
深度之眼学习心得
实验:人民币二分类,训练一个二分类器,可以区别出第四套人民币的1元与100元。
模型训练的5大步骤,数据,模型,损失函数,优化器,迭代训练
本文只探讨数据。
数据:数据收集---img,label
数据分割---train,valid,test
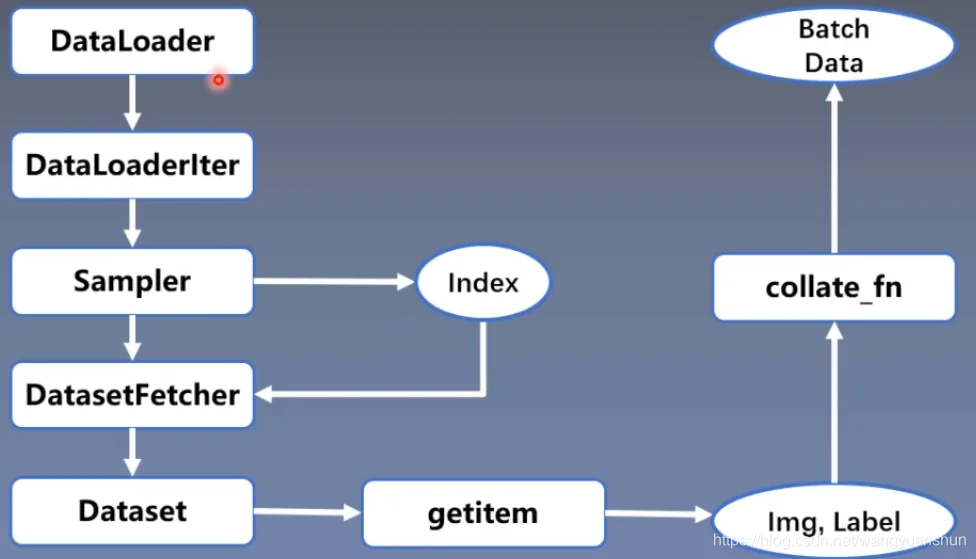
数据读取---DataLoader(Sampler(生成索引),Dataset(根据索引拿到img and label))
数据预处理---transforms
DataLoader:构建可迭代的数据装载器
torch.utils.data.DataLoader(dataset,batch_size=1,shuffle=False,sampler=None,batch_sampler=None,num_workers=0,
collate_fn=None,pin_memory=None,drop_last=False,timeout=0,worker_init_fn=None,multiprocessing_context=None)
dataset:Dataset类,决定数据从哪儿读及如何读
batch_size:批大小
shuffle:训练样本的每个epoch是否乱序
num_workers:读取数据的进程数量
drop_last:当样本数不能被batch_size整除时,是否舍弃最后一批数据。
三个常用名称之间的关系:
epoch:所有训练样本都输入到模型中一次,称之为一个epoch
iteration:一批样本输入到模型中,称之为一个iteration
batch_size:一批样本的样本个数,称之为batch_size,它决定一个epoch有多少个iteration。
例如:一个epoch为120个样本,若batch_size=10,那么有12个iteration
一个epoch为125个样本,若batch_size=10,drop_last=True,那么有12个iteration
drop_last=False,那么有13个iteration,最后一个iteration样本数量<batch_size
Dataset:Dataset抽象类,所有自定义的Dataset需要继承它,并且复写__getitem__(),getitem接收索引并返回样本(img,label)
数据读取:读哪些数据:每个iteration应该读哪batch_size个样本,Sampler输出的Index
从哪儿读数据:设置硬盘数据路径,Dataset中的data_dir
如何读取数据:Dataset中的getitem
数据读取如图:
博客写的不规范,主要为了便于查找及知识记忆。
下一篇将数据预处理--transforms