
1. 如何顺序控制goroutine
如何保证在一个 goroutine 中看到在另一个 goroutine 修改的变量的值,如果程序中修改数据时有其他 goroutine 同时读取,那么必须将读取串行化。为了串行化访问,请使用 channel 或其他同步原语,例如 sync 和 sync/atomic 来保护数据。
Happen-Before
在一个 goroutine 中,读和写一定是按照程序中的顺序执行的。即编译器和处理器只有在不会改变这个 goroutine 的行为时才可能修改读和写的执行顺序。由于重排,不同的goroutine 可能会看到不同的执行顺序。例如,一个goroutine 执行 a = 1;b = 2;,另一个 goroutine 可能看到 b 在 a 之前更新。

happen-beforehappen-beforeψ(`∇´)ψ
2. 内存模型官方文档
核心内容引用都来自于go的官方文档[https://golang.org/ref/mem]
官方文档的开篇就对go的内存模型做了一个简单的介绍
The Go memory model specifies the conditions under which reads of a variable in one goroutine can be guaranteed to observe values produced by writes to the same variable in a different goroutine.
Programs that modify data being simultaneously accessed by multiple goroutines must serialize such access.
To serialize access, protect the data with channel operations or other synchronization primitives such as those in the sync and sync/atomic packages.
译文:
简单的说就是:Go内存模型限定了一些条件 满足这些条件 才能让变量 安全地在不同的goroutine之间读写。换句话说就是如何保证在一个 goroutine中看到在另一个goroutine修改的变量的值,如果程序中修改数据时有其他 goroutine 同时读取,那么必须将读取串行化。为了串行化访问,请使用 channel 或其他同步原语,例如 sync 和 sync/atomic 来保护数据。
3. Happen-Before
Within a single goroutine, reads and writes must behave as if they executed in the order specified by the program. That is, compilers and processors may reorder the reads and writes executed within a single goroutine only when the reordering does not change the behavior within that goroutine as defined by the language specification. Because of this reordering, the execution order observed by one goroutine may differ from the order perceived by another. For example, if one goroutine executes a = 1; b = 2;, another might observe the updated value of b before the updated value of a.
To specify the requirements of reads and writes, we define happens before, a partial order on the execution of memory operations in a Go program. If event e1 happens before event e2, then we say that e2 happens after e1. Also, if e1 does not happen before e2 and does not happen after e2, then we say that e1 and e2 happen concurrently.
Within a single goroutine, the happens-before order is the order expressed by the program.
A read r of a variable v is allowed to observe a write w to v if both of the following hold:
r does not happen before w.
There is no other write w' to v that happens after w but before r.
To guarantee that a read r of a variable v observes a particular write w to v, ensure that w is the only write r is allowed to observe. That is, r is guaranteed to observe w if both of the following hold:
w happens before r.
Any other write to the shared variable v either happens before w or after r.
This pair of conditions is stronger than the first pair; it requires that there are no other writes happening concurrently with w or r.
Within a single goroutine, there is no concurrency, so the two definitions are equivalent: a read r observes the value written by the most recent write w to v. When multiple goroutines access a shared variable v, they must use synchronization events to establish happens-before conditions that ensure reads observe the desired writes.
The initialization of variable v with the zero value for v's type behaves as a write in the memory model.
Reads and writes of values larger than a single machine word behave as multiple machine-word-sized operations in an unspecified order.
