码里简称class,它是size的级别,相当于把size归类到一定大小的区间段,比如size[1,8]属于size class 1,size(8,16]属于size class 2。
- span class:指span的级别,但span class的大小与span的大小并没有正比关系。span class主要用来和size class做对应,1个size class对应2个span class,2个span class的span大小相同,只是功能不同,1个用来存放包含指针的对象,一个用来存放不包含指针的对象,不包含指针对象的Span就无需GC扫描了。
- num of page:代码里简称npage,代表Page的数量,其实就是Span包含的页数,用来分配内存。
3.2. Go内存分配
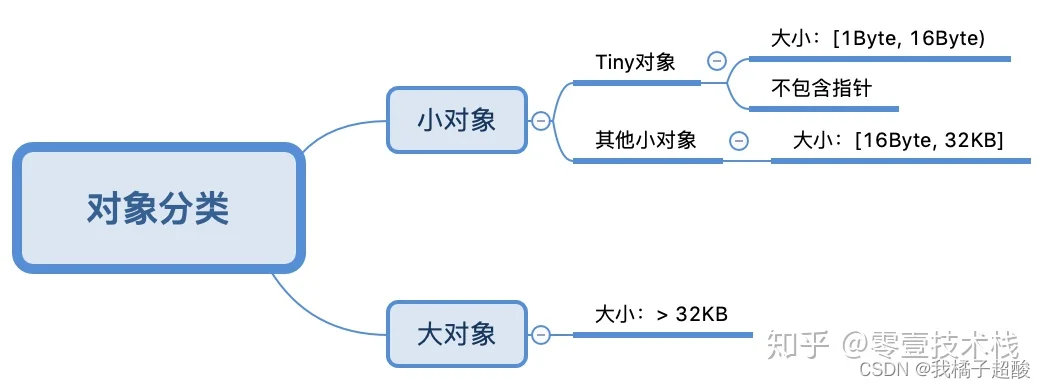
Go中的内存分类并不像TCMalloc那样分成小、中、大对象,但是它的小对象里又细分了一个Tiny对象,Tiny对象指大小在1Byte到16Byte之间并且不包含指针的对象。小对象和大对象只用大小划定,无其他区分。
3.2.1. 小对象的内存分配
大小转换这一小节,我们介绍了转换表,size class从1到66共66个,代码中_NumSizeClasses=67代表了实际使用的size class数量,即67个,从0到67,size class 0实际并未使用到。
上文提到1个size class对应2个span class:
numSpanClasses = _NumSizeClasses * 2
numSpanClasses为span class的数量为134个,所以span class的下标是从0到133,所以上图中mcache标注了的span class是,span class 0到span class 133。每1个span class都指向1个span,也就是mcache最多有134个span。
- 为对象寻找span
寻找span的流程如下:
- 计算对象所需内存大小size
- 根据size到size class映射,计算出所需的size class
- 根据size class和对象是否包含指针计算出span class
- 获取该span class指向的span
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 32 8192 256 0 46.88%
// 4 48 8192 170 32 31.52%
对应的size class为3,它的对象大小范围是(16,32]Byte,24Byte刚好在此区间,所以此对象的size class为3。
Size class到span class的计算如下:
// noscan为true代表对象不包含指针
func makeSpanClass(sizeclass uint8, noscan bool) spanClass {
return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))
}
所以对应的span class为7,所以该对象需要的是span class 7指向的span。
span class = 3 << 1 | 1 = 7
- 从span分配对象空间
Span可以按对象大小切成很多份,这些都可以从映射表上计算出来,以size class 3对应的span为例,span大小是8KB,每个对象实际所占空间为32Byte,这个span就被分成了256块,可以根据span的起始地址计算出每个对象块的内存地址。

随着内存的分配,span中的对象内存块,有些被占用,有些未被占用,比如上图,整体代表1个span,蓝色块代表已被占用内存,绿色块代表未被占用内存。当分配内存时,只要快速找到第一个可用的绿色块,并计算出内存地址即可,如果需要还可以对内存块数据清零。
当span内的所有内存块都被占用时,没有剩余空间继续分配对象,mcache会向mcentral申请1个span,mcache拿到span后继续分配对象。
- mcache向mcentral申请span
mcentral和mcache一样,都是0~133这134个span class级别,但每个级别都保存了2个span list,即2个span链表:
- nonempty:这个链表里的span,所有span都至少有1个空闲的对象空间。这些span是mcache释放span时加入到该链表的。
- empty:这个链表里的span,所有的span都不确定里面是否有空闲的对象空间。当一个span交给mcache的时候,就会加入到empty链表。
这两个东西名称一直有点绕,建议直接把empty理解为没有对象空间就好了。
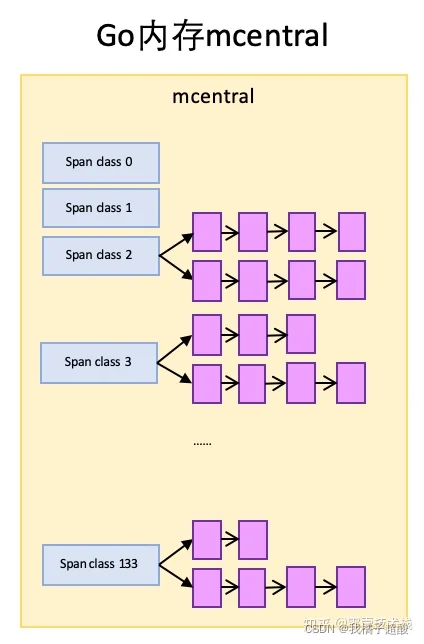
