


曾几何时,几百G的硬盘就能容下我们的小电影,放到互联网时代,数据的规模不断增长,几个T的存储空间也显得渺小。
在《》里我总结了读的问题,缓存就能解决90%以上的问题,可是对于程序员来讲,“写多”的场景才是硬核,才具有挑战性。
在阅读本篇前,我还曾写过一篇《》,里面有一句话我一直喜欢:能用简单的方式解决80%的问题,也比复杂的方案解决95%的方式优先;
今天呢,我想把大规模海量数据的“写”问题,抛砖引玉,试着去讲明白。


“写”的核心难点主要有以上三点。
1.数据存储容量的问题。
既然动不动处理的就是T 或者更大的 PB 计的数据问题,而一般的服务器磁盘容量通常 1~2TB,那么如何存储这么大规模的数据呢?
2.数据读写速度的问题。
一般磁盘的连续读写速度为几十 MB,以这样的速度,几十 PB 的数据恐怕要读写到天荒地老。
3.数据可靠性的问题。
磁盘大约是计算机设备中最易损坏的硬件了,通常情况一块磁盘使用寿命大概是一年,如果磁盘损坏了,数据怎么办?
后来出现的所有存储技术,目标很明确,就是解决这三个问题。
一、单机-单磁盘
在很久很久以前,硬件成本很高,每台机器就一个磁盘,那当时是怎么进行优化的呢,很显然,那会数据的容量不是主要问题,反而是强大的CPU运转与磁盘数据读写速度是主要矛盾。
当然了,放到现在,这些技术我们一直还在使用,是什么?
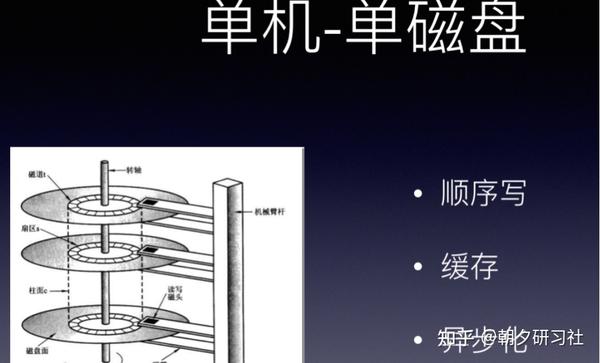
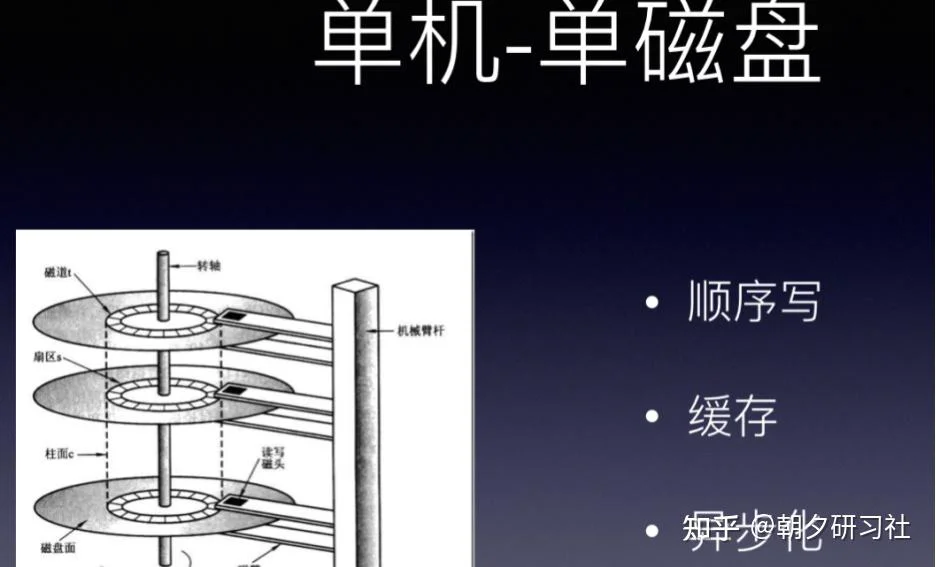
单机-单磁盘时代,主要使用了三种技术。
首先我们需要有些共识:
其实磁盘顺序读写还是很快的,没有想象的那么慢,有多快?顺序写的性能堪比写内存,你说有多快。
为了让你强化这个认知,我们看国外的测试报告:
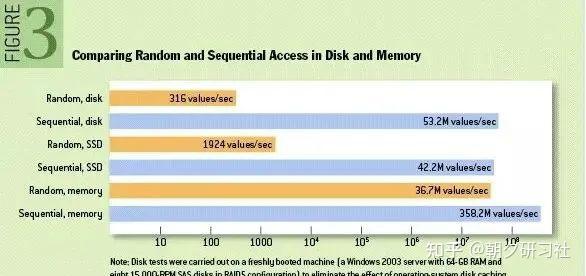
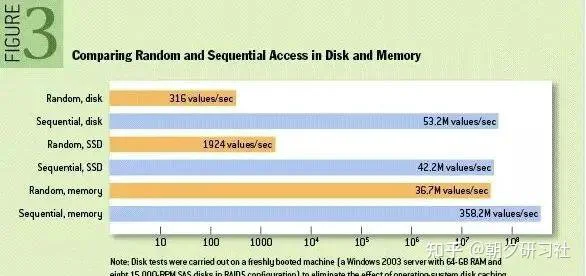
性能测试的结果表明普通机械磁盘的顺序I/O性能指标是53.2M values/s,SSD的顺序I/O性能指标是42.2M values/s,而内存的随机I/O性能指标是36.7M values/s。
不过这个报告,网上有很多的版本,说数据不准确,不过我想说的意思,应该明白:顺序写真的很快。
