
1.什么是 map
维基百科里这样定义 map:
In computer science, an associative array, map, symbol table, or dictionary is an abstract data type composed of a collection of (key, value) pairs, such that each possible key appears at most once in the collection.
key-valuekey和 map 相关的操作主要是:
1.增加一个 k-v 对 —— Add or insert;
2.删除一个 k-v 对 —— Remove or delete;
3.修改某个 k 对应的 v —— Reassign;
4.查询某个 k 对应的 v —— Lookup;
增删查改哈希查找表(Hash table)搜索树(Search tree)哈希查找表用一个哈希函数将 key 分配到不同的桶(bucket,也就是数组的不同 index)。这样,开销主要在哈希函数的计算以及数组的常数访问时间。在很多场景下,哈希查找表的性能很高。
链表法开放地址法链表法开放地址法搜索树法一般采用自平衡搜索树,包括:AVL 树,红黑树。面试时经常会被问到,甚至被要求手写红黑树代码,很多时候,面试官自己都写不上来,非常过分。
自平衡搜索树法的最差搜索效率是 O(logN),而哈希查找表最差是 O(N)。当然,哈希查找表的平均查找效率是 O(1),如果哈希函数设计的很好,最坏的情况基本不会出现。还有一点,遍历自平衡搜索树,返回的 key 序列,一般会按照从小到大的顺序;而哈希查找表则是乱序的。
2.map 的底层如何实现
首先声明我用的 Go 版本:
go version go1.9.2 darwin/amd64
前面说了 map 实现的几种方案,Go 语言采用的是哈希查找表,并且使用链表解决哈希冲突。
接下来我们要探索 map 的核心原理,一窥它的内部结构。
2.1map内存模型
在源码中,表示 map 的结构体是 hmap,它是 hashmap 的“缩写”:
// A header for a Go map.
type hmap struct {
// 元素个数,调用 len(map) 时,直接返回此值
count int
flags uint8
