
1.前言
不要小瞧函数调用栈哦,它可是理解参数传递、命名匿名返回值、Function Value、defer等面试常客的关键呐~”
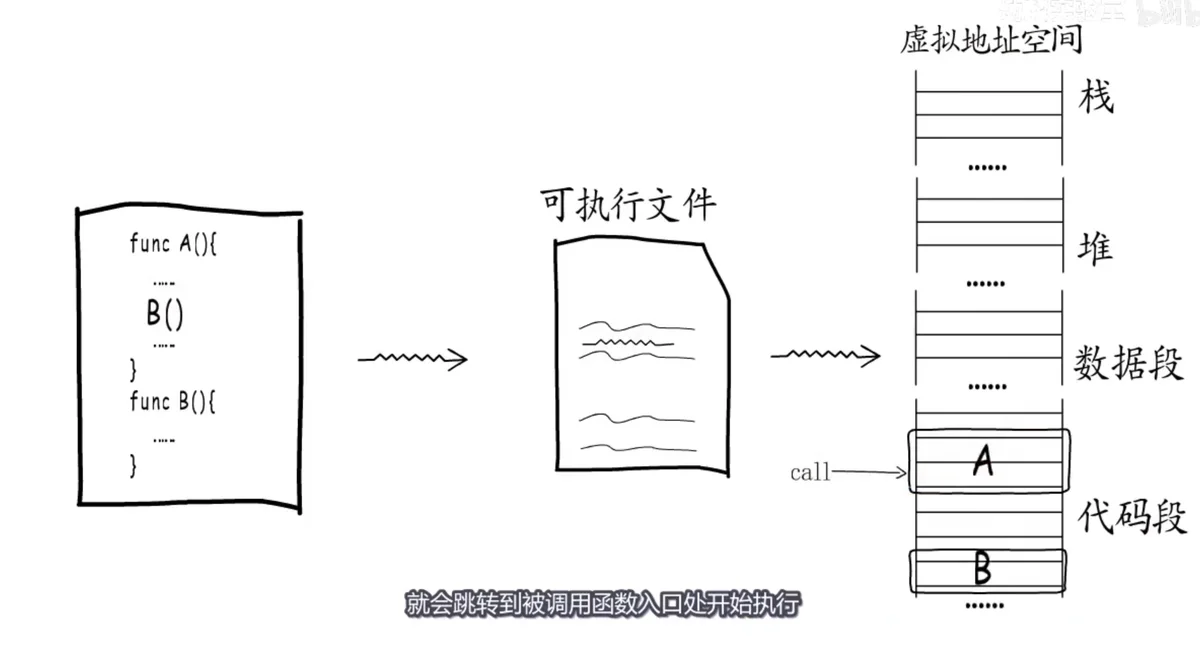
我们按照编程语言的语法定义的函数,会被编译器编译为一堆堆机器指令,写入可执行文件。程序执行时可执行文件被加载到内存,这些机器指令对应到虚拟地址空间中,位于代码段。
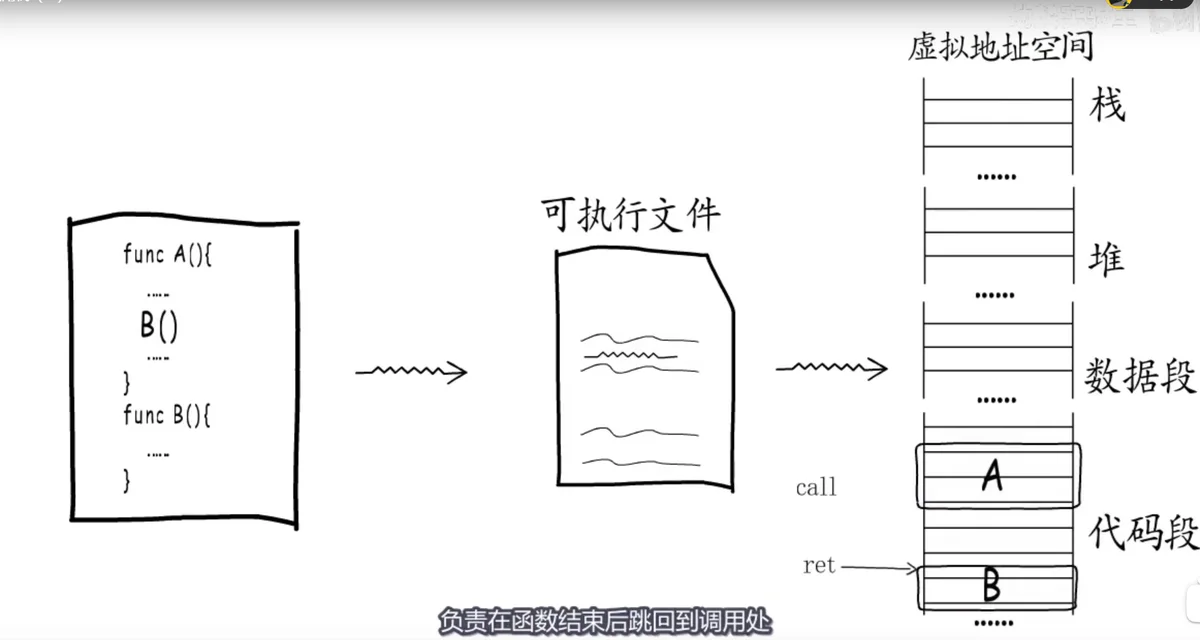
如果在一个函数中调用另一个函数,编译器就会对应生成一条call指令,程序执行到这条指令时,就会跳转到被调用函数入口处开始执行,而每个函数的最后都有一条ret指令,负责在函数结束后跳回到调用处,继续执行。
2.理论知识
2.1函数调用栈结构
函数调用栈是指程序运行时内存一段连续的区域,用来保存函数运行时的状态信息,包括局部变量等。称之为“栈”是因为发生函数调用时,调用函数(caller)的状态被保存在栈内,被调用函数(callee)的状态被压入调用栈的栈顶;在函数调用结束时,栈顶的函数(callee)状态被弹出,栈顶恢复到调用函数(caller)的状态;
函数调用栈在内存中从高地址向低地址生长,所以栈顶对应的内存地址在压栈时变小,退栈时变大;
函数状态主要涉及三个寄存器--esp,ebp,eip
1.esp 用来存储函数调用栈的栈顶地址,在压栈和退栈时发生变化
2.ebp 用来存储当前函数状态的基地址,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置
3.eip 用来存储即将执行的程序指令的地址,cpu 依照 eip 的存储内容读取指令并执行,eip 随之指向相邻的下一条指令,如此反复,程序就得以连续执行指令
2.2函数调用栈状态变化
参数按照逆序局部变量3.函数栈帧
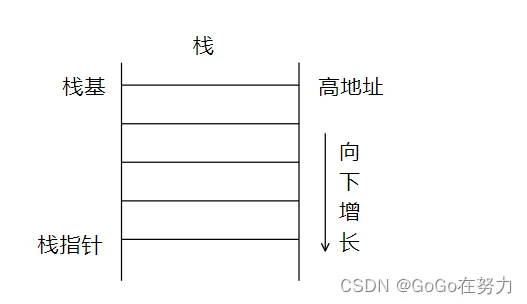
函数执行时需要有足够的内存空间,供它存放局部变量,返回值,参数等数据,这段空间对应到虚拟地址空间的栈。栈,只有一个口可供进出,先入栈的在底,后入栈的在顶,最后入栈的最早被取出。运行时栈,上面是高地址,向下增长,栈底通常被称为“栈基(bp)”,栈顶被称为“栈指针(sp)”。