译文:
在一个goroutine中,读和写必须按照程序指定的顺序执行。也就是说,只有当内存重排没有改变既定的代码的逻辑顺序时,编译器和处理器才可以重新排序在单个goroutine中执行的读写操作。由于这种重新排序,一个goroutine观察到的执行顺序可能与另一个goroutine感知到的执行顺序不同。例如,如果一个goroutine执行a=1;b=2;,那么另一个goroutine可能会在a的更新值之前观察到b的更新值。
为了指定读写的要求,我们定义了在Go程序中执行内存操作的偏序。如果事件e1发生在事件e2之前,那么我们说e2发生在事件e1之后。同样,如果e1不发生在e2之前,也不发生在e2之后,那么我们说e1和e2同时发生。
在一个goroutine中,happens before顺序即是程序表示的逻辑顺序。
如果以下两个条件都成立,则允许变量v的read r观察到w到v的写入:
r不发生在w之前。
在w之后,r之前,没有其他写入w'到v的操作。
要保证变量v的read r观察到特定的对v的write操作,请确保w是唯一允许r观察的write。也就是说,如果以下两个条件都成立,r保证观察到w:
w发生在r之前。
对共享变量v的任何其他写入要么发生在w之前,要么发生在r之后。
第二个的约定明显比第一个要强的多;它要求没有其他写操作与w或r同时发生。
在单个goroutine中,没有并发性,因此这两个定义是等价的:read r观察最新write w写入v的值。当多个goroutine访问共享变量v时,它们必须使用同步事件来建立条件,以确保read观察到所需的写操作。