// buckets 的对数 log_2
B uint8
// overflow 的 bucket 近似数
noverflow uint16
// 计算 key 的哈希的时候会传入哈希函数
hash0 uint32
// 指向 buckets 数组,大小为 2^B
// 如果元素个数为0,就为 nil
buckets unsafe.Pointer
// 等量扩容的时候,buckets 长度和 oldbuckets 相等
// 双倍扩容的时候,buckets 长度会是 oldbuckets 的两倍
oldbuckets unsafe.Pointer
// 指示扩容进度,小于此地址的 buckets 迁移完成
nevacuate uintptr
extra *mapextra // optional fields
}
Bbuckets 是一个指针,最终它指向的是一个结构体:
type bmap struct {
tophash [bucketCnt]uint8
}
但这只是表面(src/runtime/hashmap.go)的结构,编译期间会给它加料,动态地创建一个新的结构:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
bmap来一个整体的图:
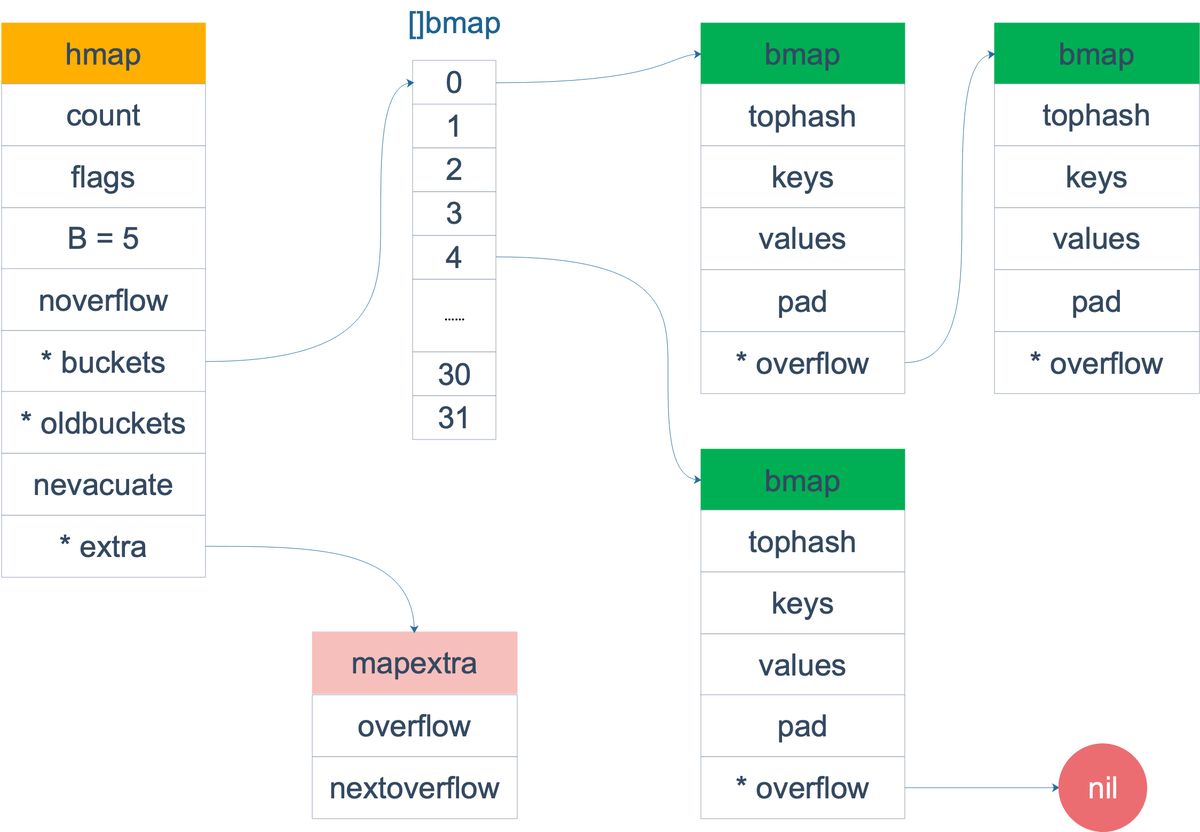
当 map 的 key 和 value 都不是指针,并且 size 都小于 128 字节的情况下,会把 bmap 标记为不含指针,这样可以避免 gc 时扫描整个 hmap。但是,我们看 bmap 其实有一个 overflow 的字段,是指针类型的,破坏了 bmap 不含指针的设想,这时会把 overflow 移动到 extra 字段来。
type mapextra struct {
// overflow[0] contains overflow buckets for hmap.buckets.
// overflow[1] contains overflow buckets for hmap.oldbuckets.
overflow [2]*[]*bmap
// nextOverflow 包含空闲的 overflow bucket,这是预分配的 bucket
nextOverflow *bmap
}
bmap 是存放 k-v 的地方,我们把视角拉近,仔细看 bmap 的内部组成。
