
2. 性能评估和分析
在上一节中,我们研究了对单个函数进行基准测试,这个的使用场景是在你已经提前知道瓶颈在哪里时很有用。
但是,通常你会发现你并不知道性能瓶颈在哪里,你经常会问:
程序为什么耗时这么久?
对于上面的问题,我们需要对整个程序进行概要分析以找出程序的瓶颈在哪里。本节,我们讲使用Go的内置性能分析工具pprof从内部查看程序的整体运行情况。
2.1 pprof
今天我们要讨论的第一个工具是 pprof. pprof诞生自Google Perf Tools工具套件,并且已经集成到Go运行时环境中。
pprof由两部分组成:
- runtime/pprof 运行时包。
- go tool pprof工具。用于分析性能。
2.2 性能类型
pprof支持以下类型的性能分析:
- CPU性能分析
- 内存性能分析
- 阻塞性能分析
- 互斥&竞争分析
2.2.1 CPU性能分析 (CPU profiling)
CPU性能分析是最常用、最明确的性能分析。 当CPU性能分析启用的时候,运行时环境会每10毫秒中断一次并记录下当前运行协程的堆栈跟踪信息。
一旦性能分析完成,我们就可以分析并找出执行耗时最长的代码路径。一个函数在性能分析中出现的次数越多,则其所在的代码路径花费的时间就越长。
2.2.2 内存性能分析(Memory profiling)
内存性能分析记录了堆内存分配的调用栈信息。栈内存分配的耗时可以忽略不计,所以不计入到内存性能分析中。
和CPU数据采集类似,内存数据采集默认是每分配1000次则采样一次。 由于内存数据采集是基于采样的,并且由于它跟踪的是未使用的分配,因此该技术很难确定应用程序的整体内存使用情况。
个人观点:我并没有发现内存分析对找到内存峰值有用。稍后我们将介绍一些较好的方式用来查看到应用程序整体使用内存情况。
2.2.3阻塞性能分析(Blocking profiling)
阻塞分析是Go中独有的。 一个阻塞分析类似于CPU的性能分析,但是它记录的是一个协程花在等待共享资源上的时间。
这对于分析并发瓶颈非常有用。
阻塞分析可以显示出大量goroutine何时可以取得进展,但不阻止了。阻塞包括:
- 向一个非缓存的通道(unbuffered channel)上发送或接收数据
- 向一个已满的通道发送数据,或从一个空通道上接收数据
- 试图给一个互斥资源加锁,而该互斥资源已经被另一个协程占用。
阻塞分析是一个非常特殊的工具,你应该首先解决你的CPU、内存瓶颈之后,再来分析阻塞性能。
2.2.4 互斥性能分析
互斥分析类似于阻塞分析,但是它主要关注在导致互斥锁征用导致延迟的操作上。
互斥分析不能提供给你该程序将要运行多长时间,以及已经运行了多长时间。相反,它能够记录该程序在等待互斥锁上花费了多长时间。就像阻塞分析,它指出的是在等待资源上花费了多长时间。
换句话说,就是如果互斥竞争被移除,那么会节省多少时间。
2.3 一次只做一类性能分析
性能分析并不是没有成本的。
性能分析对程序是有一定的影响的,尤其是当你增加了内存分析采样频率的时候。
大多数工具不会阻止你一次启用多个性能分析。
注意:不要一次启用多个类型的性能分析 如果你一次启用多个类型的性能分析,每个类型的只会关注自己的交互并且会丢掉其他的结果。
2.4 采集性能概况数据
Go语言的运行时性能采集接口在runtime/pprof包下。runtime/pprof是比较低层的工具,并且由于历史原因,不同类型的性能概况收集接口也不统一。
正如我们上面看到的,pprof概况收集是testing包中内置的,但有时将你要分析的代码放在test.B基准测试环境中会带来不变或困难,并且必须直接使用runtime/pprof的API。
几年前,我写了一个小工具,来使它变得更容易一些.