变量v的初始化(v的类型为零值)表现为在内存模型中写入。
对大于单个机器字的值的读取和写入,按照未指定的顺序执行多个机器字大小的操作。
PS:对于最后的machine word的解释,比如说是64位的操作系统,64bit=8byte,意思就是在64位的操作系统,不可能出现单个线程在写入数据时,数据小于等于8字节的就不会出现中断,要是写入的数据是16字节的,对于并发的写入而言就不知道是先写入前一半还是后一半了。
简单的总结一下文档的内容:
为了说明读和写的必要条件,我们定义了先行发生(Happens Before)。如果事件 e1 发生在 e2 前,我们可以说 e2 发生在 e1 后。如果 e1不发生在 e2 前也不发生在 e2 后,我们就说 e1 和 e2 是并发的。
在单一的独立的 goroutine 中先行发生的顺序即是程序中表达的顺序。
当下面条件满足时,对变量 v 的读操作 r 是被允许看到对 v 的写操作 w 的:
r 不先行发生于 w
在 w 后 r 前没有对 v 的其他写操作
为了保证对变量 v 的读操作 r 看到对 v 的写操作 w,要确保 w 是 r 允许看到的唯一写操作。即当下面条件满足时,r 被保证看到 w:
w 先行发生于 r
其他对共享变量 v 的写操作要么在 w 前,要么在 r 后。
这一对条件比前面的条件更严格,需要没有其他写操作与 w 或 r 并发发生。
单个 goroutine 中没有并发,所以上面两个定义是相同的:
读操作 r 看到最近一次的写操作 w 写入 v 的值。
当多个 goroutine 访问共享变量 v 时,它们必须使用同步事件来建立先行发生这一条件来保证读操作能看到需要的写操作。
对变量 v 的零值初始化在内存模型中表现的与写操作相同。
对大于 single machine word 的变量的读写操作表现的像以不确定顺序对多个 single machine word的变量的操作。
4. Memory Reordering(内存重排)
Happen-Before中所表述的内容是整个go的内存模型的核心,其中就提到一个,goroutineA中有两个赋值操作,a=1,b=2,可能在goroutineB看来可能看到的是b=2执行在先,a=1执行在后。出现这种情况的原因就是cpu的内存重排机制。
用户写下的代码,先要编译成汇编代码,也就是各种指令,包括读写内存的指令。CPU 的设计者们,为了榨干 CPU 的性能,无所不用其极,各种手段都用上了,你可能听过不少,像流水线、分支预测等等。其中,为了提高读写内存的效率,会对读写指令进行重新排列,这就是所谓的 内存重排,也就是MemoryReordering。
举两个例子:
X = 0
for i in range(100):
X = 1
print X
X = 1
for i in range(100):
print X
第一个代码段想要表述的逻辑非常简单,把X=1给赋值100次,站在实际的视角上来审视这段代码,这样的操作没有任何意义,根据上面讲述的重排的理论,我们的CPU会帮我们做一个处理,有可能就变成了第二段的代码。两段代码从结果上看是等价的,我这里仅仅说的是不是并发的情况下。