分配给函数的栈空间被称为“函数栈帧(stack frame)”,先是调用者栈基地址,然后是函数的局部变量,最后是被调用函数的返回值和参数。
BP of callee和SP of callee会标识“被调用函数callee执行时栈基寄存器和栈指针寄存器指向的位置”,但是注意“BP of caller”不一定会存在,有些情况下可能会被优化掉,也有可能是平台不支持。我们只关注局部变量和参数、返回值的相对位置就好。
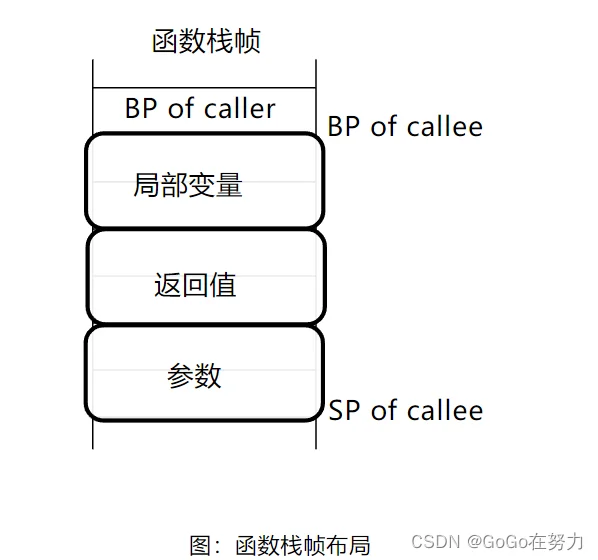
举个例子,函数A调用函数B,函数A有两个局部变量,函数B有两个参数和两个返回值。
func A() {
var a1, a2, r1, r2 int64
a1, a2 = 1, 2
r1, r2 = B(a1, a2)
r1 = C(a1)
println(r1, r2)
}
func B(p1, p2 int64) (int64, int64) {
return p2, p1
}
func C(p1 int64) int64 {
return p1
}
函数A的栈帧布局如下图所示,局部变量之后的空间用于存放被调用函数的返回值和参数,接下来要调用函数B,所以先有两个int64类型的变量空间用作B的返回值,再有两个int64类型的变量空间用于存放传递给B的参数。
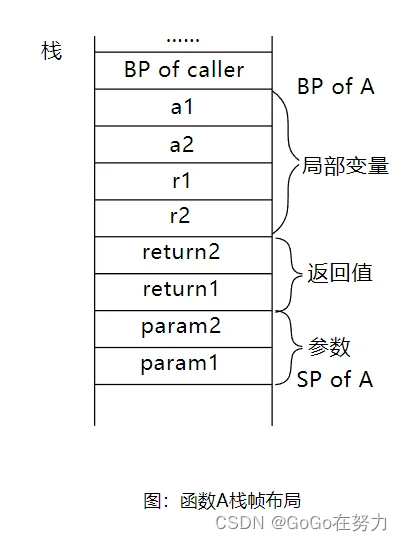
注意观察参数的顺序,先入栈第二个参数,再入栈第一个参数,返回值也是一样,上面是第二个返回值的空间,然后才是第一个返回值的空间。
其实这也好解释,因为这些是被调用函数的返回值和参数,被调用函数是通过栈指针加上偏移值这样相对寻址的方式来定位到自己的参数和返回值的,这样由下至上正好先找到第一个参数,再找到第二个参数。所以参数和返回值采用由右至左的入栈顺序比较合适。
“通常,我们认为返回值是通过寄存器传递的,但是Go语言支持多返回值,所以在栈上分配返回值空间更合适~”
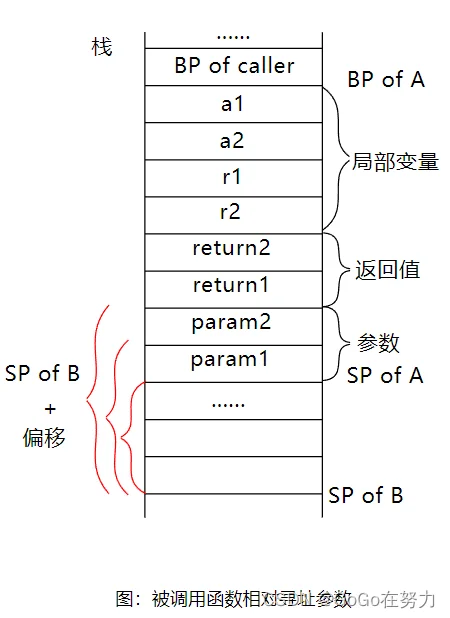
我们知道对函数B的调用会被编译器编译为call指令。实际上call指令只做两件事:
第一:将下一条指令的地址入栈,被调用函数执行结束后会跳回到这个地址继续执行,这就是函数调用的“返回地址”。