mcache向mcentral申请span时,mcentral会先从nonempty搜索满足条件的span,如果没有找到再从emtpy搜索满足条件的span,然后把找到的span交给mcache。
- mheap的span管理
mheap里保存了两棵二叉排序树,按span的page数量进行排序:
- free:free中保存的span是空闲并且非垃圾回收的span。
- scav:scav中保存的是空闲并且已经垃圾回收的span。
如果是垃圾回收导致的span释放,span会被加入到scav,否则加入到free,比如刚从OS申请的的内存也组成的Span。
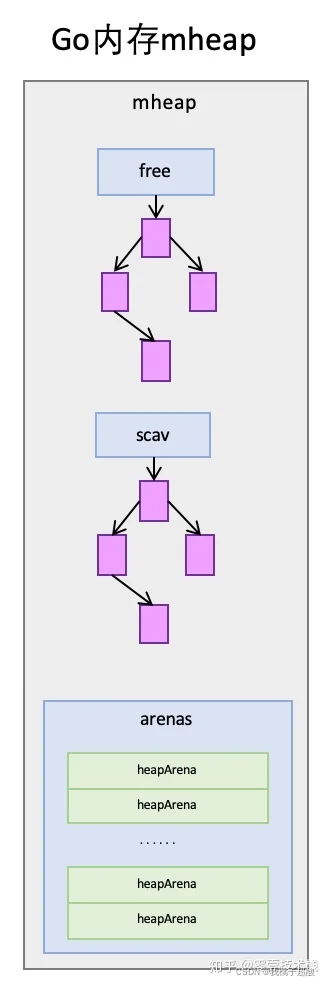
mheap中还有arenas,由一组heapArena组成,每一个heapArena都包含了连续的pagesPerArena个span,这个主要是为mheap管理span和垃圾回收服务。mheap本身是一个全局变量,它里面的数据,也都是从OS直接申请来的内存,并不在mheap所管理的那部分内存以内。
- mcentral向mheap申请span
当mcentral向mcache提供span时,如果empty里也没有符合条件的span,mcentral会向mheap申请span。
此时,mcentral需要向mheap提供需要的内存页数和span class级别,然后它优先从free中搜索可用的span。如果没有找到,会从scav中搜索可用的span。如果还没有找到,它会向OS申请内存,再重新搜索2棵树,必然能找到span。如果找到的span比需要的span大,则把span进行分割成2个span,其中1个刚好是需求大小,把剩下的span再加入到free中去,然后设置需要的span的基本信息,然后交给mcentral。
- mheap向OS申请内存
当mheap没有足够的内存时,mheap会向OS申请内存,把申请的内存页保存为span,然后把span插入到free树。在32位系统中,mheap还会预留一部分空间,当mheap没有空间时,先从预留空间申请,如果预留空间内存也没有了,才向OS申请。
3.1.2. 大对象的内存分配
大对象的分配比小对象省事多了,99%的流程与mcentral向mheap申请内存的相同,所以不重复介绍了。不同的一点在于mheap会记录一点大对象的统计信息,详情见mheap.alloc_m()。
3.2. Go垃圾回收和内存释放
如果只申请和分配内存,内存终将枯竭。Go使用垃圾回收收集不再使用的span,调用mspan.scavenge()把span释放还给OS(并非真释放,只是告诉OS这片内存的信息无用了,如果你需要的话,收回去好了),然后交给mheap,mheap对span进行span的合并,把合并后的span加入scav树中,等待再分配内存时,由mheap进行内存再分配,Go垃圾回收也是一个很强的主题,计划后面单独写一篇文章介绍。
现在我们关注一下,Go程序是怎么把内存释放给操作系统的?释放内存的函数是sysUnused,它会被mspan.scavenge()调用:
func sysUnused(v unsafe.Pointer, n uintptr) {
// MADV_FREE_REUSABLE is like MADV_FREE except it also propagates
// accounting information about the process to task_info.
madvise(v, n, _MADV_FREE_REUSABLE)
}
注释说 _MADV_FREE_REUSABLE 与 MADV_FREE 的功能类似,它的功能是给内核提供一个建议:这个内存地址区间的内存已经不再使用,可以进行回收。但内核是否回收,以及什么时候回收,这就是内核的事情了。如果内核真把这片内存回收了,当Go程序再使用这个地址时,内核会重新进行虚拟地址到物理地址的映射。所以在内存充足的情况下,内核也没有必要立刻回收内存。
4. Go的栈内存
最后提一下栈内存。从一个宏观的角度看,内存管理不应当只有堆,也应当有栈。每个goroutine都有自己的栈,栈的初始大小是2KB,100万的goroutine会占用2G,但goroutine的栈会在2KB不够用时自动扩容,当扩容为4KB的时候,百万goroutine会占用4GB。
总结Go的内存分配原理就不再回顾了,它主要强调两个重要的思想:
使用缓存提高效率。在存储的整个体系中到处可见缓存的思想,Go内存分配和管理也使用了缓存,利用缓存一是减少了系统调用的次数,二是降低了锁的粒度、减少加锁的次数,从这2点提高了内存管理效率。
以空间换时间,提高内存管理效率。空间换时间是一种常用的性能优化思想,这种思想其实非常普遍,比如Hash、Map、二叉排序树等数据结构的本质就是空间换时间,在数据库中也很常见,比如数据库索引、索引视图和数据缓存等,再如Redis等缓存数据库也是空间换时间的思想。