现实中的数据写入往往不是那么如意,随机的场景更多,那么有没有什么方式可以将顺序读写这个优势利用起来呢?
当然有了,缓存/缓冲 + 异步化 就是一种很好的办法。
我们常用的mysql 数据库就是这样做的。
其实数据库不过也是文件系统的一种,是“锁”的引入,才让数据库腾飞,说多了。
我们知道缓存能提高读的性能,数据库将很大一部分数据存放在内存中,当程序要修改数据库中数据,不是真正修改磁盘中数据,而是写把操作记录(注意是操作记录,不是要修改的数据)写到磁盘缓冲区,这个磁盘缓冲区就是物理内存的一部分,所以写性能,不是问题。
程序将数据写到缓冲区就够了,剩下的事交给操作系统,操作系统或者应用程序的一个线程会专门做这件事,将缓冲区的数据,顺序的写到磁盘上,数据库的高性能就是这么简单。
这里面使用了异步,将写数据和同步磁盘进行分离,增加吞吐能力。
还有一个最牛逼的MQ中间件,kafka也是同样的道理,日志数据写到缓冲区,剩下的慢慢写磁盘。
当然了,这里面有个也算严重的问题。
牺牲掉了一些可靠性,毕竟物理内存断电易丢失的问题还是无法避免,所以,这些文件系统都提供了一个可选参数:写磁盘的频率。
简单理解是是一操作就写一次磁盘,还是批量几次操作再写,还是压根就不写。
可以根据不同的场景的可靠性要求去配置。


我们看单机-单磁盘下,三个问题中,只有读写性能这方面有提高,其他差强人意。
二、单机-多磁盘
上面提到,容量问题以及可靠性在单机-单磁盘时代没有改进,对付这两个,有什么方法?
想想一下,葫芦娃救爷爷还得六个一起上呢,何况笨重的磁盘,怎么招,也得组团吧。
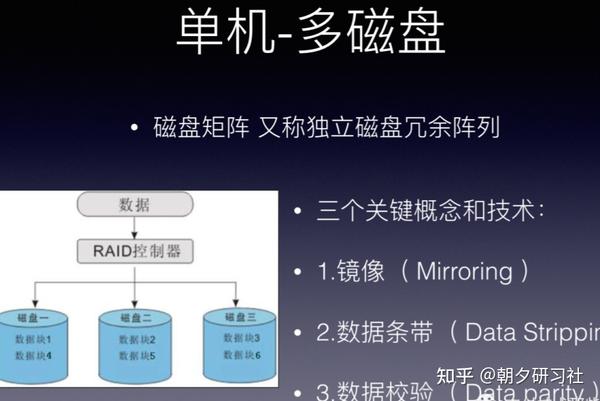
RAID ( Redundant Array of Independent Disks )即独立磁盘冗余阵列,通常简称为磁盘阵列。
简单地说, RAID 是由多个独立的高性能磁盘驱动器组成的磁盘子系统,从而提供比单个磁盘更高的存储性能和数据冗余的技术。
RAID(独立磁盘冗余阵列)技术是将多块普通磁盘组成一个阵列,共同对外提供服务。
主要是为了改善磁盘的存储容量、读写速度,增强磁盘的可用性和容错能力。
目前服务器级别的计算机都支持插入多块磁盘(8 块或者更多),通过使用 RAID 技术,实现数据在多块磁盘上的并发读写和数据备份。