第二:跳转到被调用的函数B指令入口处执行,所以在“返回地址”下面就是函数B的栈帧了。
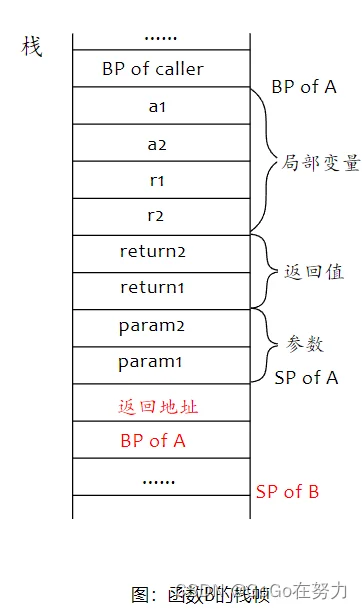
所有函数的栈帧布局都遵循统一的约定,函数B结束后它的栈帧被释放,回到函数A中继续执行。
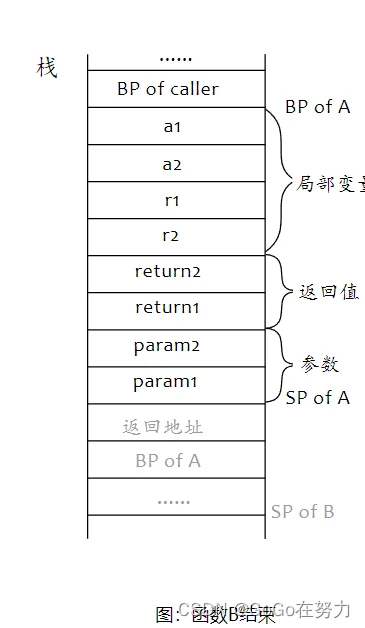
到了调用函数C的时候,它只有一个参数和一个返回值,它们会占用函数A栈帧中最下面的一部分空间,所以上面会空出来一块,这是为了在被调用函数中可以用标准的相对地址定位到自己的参数和返回值,而无需顾虑其它。
同样的,call指令会压入返回地址,并跳转到函数C的指令入口处,所以下面就是函数C的栈帧了。
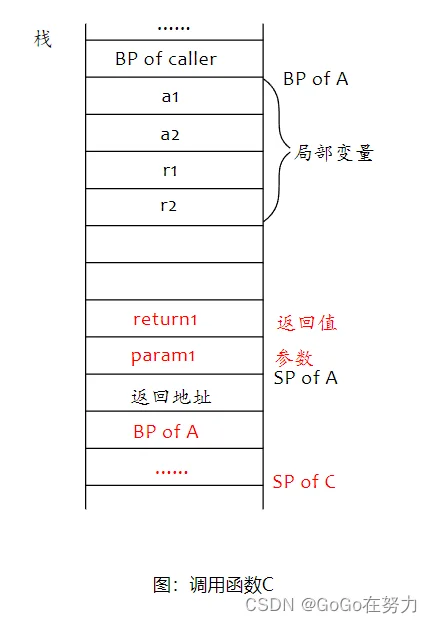
Go语言中,函数栈帧是一次性分配的,也就是在函数开始执行的时候分配足够大的栈帧空间。就像上例中函数A一样,它要调用两个函数,除了调用者栈基地址、局部变量以外,再有四个int64的空间用作被调用函数的参数与返回值就足够了。
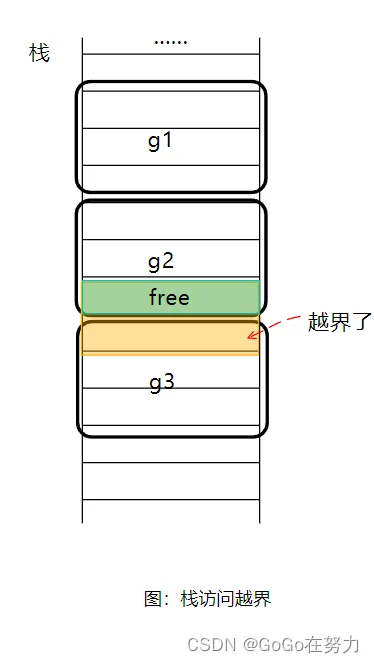
一次性分配函数栈帧的主要原因是避免栈访问越界,如下图所示,三个goroutine初始分配的栈空间是一样的,如果g2剩余的栈空间不够执行接下来的函数,若函数栈帧是逐步扩张的,那么执行期间就可能发生栈访问越界。
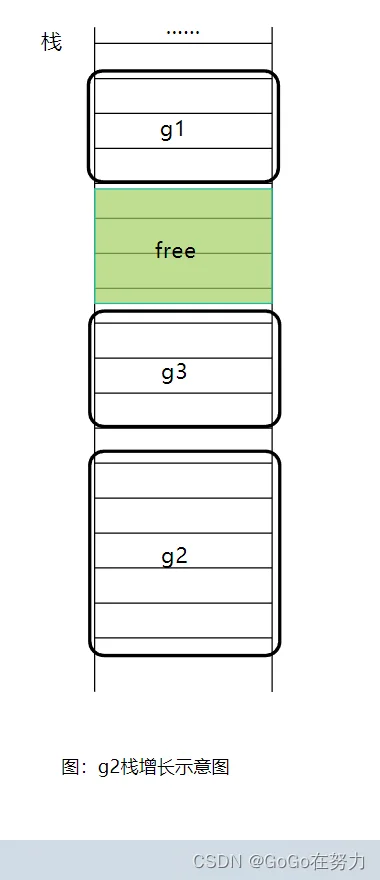
其实,对于栈消耗较大的函数,go语言的编译器还会在函数头部插入检测代码,如果发现需要进行“栈增长”,就会另外分配一段足够大的栈空间,并把原来栈上的数据拷过来,原来的这段栈空间就被释放了。
了解了函数栈帧布局,接下来,我们看几个关于参数和返回值常见的问题。
4.传参
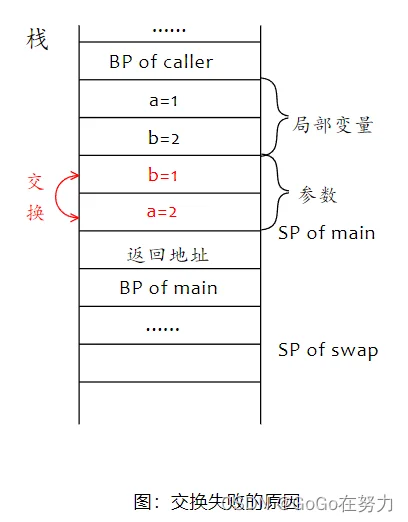
下面有一个swap函数,接收两个整型参数,main函数想要通过swap来交换两个局部变量的值,但是失败了…
func swap(a,b int) {
a,b = b,a
}
func main() {
a,b := 1,2
swap(a,b)
println(a,b) //1,2
}
我们通过函数调用栈,看看失败的原因到底在哪儿?