在上面这段代码中,我们使用了profile包。稍后我们将直接使用runtime/pprof接口。
2.5 利用pprof分析一个测量文件
到目前为止,我们已经讨论了pprof功能能够评估什么,并且如何产生一个评估概要文件,接下来让我们讨论使用pprof工具如何分析一个评估概要文件。
通过以下命令分析概要评估文件的内容:
该工具提供了分析数据的几种不同形式:文本、图表以及火焰图。
如果你已经用过Go一段时间了,你可能已经被告知说pprof会使用两个参数。从Go 1.9开始,概要文件包含了概要分析所有的信息。你不再需要单独生成概要分析文件了。
2.5.1 进一步阅读
2.5.2 CPU性能分析(练习)
让我写一段统计单词的代码:
让我们看看在moby.txt文件中有多少个单词:
和unix的 wc -w命令比较一下:
由此可知,统计的单词数量不一样。wc工具多出了19%,因为它对于一个单词的识别规则和我的程序是不一样的。这不重要--两个程序都将整个文件作为输入,并在一次过程中计算从单词到非单词的转换次数。
让我们研究一下为什么使用pprof工具的程序运行时间会有不同。
2.5.3 添加CPU测量分析
首先,编辑main.go文件并打开profiling
现在当我们运行该程序的时候,一个cpu.pprof文件被创建。
现在,我们得到了cpu.pprof文件,并且可以用go tool pprof命令进行分析
top 命令是最常用的一个命令。从上面的结果得知,99%的时间化在了*syscall.Syscall函数上,只有一小部分时间花在了main.readbyte函数上。
我们还可以使用 web 命令对结果可视化。这会将profile中的数据直接图形化。