RAID 中主要有三个关键概念和技术:镜像( Mirroring )、数据条带( Data Stripping )和数据校验( Data parity ) 。
镜像,将数据复制到多个磁盘,一方面可以提高可靠性,另一方面可并发从两个或多个副本读取数据来提高读性能。显而易见,镜像的写性能要稍低, 确保数据正确地写到多个磁盘需要更多的时间消耗。
数据条带,将数据分片保存在多个不同的磁盘,多个数据分片共同组成一个完整数据副本,这与镜像的多个副本是不同的,它通常用于性能考虑。数据条带具有更高的并发粒度,当访问数据时,可以同时对位于不同磁盘上数据进行读写操作, 从而获得非常可观的 I/O 性能提升 。
数据校验,利用冗余数据进行数据错误检测和修复,冗余数据通常采用海明码、异或操作等算法来计算获得。利用校验功能,可以很大程度上提高磁盘阵列的可靠性、鲁棒性和容错能力。不过,数据校验需要从多处读取数据并进行计算和对比,会影响系统性能。不同等级的 RAID 采用一个或多个以上的三种技术,来获得不同的数据可靠性、可用性和 I/O 性能。
下面我们介绍几个常用的RAID。
我们先假设服务器有 N 块磁盘。
RAID 0。
数据在从内存缓冲区写入磁盘时,根据磁盘数量将数据分成 N 份,这些数据同时并发写入 N 块磁盘,使得数据整体写入速度是一块磁盘的 N 倍;读取的时候也一样,因此 RAID 0 具有极快的数据读写速度。但是 RAID 0 不做数据备份,N 块磁盘中只要有一块损坏,数据完整性就被破坏,其他磁盘的数据也都无法使用了。
结论:能一定范围内解决存储,读写性能问题,但是可用性不能保证。
RAID 1
数据在写入磁盘时,将一份数据同时写入两块磁盘,这样任何一块磁盘损坏都不会导致数据丢失,插入一块新磁盘就可以通过复制数据的方式自动修复,具有极高的可靠性。
结论:磁盘空间利用率不高,只能使用一半。
结合 RAID 0 和 RAID 1 两种方案构成了 RAID 10,它是将所有磁盘 N 平均分成两份,数据同时在两份磁盘写入,相当于 RAID 1;但是平分成两份,在每一份磁盘(也就是 N/2 块磁盘)里面,利用 RAID 0 技术并发读写,这样既提高可靠性又改善性能。不过 RAID 10 的磁盘利用率较低,有一半的磁盘用来写备份数据。