main函数栈帧中,先分配局部变量存储空间,a=1,b=2。因为例子中调用的函数没有返回值,所以局部变量后面就是给被调用函数传入的参数。需要传入两个整型参数,Go语言中传参都是值拷贝,参数是整型,所以拷贝整型变量值。注意参数入栈顺序:由右至左。先入栈第二个参数,再入栈第一个参数。
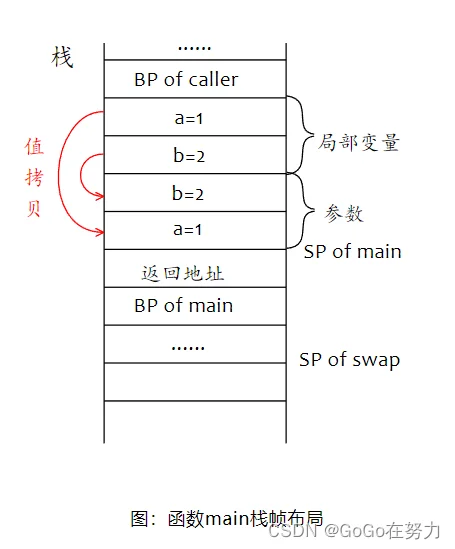
调用者栈帧后面是call指令存入的返回地址,swap开始执行,再下面分配的就是swap函数栈帧了。
swap函数要交换两个参数的值,但是注意,swap的参数在哪里?main的局部变量a和b又在哪里?找到它们,交换失败的原因就找到了,想要交换的局部变量a和b在局部变量空间,但实际上交换的是参数空间的a和b。
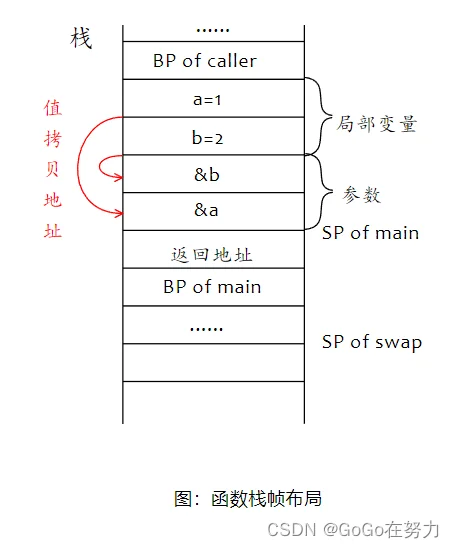
再来个例子,依然要交换两个整型变量的值,但是参数类型改为整型指针。这次交换成功了,同样通过函数调用栈,看看和上次有什么不同。
func swap(a,b *int) {
*a,*b = *b,*a
}
func main() {
a,b := 1,2
swap(&a,&b)
println(a,b) //2,1
}
main函数栈帧中,先分配局部变量,然后分配参数空间,参数是指针,传参都是值拷贝,这里拷贝的是a和b的地址。依然由右至左,先入栈b的地址, 再入栈a的地址。再后面是返回地址,以及swap函数栈帧。
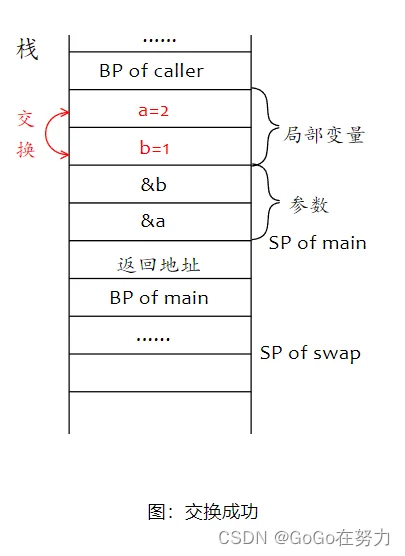
swap要交换的是这两个参数指针指向的数据,也就是局部变量空间这里的a和b,所以这一次能够交换成功!