然而,在Go1.10及其以后的版本中,Go在本机上自带了支持http服务器的pprof版本。
该命令将打开一个web浏览器:
- 图形化模式
- 火焰图模式
在图像化模式下,最大的那个盒子花费的cpu时间越多 --- 我们看到 syscall.SysCall的花费时间占了整个程序的99.3%。盒子上指向syscall.Syscall的字符串代表直接调用者---如果多个代码路径都覆盖同一个函数,则可以有多个。箭头的大小代表在一个盒子的子容器中花费了多少时间,我们看到main.readbyte所花费的时间接近0秒。
问题:为什么我们的程序比wc命令这么慢吗?
2.5.4 改进我们的程序
我们程序慢的原因不是因为Go的syscall.Syscall慢。那是因为系统调用通常是昂贵的操作。
每次对readbyte的调用都会导致一次缓冲区大小为1的syscall.Read操作。所以我们的程序执行syscall的数量等于输入的大小。在pprof图中我们可以看到,读取输入的内容占了主导地位。
通过在输入文件和readbyte之间插入一个bufio.Reader, 然后将该版本的花费时间和wc相比。他们是不是非常的接近了?
2.5.5 内存测量
新的 words分析中表明readbyte函数内部正在分配某些内容。我们可使用pprof进行研究:
然后运行该程序:
图片一:
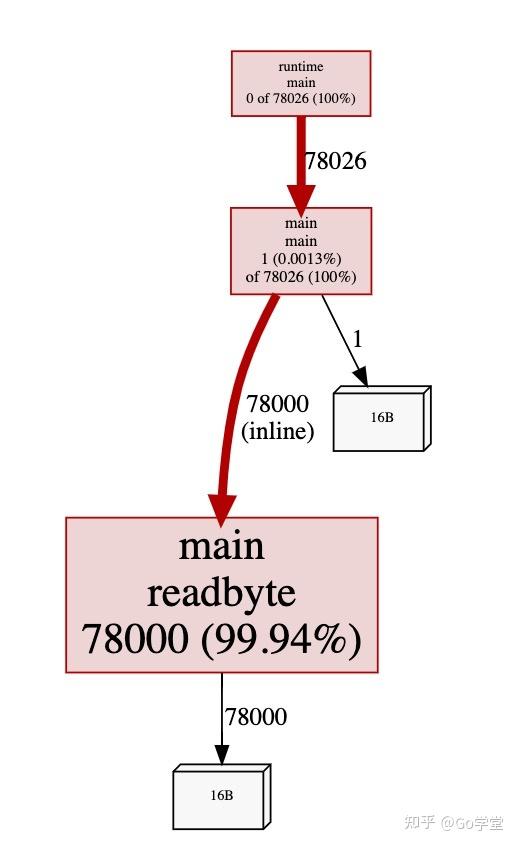
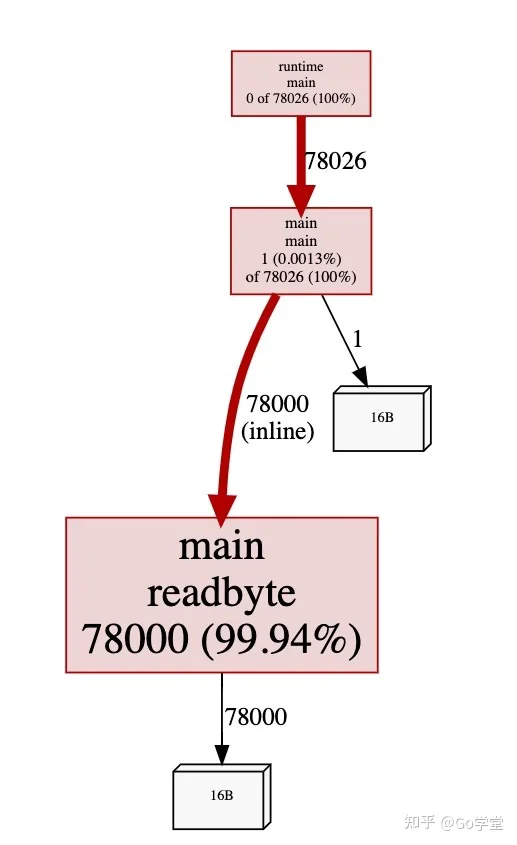
正如我们怀疑的是内存分配是从readbyte分配的-readbyte函数并不是那么复杂,只有三行:
使用pprof确定内存分配来自哪里。
注:内存分配来自于 var buf [1]byte这一行代码。
