
写在前面
Map的实现主要有两种方式:哈希表(hash table)和搜索树(search tree)。例如Java中的hashMap是基于哈希表实现,而C++中的Map是基于一种平衡搜索二叉树——红黑树而实现的。Go中map的基于哈希表(也被称为散列表)实现。
哈希表
哈希表通常会有一堆桶来存储键值对,一个键值对会选择一个桶,怎么选择?
先通过哈希函数把键处理一下,得到一个哈希值,通过这个哈希值去选择相对应的桶
取模法:hash%(桶的个数m)得到一个桶编号
与运算法:hash&(m-1)
要限制桶的个数m必须是2的整数次幂
如何解决哈希冲突的问题?
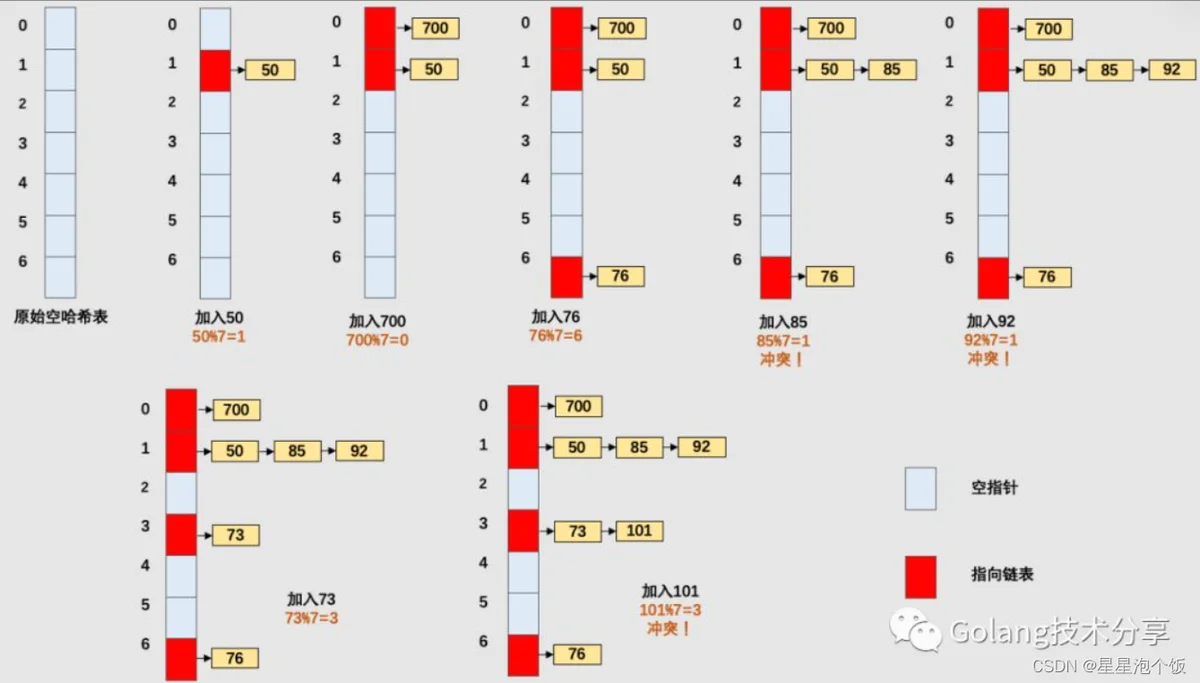
1.链表地址法
写结构体的时候加入next指针

遇到冲突时,将数据写到next的位置
下面以一个简单的哈希函数 H(key) = key MOD 7(除数取余法)对一组元素 [50, 700, 76, 85, 92, 73,101] 进行映射,通过图示来理解链地址法处理Hash冲突的处理逻辑。
2.开放地址法
把其他下标的地址都对外开放
开放地址的方法:1.线性探测法2.平方探测(二次方探测)3.双哈希
开放地址—线性探测法
如果遇到冲突,就往下一个地址寻找空位,新位置=原始位置+i ( i是查找的次数 )

其中15,2,28,4进行模运算,都为2,遇到冲突,就会往下一个地址寻找空位
12,38进行模运算,都为12,遇到冲突,就会往下一个地址寻找空位
开放地址—平方探测法
如果遇到冲突,就往(原地址 + i ² )的位置寻找空位,新位置=原始位置+ i ² ( i是查找的次数 )

开放地址—双哈希
要设置第二个哈希的函数,例如:hash2(key)=R-(key mod R)
R要取比数组尺寸小的指指数
例如R取7 hash2(关键字)=7-(关键字%7)
如果遇到冲突,新位置=原始位置+i*hash2(关键字)

Go Map实现
map数据结构
map中的数据被存放于一个数组中的,数组的元素是桶(bucket),每个桶至多包含8个键值对数据。哈希值低位(low-order bits)用于选择桶,哈希值高位(high-order bits)用于在一个独立的桶中区别出键。哈希值高低位示意图如下