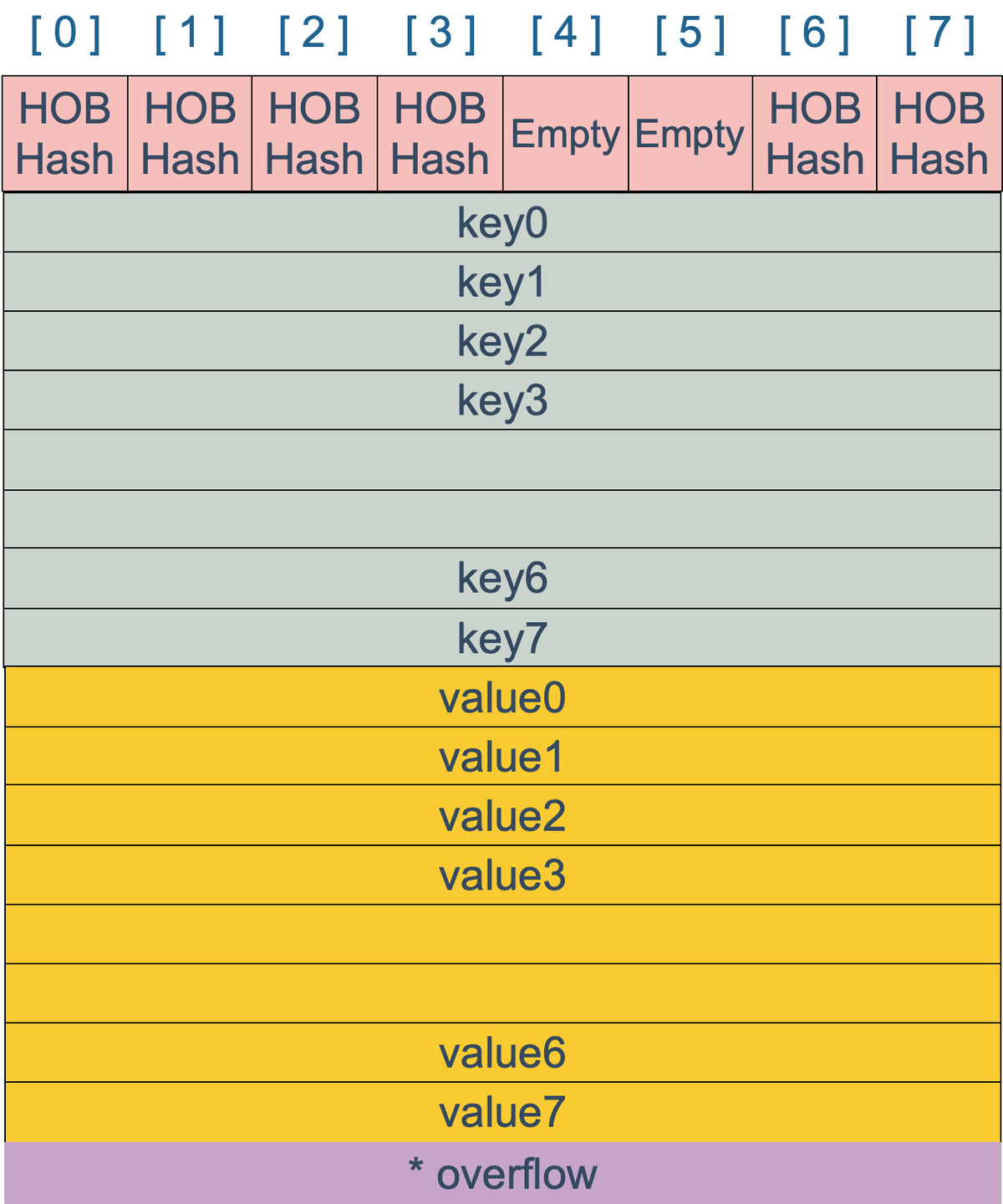
HOB Hashkey/value/key/value/...例如,有这样一个类型的 map:
map[int64]int8
key/value/key/value/...key/key/.../value/value/...overflow2.2创建 map
语法层面上来说,创建 map 很简单:
ageMp := make(map[string]int)
// 指定 map 长度
ageMp := make(map[string]int, 8)
// ageMp 为 nil,不能向其添加元素,会直接panic
var ageMp map[string]int
makemaphmapfunc makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap {
// 省略各种条件检查...
// 找到一个 B,使得 map 的装载因子在正常范围内
B := uint8(0)
for ; overLoadFactor(hint, B); B++ {
}
// 初始化 hash table
// 如果 B 等于 0,那么 buckets 就会在赋值的时候再分配
// 如果长度比较大,分配内存会花费长一点
buckets := bucket
var extra *mapextra
if B != 0 {
var nextOverflow *bmap
buckets, nextOverflow = makeBucketArray(t, B)
if nextOverflow != nil {
extra = new(mapextra)
extra.nextOverflow = nextOverflow
}
}
// 初始化 hamp
if h == nil {
h = (*hmap)(newobject(t.hmap))
}
h.count = 0
h.B = B
h.extra = extra
h.flags = 0
h.hash0 = fastrand()
h.buckets = buckets
h.oldbuckets = nil
h.nevacuate = 0
h.noverflow = 0
return h
}
【引申1】slice 和 map 分别作为函数参数时有什么区别?