一般情况下,一台服务器上很少出现同时损坏两块磁盘的情况,在只损坏一块磁盘的情况下,如果能利用其他磁盘的数据恢复损坏磁盘的数据,这样在保证可靠性和性能的同时,磁盘利用率也得到大幅提升。
顺着这个思路,RAID 3 可以在数据写入磁盘的时候,将数据分成 N-1 份,并发写入 N-1 块磁盘,并在第 N 块磁盘记录校验数据,这样任何一块磁盘损坏,都可以利用其他 N-1 块磁盘的数据修复。
相比 RAID 3,RAID 5 是使用更多的方案。RAID 5 和 RAID 3 很相似,但是校验数据不是写入第 N 块磁盘,而是螺旋式地写入所有磁盘中。这样校验数据的修改也被平均到所有磁盘上,避免 RAID 3 频繁写坏一块磁盘的情况。
如果数据需要很高的可靠性,在出现同时损坏两块磁盘的情况下(或者运维管理水平比较落后,坏了一块磁盘但是迟迟没有更换,导致又坏了一块磁盘),仍然需要修复数据,这时候可以使用 RAID 6。
前面所述的各个 RAID 等级都只能保护因单个磁盘失效而造成的数据丢失。如果两个磁盘同时发生故障,数据将无法恢复。RAID6引入双重校验的概念,它可以保护阵列中同时出现两个磁盘失效时,阵列仍能够继续工作,不会发生数据丢失。RAID6 等级是在 RAID5 的基础上为了进一步增强数据保护而设计的一种 RAID 方式,它可以看作是一种扩展的 RAID5 等级。
总结一下单机-多磁盘的结果:


1.数据存储容量的问题。
RAID 使用了 N 块磁盘构成一个存储阵列,如果使用 RAID 5,数据就可以存储在 N-1 块磁盘上,这样将存储空间扩大了 N-1 倍。
2. 数据读写速度的问题。
RAID 根据可以使用的磁盘数量,将待写入的数据分成多片,并发同时向多块磁盘进行写入,显然写入的速度可以得到明显提高;同理,读取速度也可以得到明显提高。
3. 数据可靠性的问题。
使用 RAID 10、RAID 5 或者 RAID 6 方案的时候,由于数据有冗余存储,或者存储校验信息,所以当某块磁盘损坏的时候,可以通过其他磁盘上的数据和校验数据将丢失磁盘上的数据还原。
三、大数据分布式时代
如果单机能解决互联网时代的数据问题,也就没程序员什么事儿了。
开头讲过,现在的数据规模都是以PB计量的,单机加多磁盘总不是能无限的。