5.返回值
直接看例子,这里main函数调用incr函数,然后把返回值赋给局部变量b,下面来看看函数调用栈的情况。
func incr(a int) int {
var b int
defer func(){
a++
b++
}()
a++
b = a
return b
}
func main(){
var a,b int
b = incr(a)
println(a,b) //0,1
}
main函数栈帧,先是局部变量,a=0,b=0,然后是incr的返回值,初始化为类型零值,再然后是参数空间。到incr函数栈帧这里,保存调用者main的栈基地址后,初始化局部变量b。
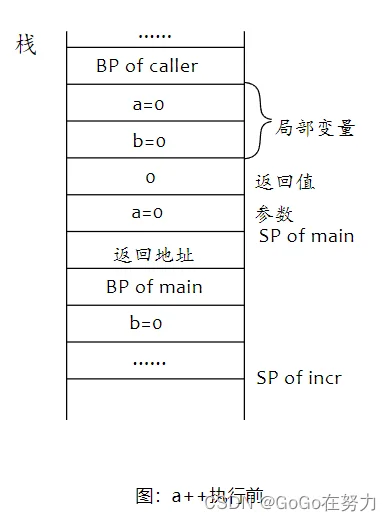
incr函数会把参数a自增一,然后赋值给局部变量b,要注意它们的位置。
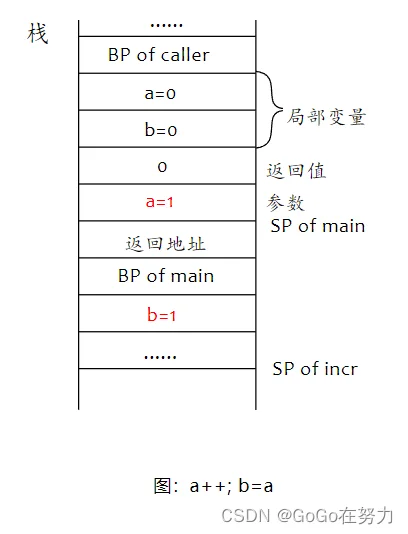
到incr函数的return这里,必须要明确一个关键问题。incr函数返回之前要给返回值赋值并执行defer函数,那谁先?谁后?
答案是:“先赋值”
所以incr函数返回前,会先把局部变量b的值拷贝到返回值空间,然后再执行注册的defer函数。
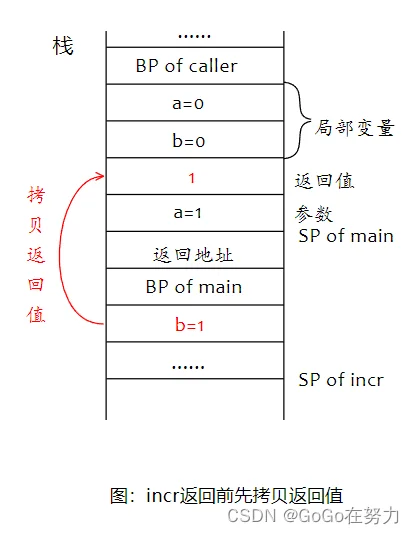
在defer函数里,a再次自增1,局部变量b也自增1。
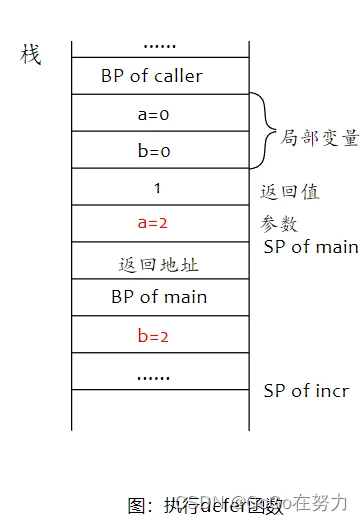
所以,incr结束后,返回值为1,赋给main函数局部变量b,最后会输出0和1。