Go语言中的map是也基于哈希表实现的,它解决哈希冲突的方式是链地址法,即通过使用数组+链表的数据结构来表达map
map的结构体为hmap
// A header for a Go map.
type hmap struct {
count int // 代表哈希表中的元素个数,调用len(map)时,返回的就是该字段值。
flags uint8 // 状态标志,下文常量中会解释四种状态位含义。
B uint8 // buckets(桶)的对数log_2(哈希表元素数量最大可达到装载因子*2^B)
noverflow uint16 // 溢出桶的大概数量。
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 指向buckets数组的指针,数组大小为2^B,如果元素个数为0,它为nil。
oldbuckets unsafe.Pointer // 如果发生扩容,oldbuckets是指向老的buckets数组的指针,老的buckets数组大小是新的buckets的1/2。非扩容状态下,它为nil。
nevacuate uintptr // 表示扩容进度,小于此地址的buckets代表已搬迁完成。
extra *mapextra // 这个字段是为了优化GC扫描而设计的。当key和value均不包含指针,并且都可以inline时使用。extra是指向mapextra类型的指针。
bmap结构体(map的桶)
// A bucket for a Go map.
type bmap struct {
// tophash包含此桶中每个键的哈希值最高字节(高8位)信息(也就是前面所述的high-order bits)。
// 如果tophash[0] < minTopHash,tophash[0]则代表桶的搬迁(evacuation)状态。
tophash [bucketCnt]uint8
}
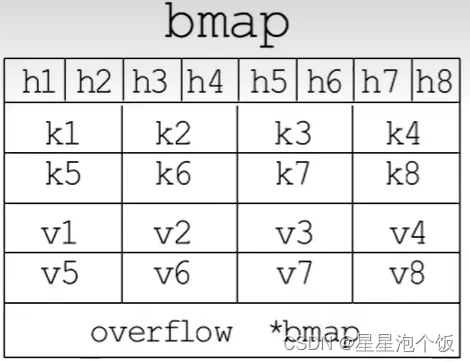
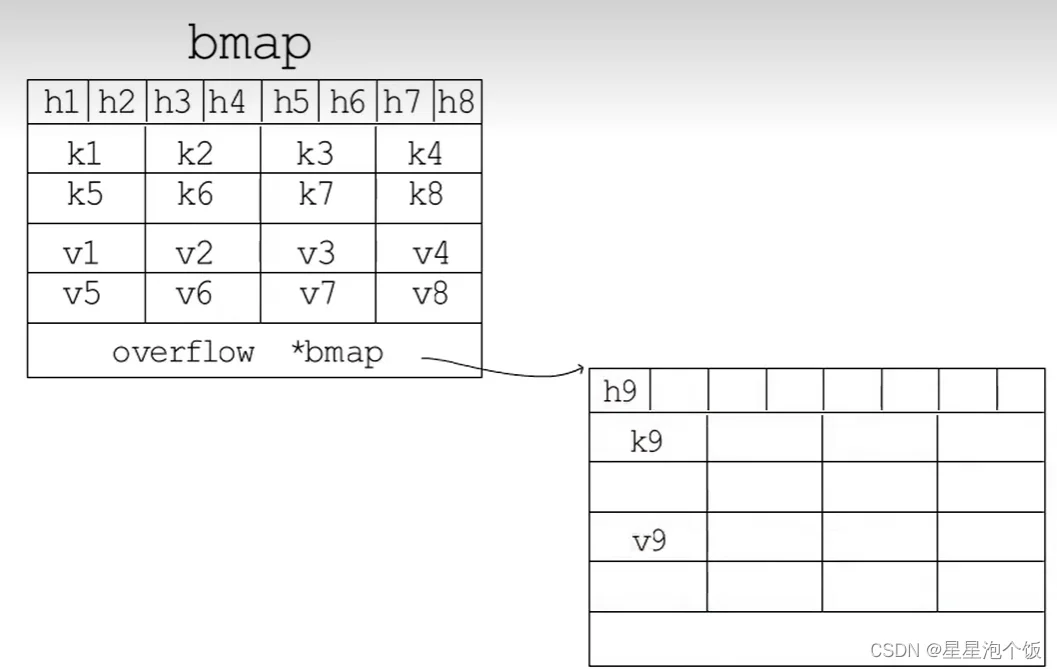
在8个键值对数据后面有一个overflow指针,因为桶中最多只能装8个键值对,如果有多余的键值对落到了当前桶,那么就需要再构建一个桶(称为溢出桶),通过overflow指针链接起来。溢出桶的内存布局和常规桶相同,是为了减少扩容次数而引入的,当一个桶存满了还有可用的溢出桶时,就会在桶后面链一个溢出桶
Map扩容
触发扩容的条件:
1.负载因子 > 6.5时,也即平均每个bucket存储的键值对达到6.5个,进行增量扩容
2.overflow数量 > 2^15时,也即overflow数量超过32768时,进行等量扩容
增量扩容
当负载因子大于6.5时,就新建一个bucket桶,新的bucket长度是原来的2倍,然后旧bucket数据搬迁到新的bucket。
等量扩容
所谓等量扩容,实际上并不是扩大容量,buckets数量不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。
在极端场景下,比如不断地增删,而键值对正好集中在一小部分的bucket,这样会造成overflow的bucket数量增多,但负载因子又不高,从而无法执行增量搬迁的情况