RAID 可以看作是一种垂直伸缩,一台计算机集成更多的磁盘实现数据更大规模、更安全可靠的存储以及更快的访问速度。
不过,这只是刚起步而已。


在大数据时代,分布式是主要的解决方案。
如果说RAID是单机下磁盘的伸缩,分布式就是整机的伸缩。
拿主流的大数据技术说起,不管计算、调度框架怎么改进,底层的数据存储依然非HDFS莫属。
HDFS 技术通过添加更多的服务器实现数据更大、更快、更安全存储与访问。
RAID 技术只是在单台服务器的多块磁盘上组成阵列,大数据需要更大规模的存储空间和更快的访问速度。将 RAID 思想原理应用到分布式服务器集群上,就形成了 Hadoop 分布式文件系统 HDFS 的架构思想。
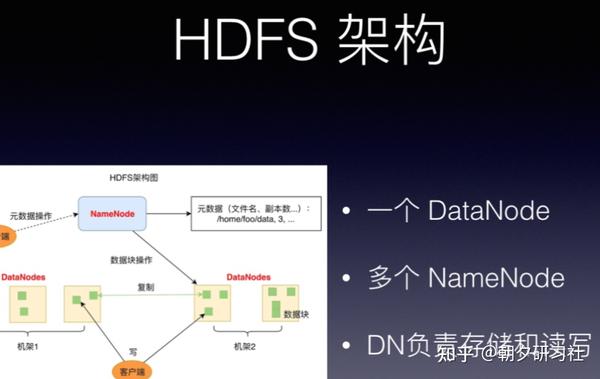
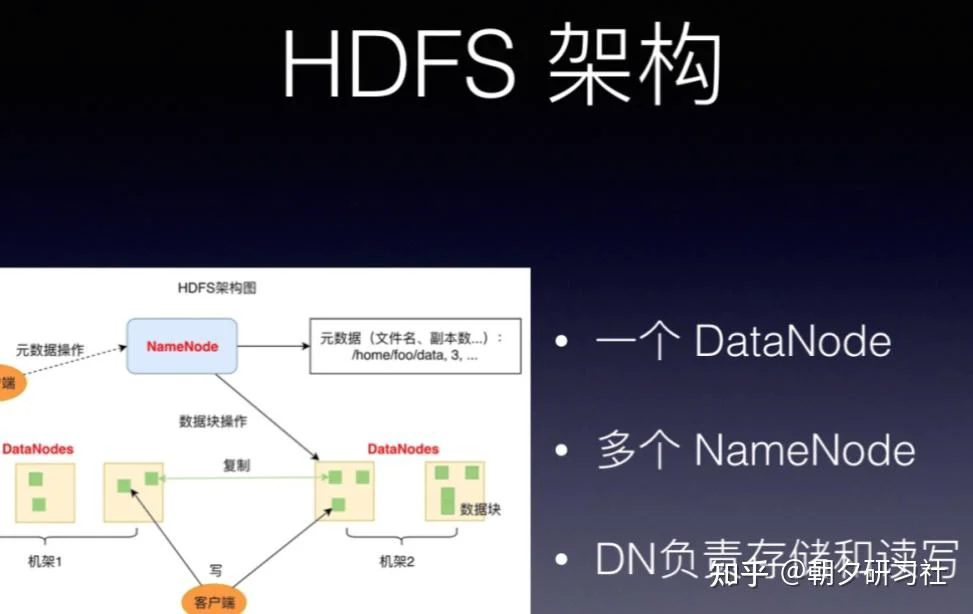
HDFS 的关键组件有两个,一个是 DataNode,一个是 NameNode。
DataNode 负责文件数据的存储和读写操作,HDFS 将文件数据分割成若干数据块(Block),每个 DataNode 存储一部分数据块,这样文件就分布存储在整个 HDFS 服务器集群中。
应用程序客户端(Client)可以并行对这些数据块进行访问,从而使得 HDFS 可以在服务器集群规模上实现数据并行访问,极大地提高了访问速度。
在实践中,HDFS 集群的 DataNode 服务器会有很多台,一般在几百台到几千台这样的规模,每台服务器配有数块磁盘,整个集群的存储容量大概在几 PB 到数百 PB。
分布式对于解决容量以及读写性能这点,不用怀疑。
那数据的可靠性又是怎么保证的呢?简单说明一下。
对于存储在 DataNode 上的数据块,计算并存储校验和。在读取数据的时候,重新计算读取出来的数据的校验和,如果校验不正确就抛出异常,应用程序捕获异常后就到其他 DataNode 上读取备份数据。
如果DataNode 监测到本机的某块磁盘损坏,就将该块磁盘上存储的所有 BlockID 报告给 NameNode,NameNode 检查这些数据块还在哪些 DataNode 上有备份,通知相应的 DataNode 服务器将对应的数据块复制到其他服务器上,以保证数据块的备份数满足要求。
看到没,这不就是我们追求的失效转移,自我修复吗?