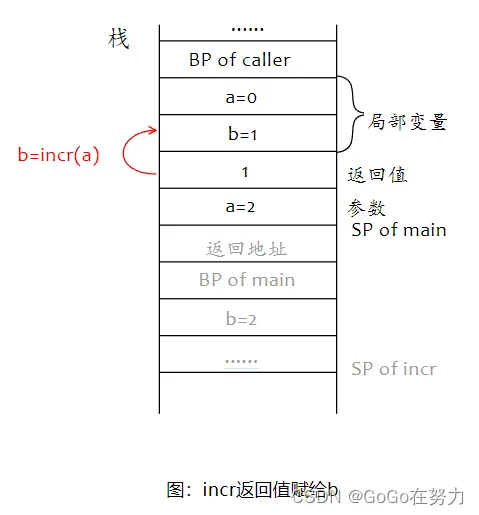
这是匿名返回值的情况,下面再来个例子,其它都不变,只把这里的局部变量b改成命名返回值,看看有什么不同。
func incr(a int) (b int) {
defer func(){
a++
b++
}()
a++
return a
}
func main(){
var a,b int
b = incr(a)
println(a,b) //0,2
}
main函数栈帧,与上个例子完全相同,到incr函数栈帧这里,没有局部变量,执行到a++时,参数a自增1。返回前,先把参数a赋给返回值b,要注意返回值的位置。
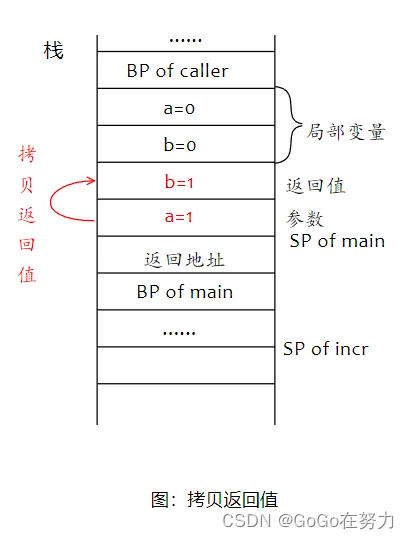
然后执行defer函数,参数a再次自增1,返回值b也自增1,然后incr结束,返回值最终为2。
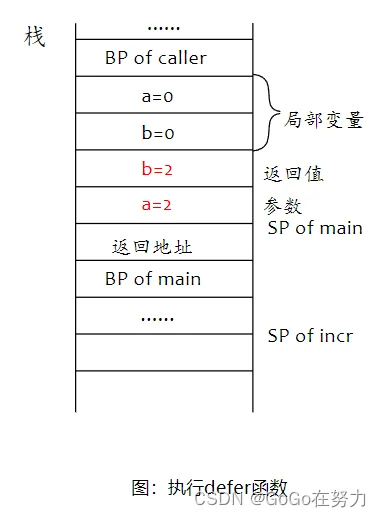
所以, main的局部变量b赋值为2,最后会输出0和2。
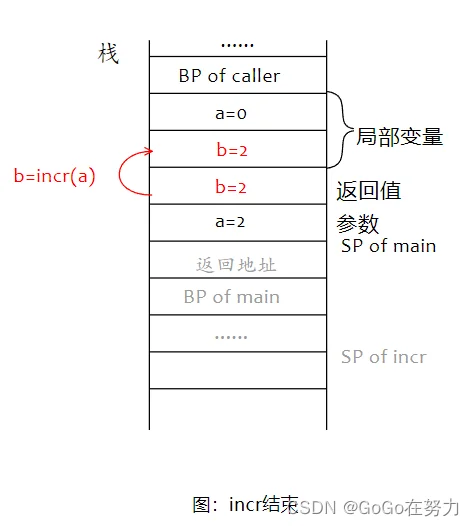
命名返回值和匿名返回值相关的问题,最关键的还是函数栈帧布局,以及返回值被赋值的时机。
最后,留给感兴趣的同学看看,在汇编指令层面怎么实现函数跳转与返回。
6.函数跳转与返回
程序执行时 CPU用特定寄存器来存储运行时栈基与栈指针,同时也有指令指针寄存器用于存储下一条要执行的指令地址。