*hmapmakesliceSlicefunc makeslice(et *_type, len, cap int) slice
回顾一下 slice 的结构体定义:
// runtime/slice.go
type slice struct {
array unsafe.Pointer // 元素指针
len int // 长度
cap int // 容量
}
结构体内部包含底层的数据指针。
makemap 和 makeslice 的区别,带来一个不同点:当 map 和 slice 作为函数参数时,在函数参数内部对 map 的操作会影响 map 自身;而对 slice 却不会(之前讲 slice 的文章里有讲过)。
*hmapslice*hmap2.3哈希函数
alginit()src/runtime/alg.gohash 函数,有加密型和非加密型。
加密型的一般用于加密数据、数字摘要等,典型代表就是 md5、sha1、sha256、aes256 这种;
非加密型的一般就是查找。在 map 的应用场景中,用的是查找。
选择 hash 函数主要考察的是两点:性能、碰撞概率。
之前我们讲过,表示类型的结构体:
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldalign uint8
kind uint8
alg *typeAlg
gcdata *byte
str nameOff
ptrToThis typeOff
}
alg// src/runtime/alg.go
type typeAlg struct {
// (ptr to object, seed) -> hash
hash func(unsafe.Pointer, uintptr) uintptr
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
}
typeAlg 包含两个函数,hash 函数计算类型的哈希值,而 equal 函数则计算两个类型是否“哈希相等”。
对于 string 类型,它的 hash、equal 函数如下:
func strhash(a unsafe.Pointer, h uintptr) uintptr {
x := (*stringStruct)(a)
return memhash(x.str, h, uintptr(x.len))
}
func strequal(p, q unsafe.Pointer) bool {
return *(*string)(p) == *(*string)(q)
}
根据 key 的类型,_type 结构体的 alg 字段会被设置对应类型的 hash 和 equal 函数。
2.4key 定位过程
key 经过哈希计算后得到哈希值,共 64 个 bit 位(64位机,32位机就不讨论了,现在主流都是64位机),计算它到底要落在哪个桶时,只会用到最后 B 个 bit 位。还记得前面提到过的 B 吗?如果 B = 5,那么桶的数量,也就是 buckets 数组的长度是 2^5 = 32。
例如,现在有一个 key 经过哈希函数计算后,得到的哈希结果是:
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010
01010再用哈希值的高 8 位,找到此 key 在 bucket 中的位置,这是在寻找已有的 key。最开始桶内还没有 key,新加入的 key 会找到第一个空位,放入。
buckets 编号就是桶编号,当两个不同的 key 落在同一个桶中,也就是发生了哈希冲突。冲突的解决手段是用链表法:在 bucket 中,从前往后找到第一个空位。这样,在查找某个 key 时,先找到对应的桶,再去遍历 bucket 中的 key。
