
在这个示例对应的实际任务中,不是要统计字符的数量,而是要处理 http 的访问日志,按|分隔的状态码,路径,域名,错误码等等。
很多同学给我提算法方面的建议,那样会导致代码抽象层级比较低,修改起来会比较难。所以我倾向于找到一种不那么牺牲抽象层级,同时又比较快速的写法。
-----------------------------------------------------
任务设定:
对于一个简单的大文件,读取该文件并对内容按行分隔,对行内内容按 `|` 分隔,统计所遇到的所有字符数。
测试环境,就是我的笔记本:
型号名称: MacBook Air
型号标识符: MacBookAir5,2
处理器名称: Intel Core i5
处理器速度: 1.8 GHz
处理器数目: 1
核总数: 2
L2 缓存(每个核): 256 KB
L3 缓存: 3 MB
内存: 4 GB
首先,用 ruby 生成一个简单的大文件,1000w行数据,
文件信息如下:
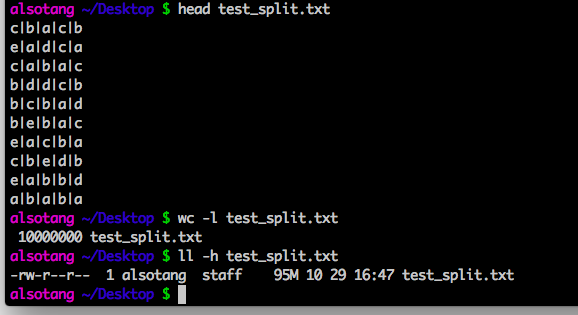
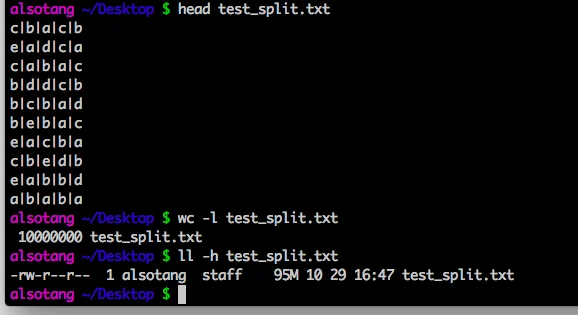
首先,先进行 node.js 的测试:
第一个 node.js 脚本,是直接读取整个文件,然后进行内容处理:
处理的时间在 11.6s 左右。
第二个 node.js 脚本,通过流的方式按行读取文件并处理每一行:
时间不差太多。后来我看了一下读取文件的时间,全量读取整个95M的文件,在我这里的时间是200ms以下。所以时间基本是花在cpu上而非io上。
第三个node.js脚本,使用 for 循环代替 foreach:
9.4s 这样,相比第一个脚本快了有2s。
然后是 golang 的测试,
第一个同样是全量读取文件:
11s 的话,看起来跟 node.js 没差太多啊。。我本身还以为编译型语言会快很多。
golang 在编译的时候,都是直接 go build filename 这样的,貌似也没有编译优化的选项。
第二个是按行读取的:
8.2s,不知为何会比第一个快。。。
然后到 python 的,python 只写了一个脚本,是按行读取,只是分别用了 cpython 和 pypy 来运行:
以上是 cpython 的结果,可以看到跟 node.js 的结果已经拉开很多了,差距有 20s。
而 pypy 的结果,跑了多次都显示是:
只需要5.6s,把golang和node.js都甩开了。。原因不明。。。