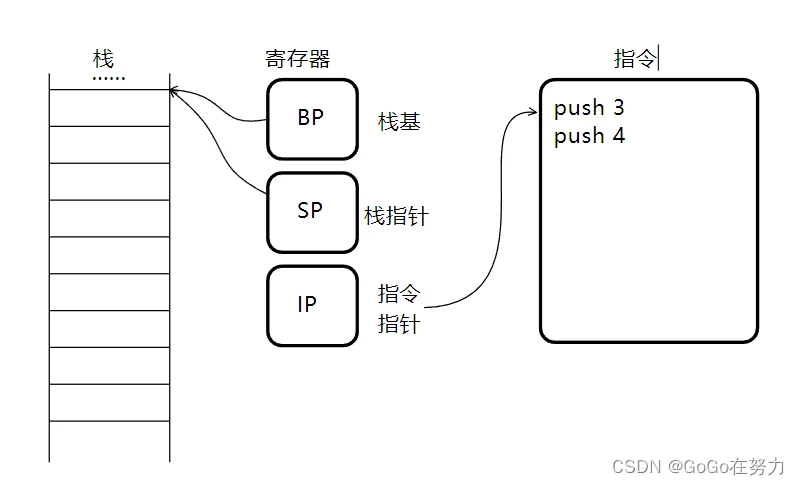
如果接下来要执行"push 3"这条指令,CPU读取后,会将指令指针移向下一条指令,然后栈指针向下移动,数字3入栈。
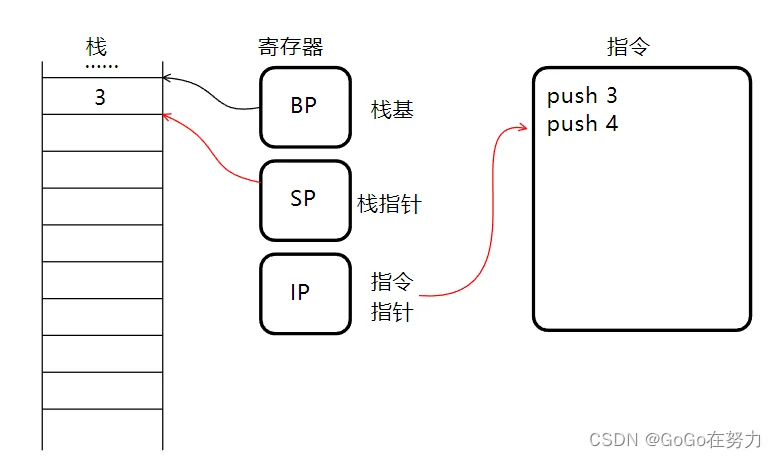
继续执行下一条指令,再次移动栈指针入栈数字4。
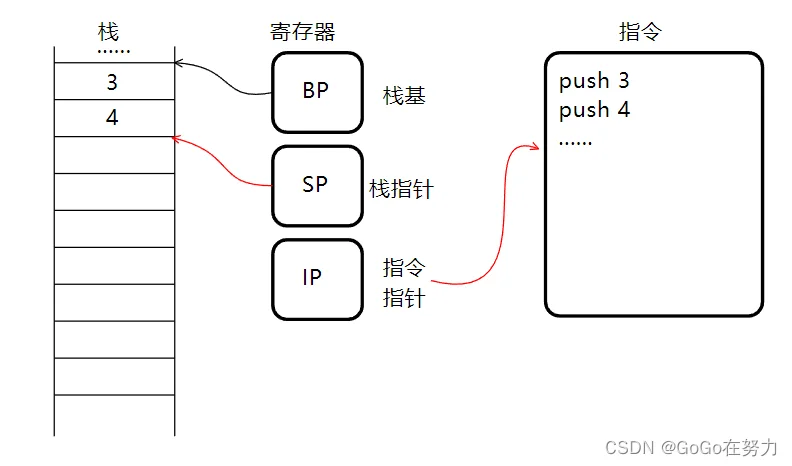
前面我们提过Go语言中函数栈帧不是这样逐步扩张的,而是一次性分配,也就是在分配栈帧时,直接将栈指针移动到所需最大栈空间的位置。
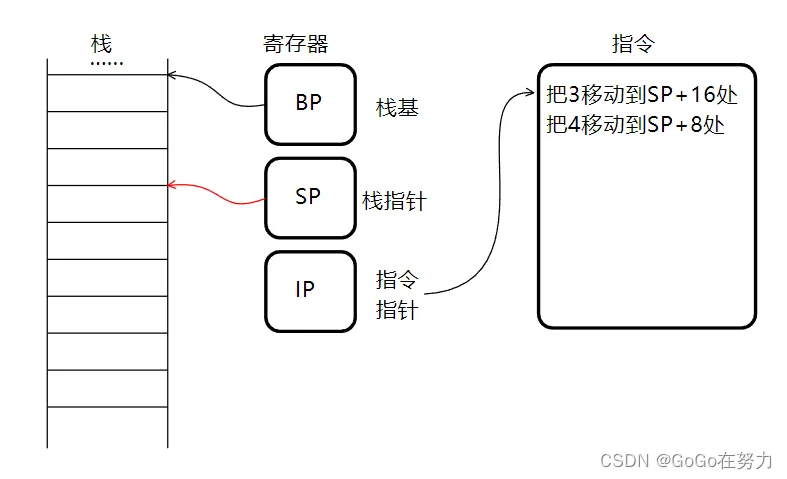
然后通过栈指针加上偏移值这种相对寻址方式使用函数栈帧。例如sp加16字节处存储3,加8字节处存储4,诸如此类。
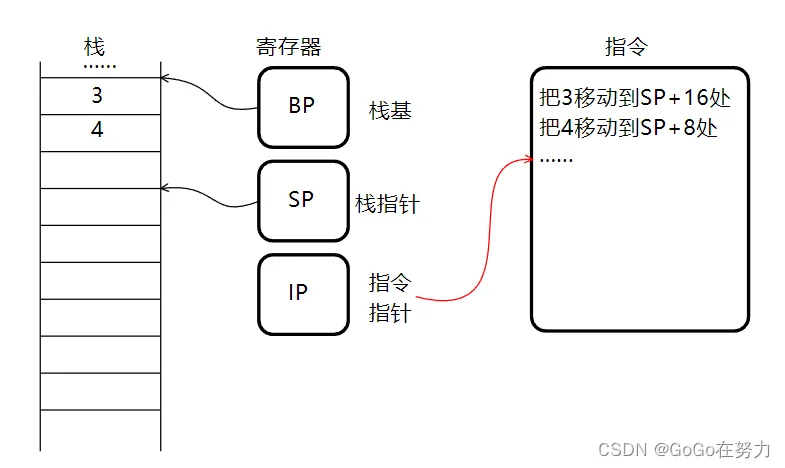
接下来我们看看call指令和ret指令,是怎样实现函数跳转与返回的。
func A(){
a,b := 1,2
B(a,b)
return
}
func B(c,d int){
println(c,d)
return
}
调用函数B之前函数A栈帧如下图所示,注意函数A和函数B的指令分布在代码段,而且函数A调用函数B的call指令在地址a1处,函数B入口地址在b1处。
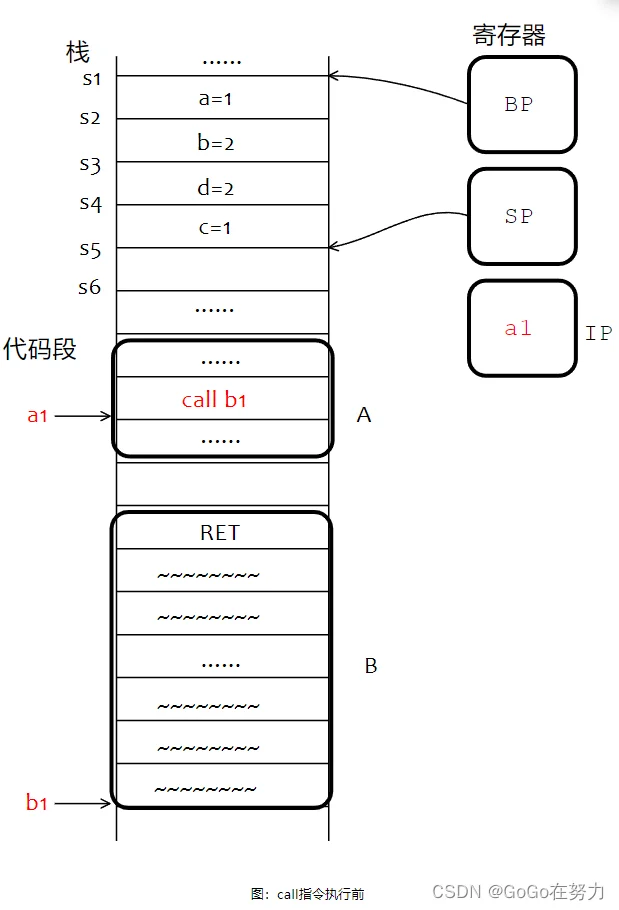
然后到call指令这里,它的作用有两点:
第一,把返回地址a2入栈保存起来;
第二,跳转到指令地址b1处。
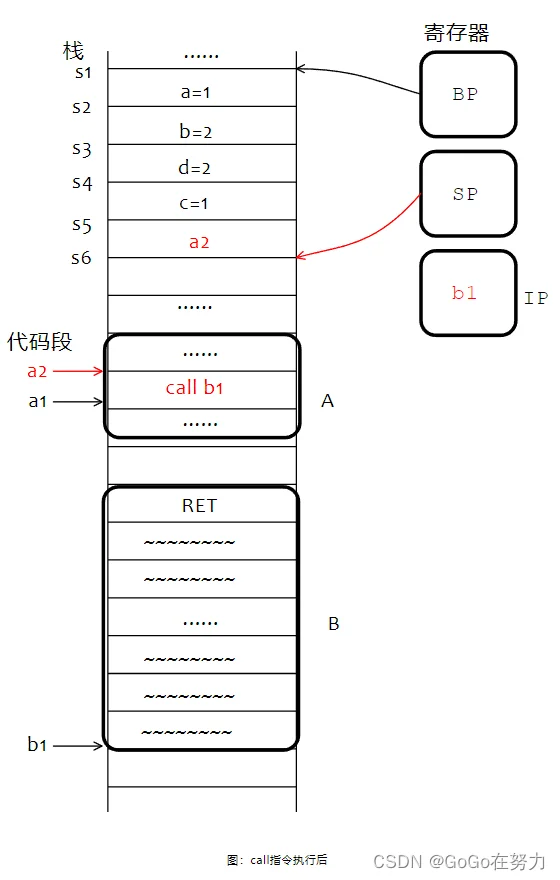
call指令结束。函数B开始执行,我们先看它最开始的三条指令:
第一条指令,把SP向下移动24字节(从s6挪到s9),为自己分配足够大的栈帧;
第二条指令,要把调用者栈基s1存到SP+16字节的地方(s7那里);
第三条指令,把s7(SP+16)存入BP寄存器。
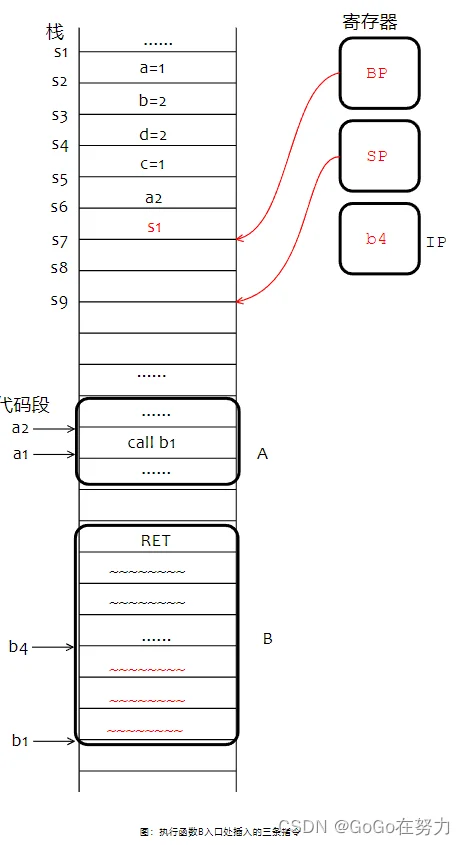
接下来就是执行函数B剩下的指令了,没有局部变量,只有被调用者的参数空间。在最后的ret指令之前,编译器还会插入两条指令:
第1条指令:恢复调用者A的栈基地址,它之前被存储在SP+16字节(s7)这里,所以BP恢复到s1;
第2条指令:释放自己的栈帧空间,分配时向下移动多少(从s6到s9)释放时就向上移动多少(从s9到s6)。
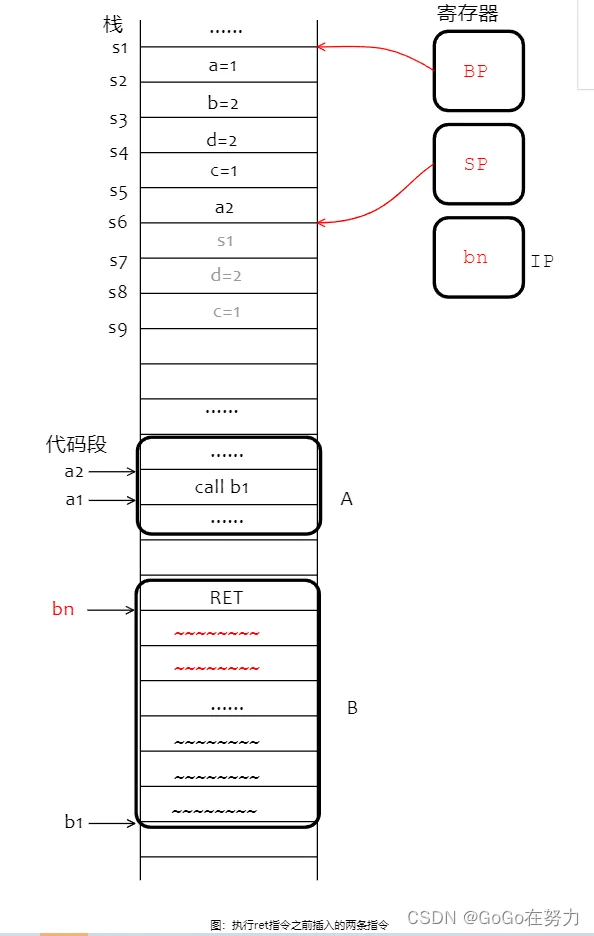
然后就到ret指令了,它的作用也有两点:
第一,弹出call指令压栈的返回地址a2;
第二,跳转到call指令压栈的返回地址a2处。
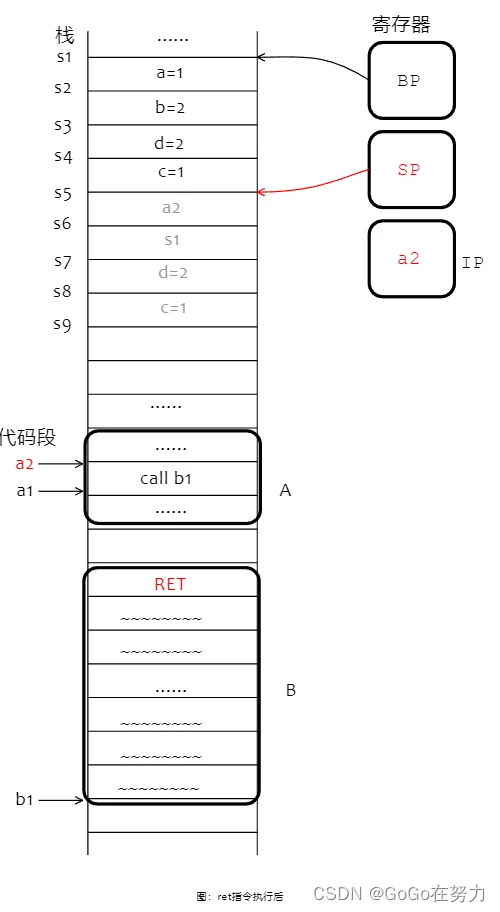
现在可以从a2这里继续执行了。简单来说,函数通过call指令实现跳转,而每个函数开始时会分配栈帧,结束前又释放自己的栈帧,ret指令又会把栈恢复到call之前的样子,通过这些指令的配合最终实现了函数跳转与返回。