现在有一个问题如果此时有另外一个线程干了这么一件事情: X=0,那么这两段代码的结果还会等价嘛。答案是大概率不等价,编译器是无法感知到是否有一个线程在修改一个公共变量的值的。重排导致的幺蛾子 [○・`Д´・ ○]
再举一个例子:
var A,B int
go func(){
A = 1
fmt.Println(B)
}()
go func(){
B = 1
fmt.Println(A)
}()
代码执行结果,是1 0? 0 1? 0 0 ? 1 1 ?实际上可能会出现是0 0。这就很奇怪了,为啥是0 0。这个结果的出现和内存重排的关系很大。
现代 CPU 为了“抚平” 内核、内存、硬盘之间的速度差异,搞出了各种策略,例如三级缓存等。速度最快的当然是CPU核心,接下来是L1Cache再接下来是L2 Cache最后是L3 Cache,L3 Cache不同的线程之间是可以共享的。
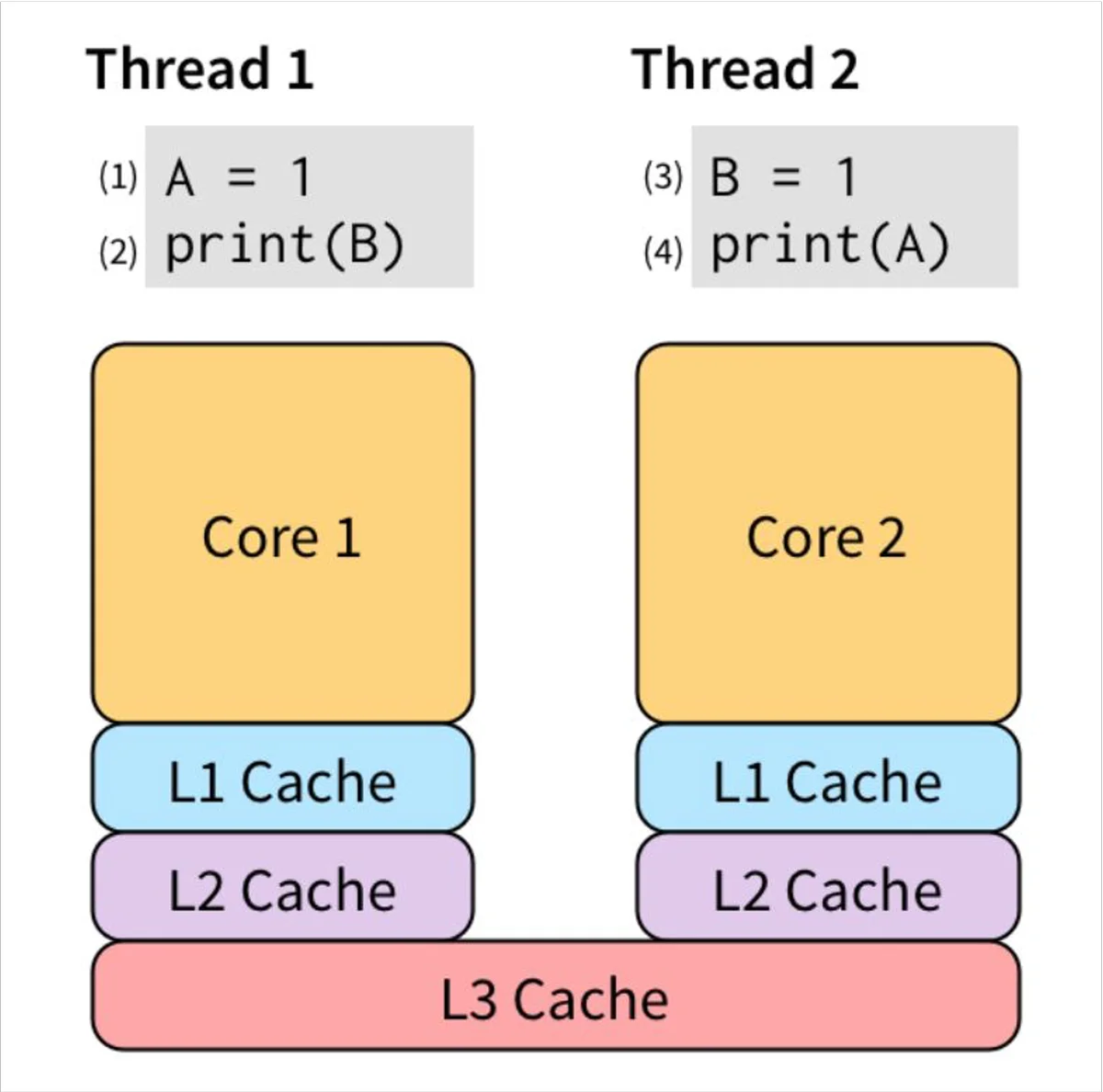
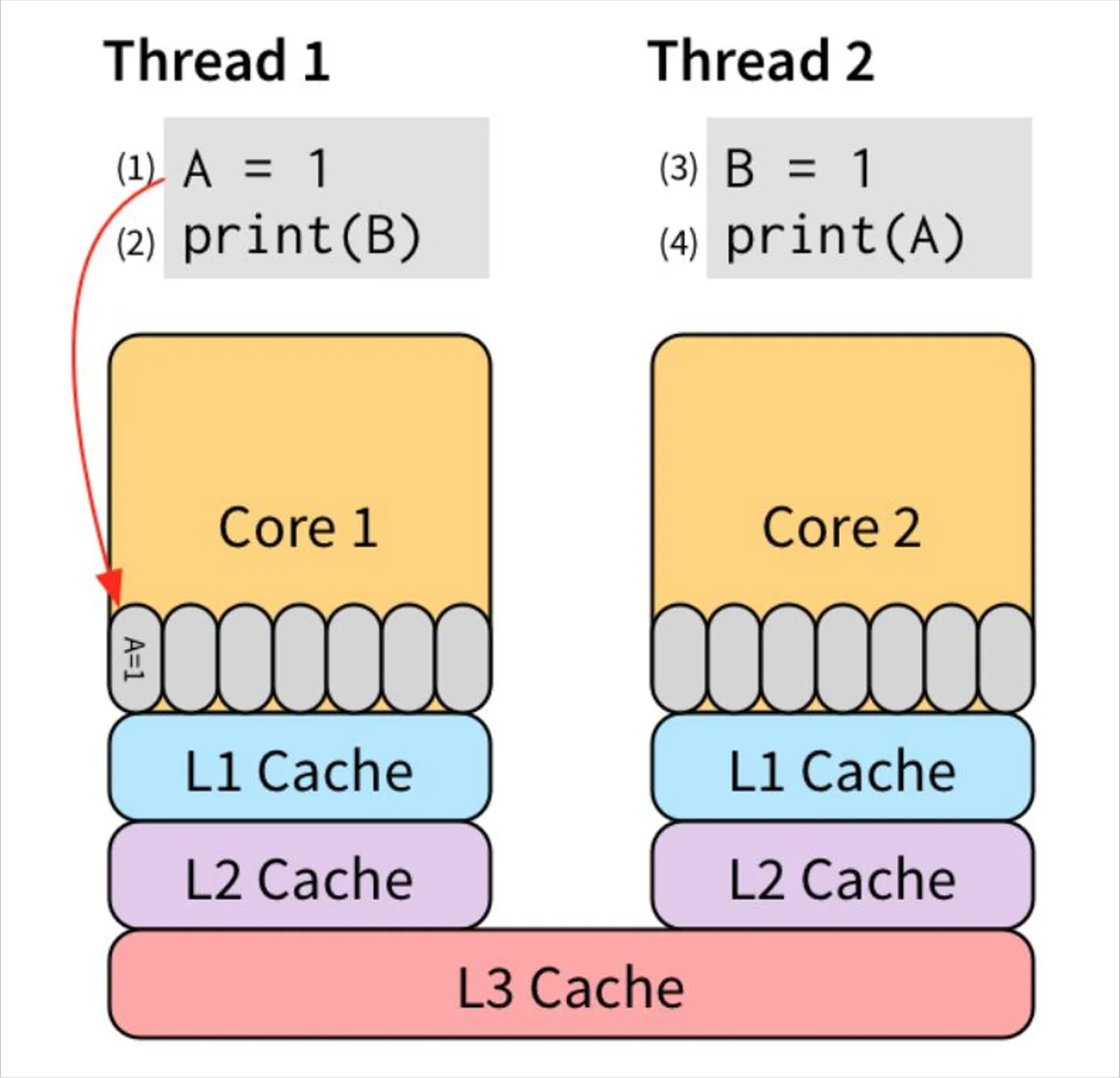
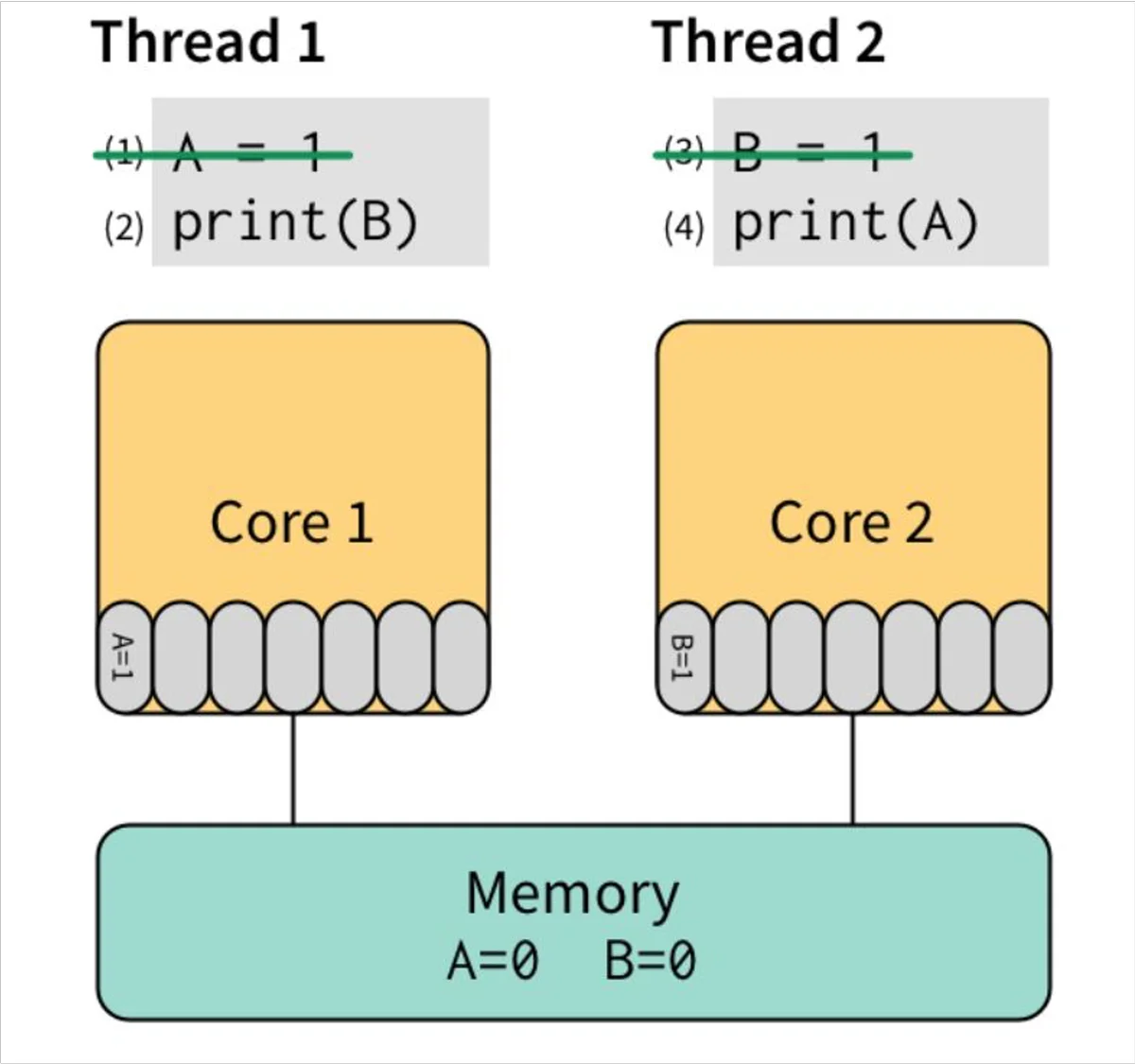