这里参考曹大 github 博客里的一张图,原图是 ascii 图,geek 味十足,可以从参考资料找到曹大的博客,推荐大家去看看。
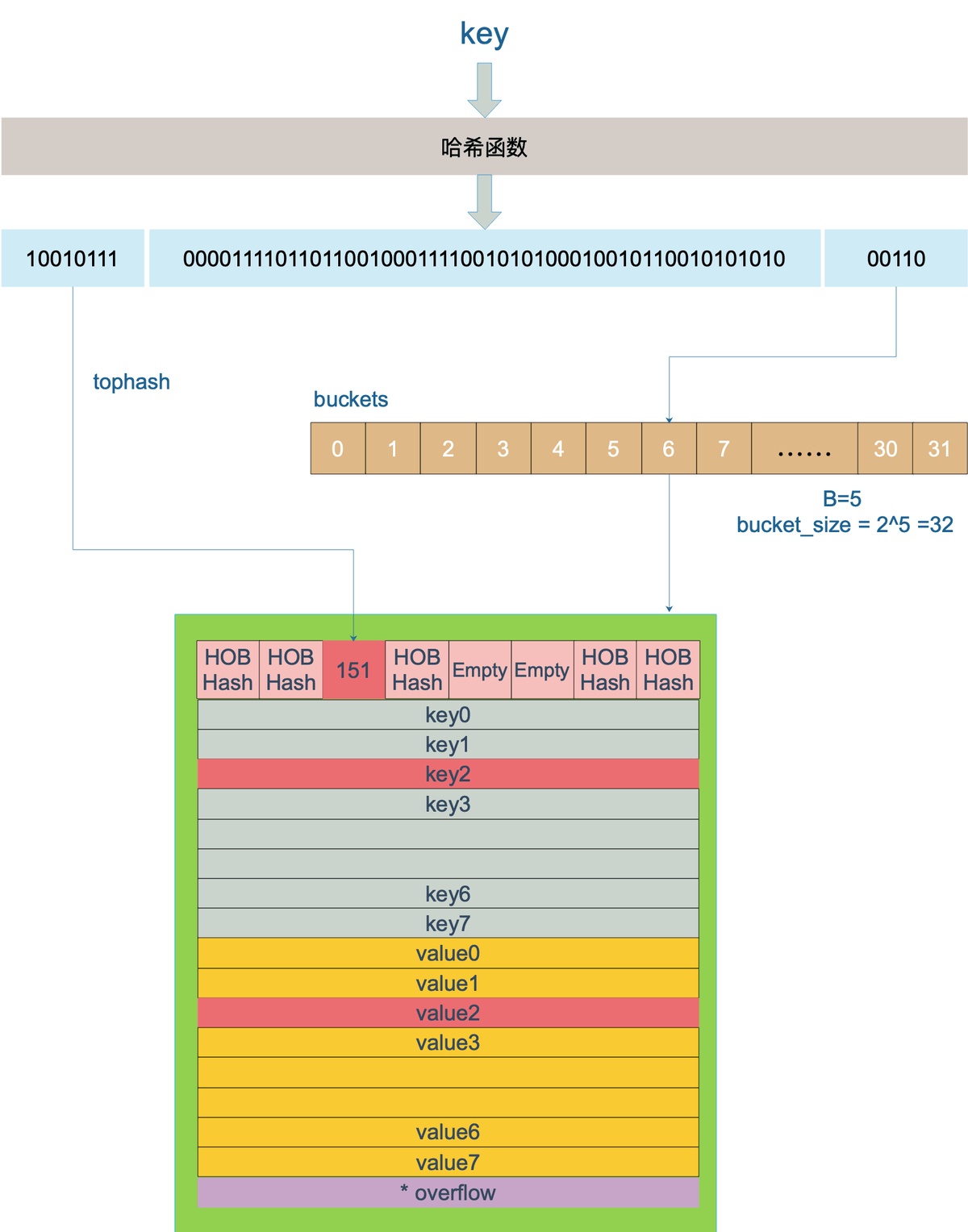
0011010010111如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket。
mapacessmapacess1func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// ……
// 如果 h 什么都没有,返回零值
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0])
}
// 写和读冲突
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 不同类型 key 使用的 hash 算法在编译期确定
alg := t.key.alg
// 计算哈希值,并且加入 hash0 引入随机性
hash := alg.hash(key, uintptr(h.hash0))
// 比如 B=5,那 m 就是31,二进制是全 1
// 求 bucket num 时,将 hash 与 m 相与,
// 达到 bucket num 由 hash 的低 8 位决定的效果
m := uintptr(1)<<h.B - 1
// b 就是 bucket 的地址
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// oldbuckets 不为 nil,说明发生了扩容
if c := h.oldbuckets; c != nil {
// 如果不是同 size 扩容(看后面扩容的内容)
// 对应条件 1 的解决方案
if !h.sameSizeGrow() {
// 新 bucket 数量是老的 2 倍
m >>= 1
}
// 求出 key 在老的 map 中的 bucket 位置
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// 如果 oldb 没有搬迁到新的 bucket
// 那就在老的 bucket 中寻找
if !evacuated(oldb) {
b = oldb
}
}
// 计算出高 8 位的 hash
// 相当于右移 56 位,只取高8位
top := uint8(hash >> (sys.PtrSize*8 - 8))
// 增加一个 minTopHash
if top < minTopHash {
top += minTopHash
}
for {
// 遍历 bucket 的 8 个位置
for i := uintptr(0); i < bucketCnt; i++ {
// tophash 不匹配,继续
if b.tophash[i] != top {
continue
}
// tophash 匹配,定位到 key 的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// key 是指针
if t.indirectkey {
// 解引用
k = *((*unsafe.Pointer)(k))
}
// 如果 key 相等
if alg.equal(key, k) {
// 定位到 value 的位置
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
// value 解引用
if t.indirectvalue {