通过分布式技术,大规模数据的三大问题再也不是问题了。
其实不仅仅大数据系统中使用了上面的技术,其他的技术道理是一样的。
比如,消息中间件 kafka.
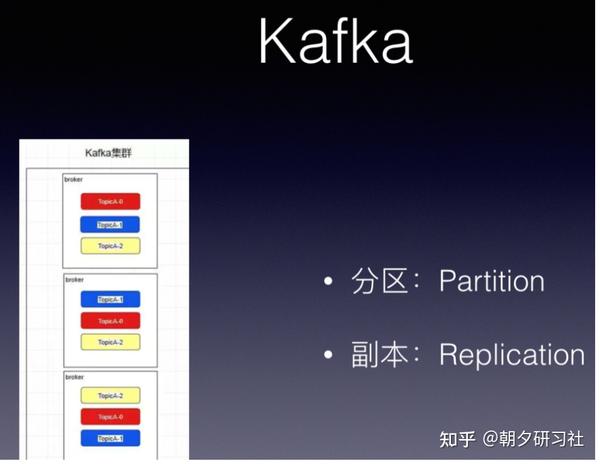
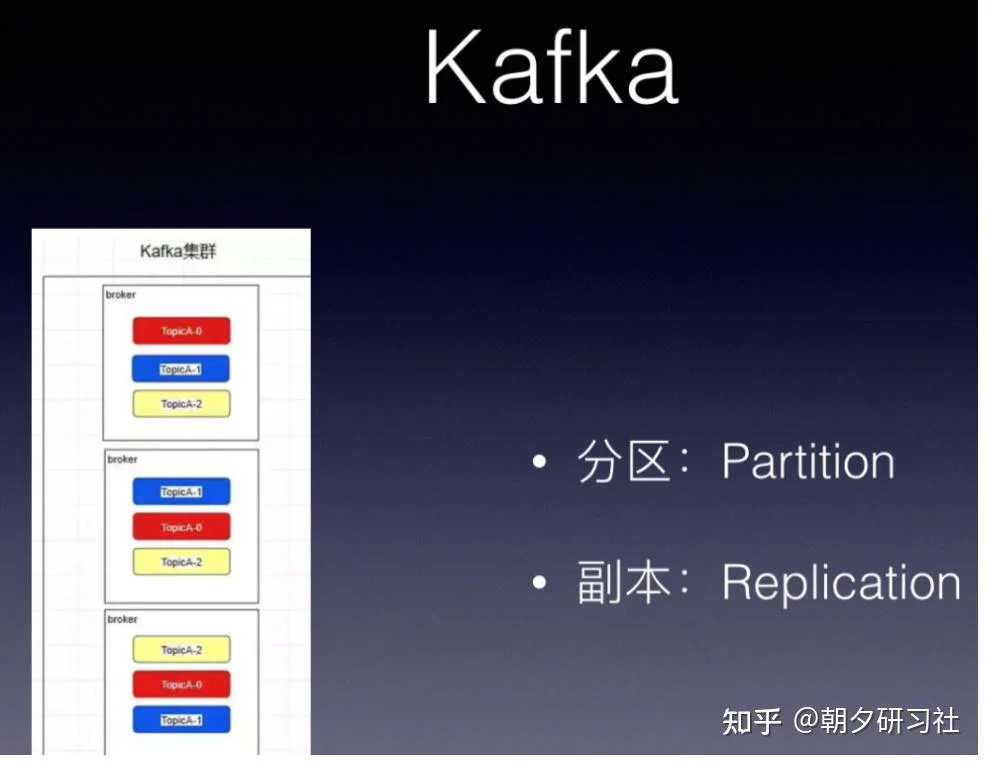
kafka有topic 还有一个概念叫Partition(分区),分区具体在服务器上面表现起初就是一个目录,一个主题下面有多个分区,这些分区会存储到不同的服务器上面,或者说,其实就是在不同的主机上建了不同的目录。
这些分区主要的信息就存在了.log文件里面。跟数据库里面的分区差不多,是为了提高性能。
kafka中的partition为了保证数据安全,所以每个partition可以设置多个副本。
而且其实每个副本都是有角色之分的,它们会选取一个副本作为leader,而其余的作为follower,我们的生产者在发送数据的时候,是直接发送到leader partition里面 ,然后follower partition会去leader那里自行同步数据,消费者消费数据的时候,也是从leader那去消费数据的 。
kafka为什么能处理上百万的数据?每一个Broker下其实也是利用磁盘的顺序写+异步+缓存等技术。
除了kafka,分布式的搜索引ES 也是同样的思想。
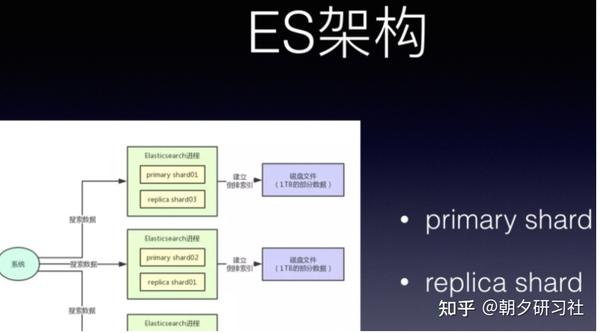
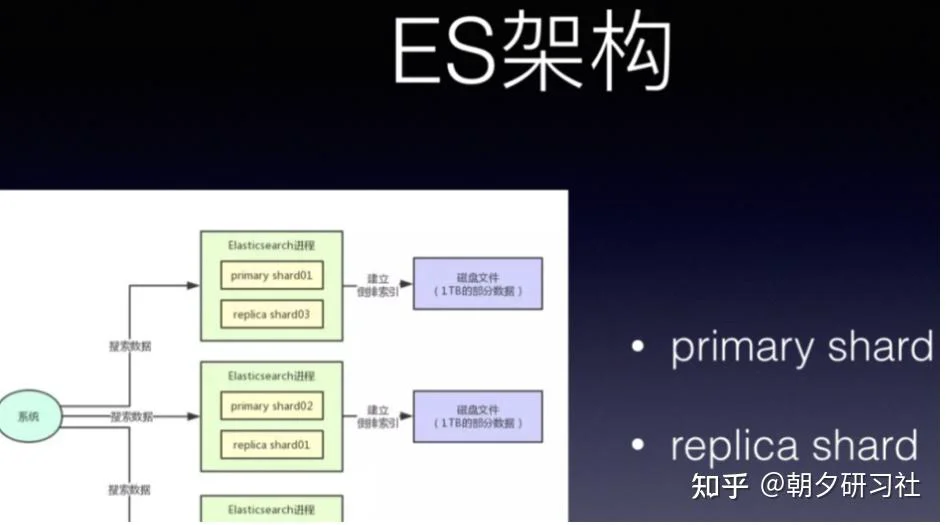
如同kafka 的 replica机制下,每个primary shard都有一个replica shard在别的机器上,任何一台机器宕机,都可以保证数据不会丢失,分布式搜索引擎继续可用。
Elasticsearch默认是支持每个index是5个primary shard,每个primary shard有1个replica shard作为副本.
这篇,写的有点累了,太长了,借用一句话收尾今天的文章:
管理好计算机资源主要包括两个方面,一个方面是把有限的资源使用得更有效率,另一个方面是能够使用好更多的资源。
整篇也是这个思想,压榨单机,将有限资源使用的更有效,同时利用分布式,使用更多的资源。