借着这两张图我们回头看一看代码,goroutine1对A赋了值,CPU核心会快速的执行该操作,不过在打印B的值的时候,goroutine从L1 Cache开始找一只找到L3 Cache,只在L3 Cache中找到了B的默认初始值0,所以goroutine打印出了0。同理goroutine2也只能打印出0。这就是出现0 0的原因。第三张图就解释了文字描述的过程。对于多线程的程序,所有的CPU都会提供“锁”支持,称之为barrier,或者fence。它要求:barrier指令要求所有对内存的操作都必须要“扩散”到memory之后才能继续执行其他对memory的操作。因此,我们可以用高级点的atomic compare-and-swap(CAS),或者直接用更高级的锁,通常是标准库提供。
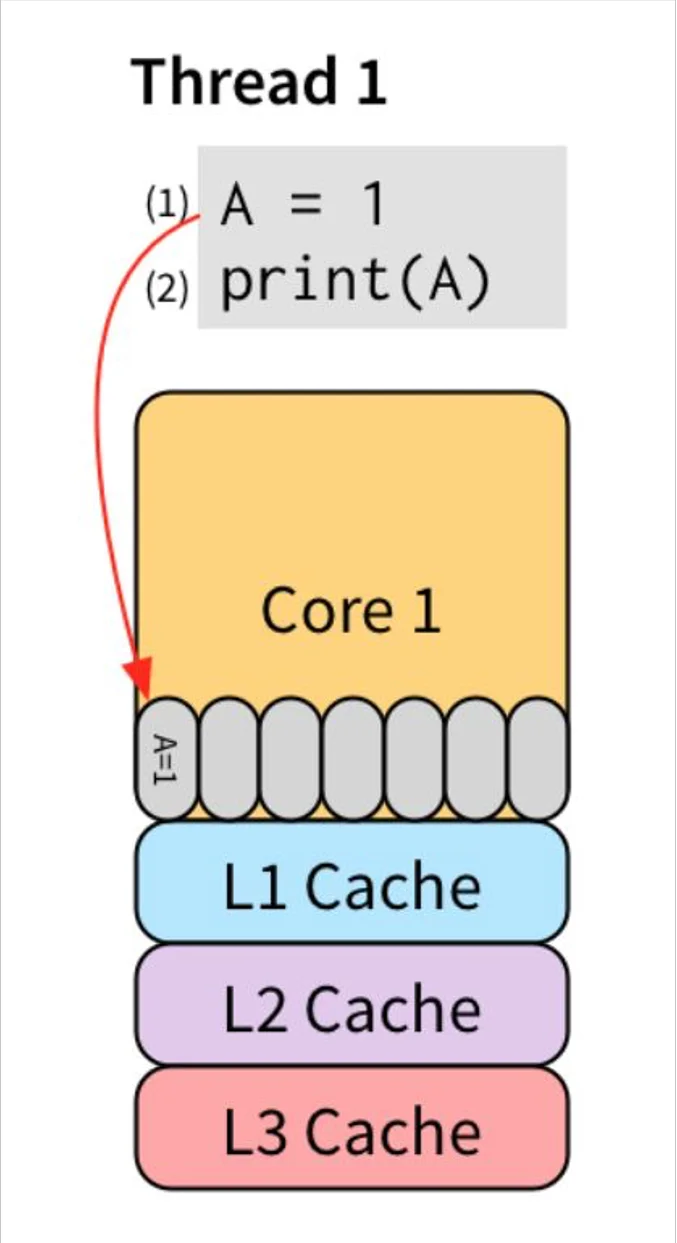
反过来看如果是单线程,那么store buffer(特指L1 L2 L3 cache)是完美的,如下图所示。
5. 小结
go的内存模型要解决的问题就是多个线程进行原子赋值的同时,期待线程(goroutine)之间可以互相看到原子赋值之后的值,也就是可见性问题。了解machine word,machine word表示写入操作的原子性,要么成功要么失败,这点和mysql是一样的。不过不建议用machine word去干一些讨巧的事情,比如x86 64bit的cpu处理器,machine word是8byte,在go中,比如map,指针对象等等 这些都是8byte的,你可以很放心的去读,因为不存在读到一半的问题,可是要是有一个对象是16byte的,你能知道是先写前半个还是后半个嘛,这就会导致问题了。所以还是要谨慎。