v = *((*unsafe.Pointer)(v))
}
return v
}
}
// bucket 找完(还没找到),继续到 overflow bucket 里找
b = b.overflow(t)
// overflow bucket 也找完了,说明没有目标 key
// 返回零值
if b == nil {
return unsafe.Pointer(&zeroVal[0])
}
}
}
函数返回 h[key] 的指针,如果 h 中没有此 key,那就会返回一个 key 相应类型的零值,不会返回 nil。
代码整体比较直接,没什么难懂的地方。跟着上面的注释一步步理解就好了。
这里,说一下定位 key 和 value 的方法以及整个循环的写法。
// key 定位公式
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
// value 定位公式
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
b 是 bmap 的地址,这里 bmap 还是源码里定义的结构体,只包含一个 tophash 数组,经编译器扩充之后的结构体才包含 key,value,overflow 这些字段。dataOffset 是 key 相对于 bmap 起始地址的偏移:
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
因此 bucket 里 key 的起始地址就是 unsafe.Pointer(b)+dataOffset。第 i 个 key 的地址就要在此基础上跨过 i 个 key 的大小;而我们又知道,value 的地址是在所有 key 之后,因此第 i 个 value 的地址还需要加上所有 key 的偏移。理解了这些,上面 key 和 value 的定位公式就很好理解了。
再说整个大循环的写法,最外层是一个无限循环,通过
b = b.overflow(t)
遍历所有的 bucket,这相当于是一个 bucket 链表。
当定位到一个具体的 bucket 时,里层循环就是遍历这个 bucket 里所有的 cell,或者说所有的槽位,也就是 bucketCnt=8 个槽位。整个循环过程:
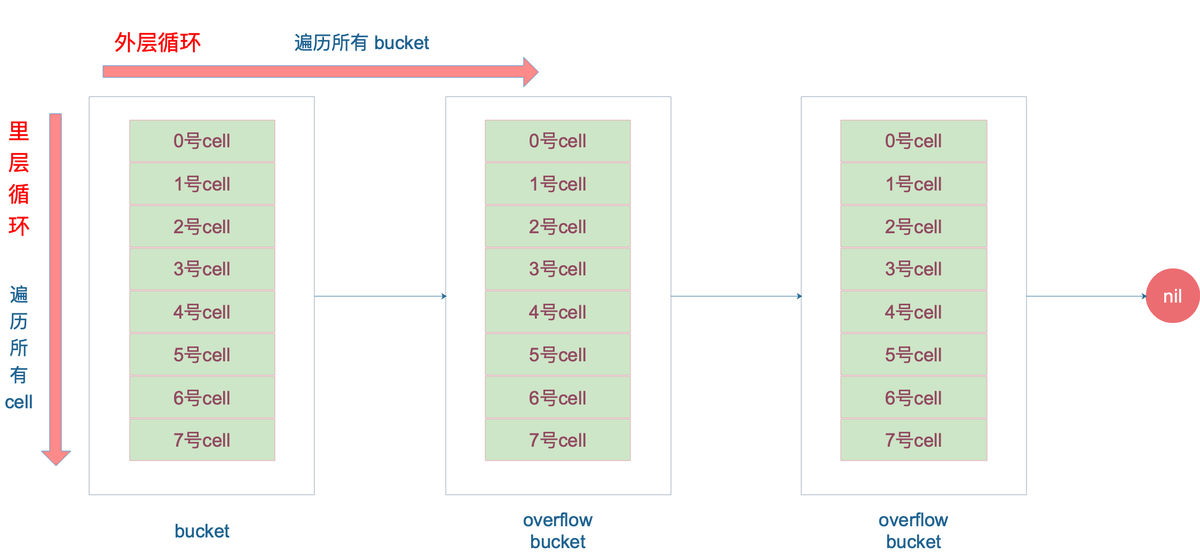
再说一下 minTopHash,当一个 cell 的 tophash 值小于 minTopHash 时,标志这个 cell 的迁移状态。因为这个状态值是放在 tophash 数组里,为了和正常的哈希值区分开,会给 key 计算出来的哈希值一个增量:minTopHash。这样就能区分正常的 top hash 值和表示状态的哈希值。
下面的这几种状态就表征了 bucket 的情况:
// 空的 cell,也是初始时 bucket 的状态
empty = 0
// 空的 cell,表示 cell 已经被迁移到新的 bucket
evacuatedEmpty = 1
// key,value 已经搬迁完毕,但是 key 都在新 bucket 前半部分,
// 后面扩容部分会再讲到。
evacuatedX = 2
// 同上,key 在后半部分
evacuatedY = 3
// tophash 的最小正常值
minTopHash = 4
源码里判断这个 bucket 是否已经搬迁完毕,用到的函数:
func evacuated(b *bmap) bool {
h := b.tophash[0]
return h > empty && h < minTopHash
}
evacuatedEmptyevacuatedXevacuatedY