我们会在下一节更详细的讨论在此发生内存分配的原因,但我们现在看到的是每次调用readbyte函数,都会在堆上分配一个1字节的数组。
有哪些方法可以避免这样分配?试一试并通过用cpu和内存分析法来证明它。
2.5.6 分配对象 VS 重用对象
内存分析中有两个变体,在go tool pprof标志中通过参数命名可以体现。
- -alloc_objects 报告在哪些地方分配了内存
- -inuse_objects 当内存数据收集结束后,报告哪些地方还在使用内存
为了说明这一点,这是一个人为设计的程序,它将以受控方式分配一堆内存。
该程序是profile包的注释,我们将内存监控的速率设置为1,即记录每次分配的堆栈跟踪。 这会大大减慢该程序的速度,但是您很快就会知道原因。
让我们看下分配对象的图表,这是默认的,显示了在内存监控期间导致每个对象内存分配的调用过程。
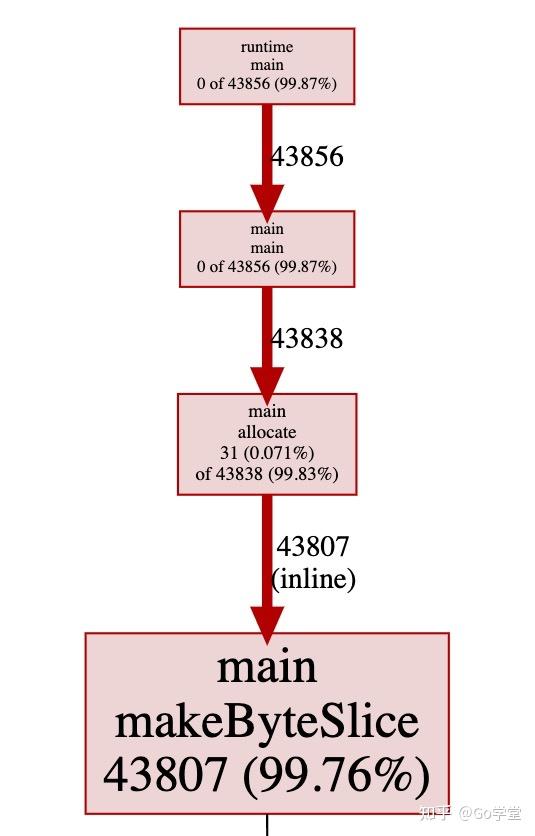
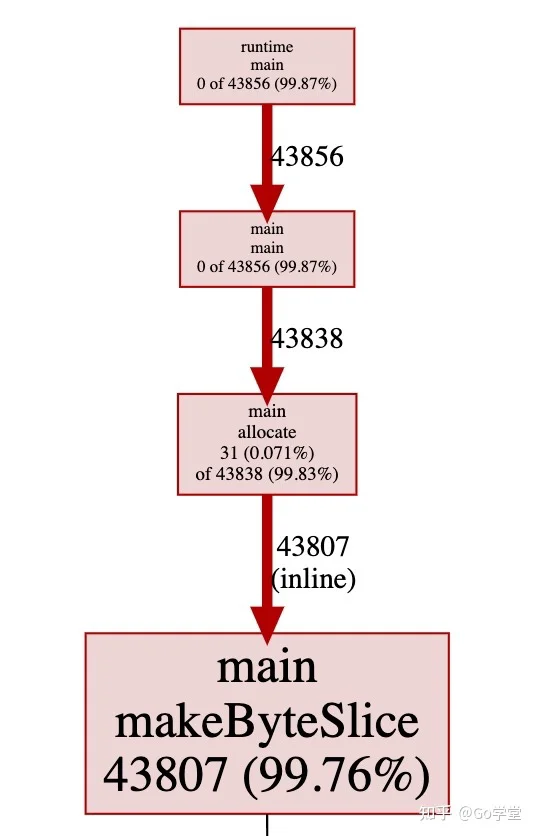
不用惊讶,超过99%的内存是在 makeByteSlice函数中分配的。接下来让我们使用-inuse_objects参数来看一下:
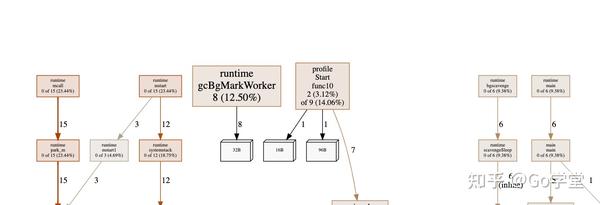
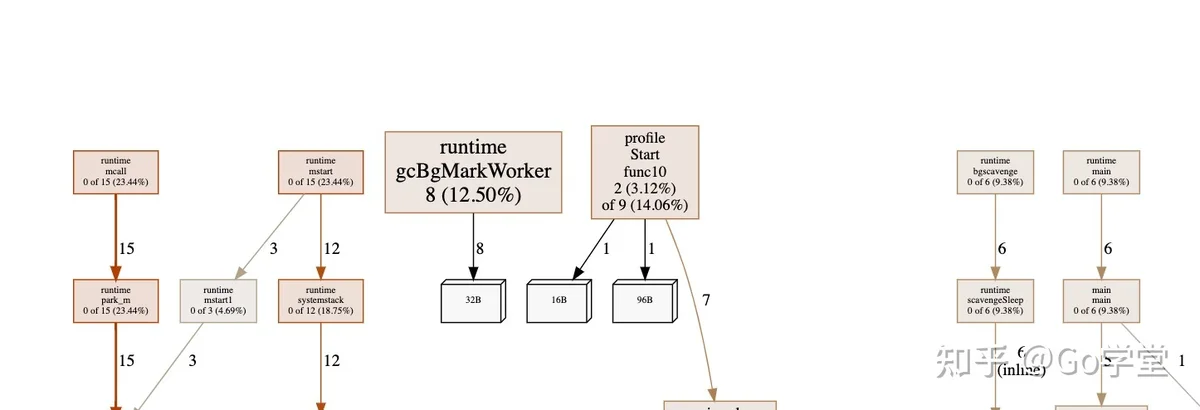
我们看到的不是在内存监控期间分配的对象,而是在获取监控时仍在使用的对象-这将忽略已由垃圾收集器回收的对象的堆栈跟踪。
2.5.7 阻塞测量
最后一个监控类型是阻塞监控。我们将使用net/http包下的 ClientServer的基准测试:
2.5.8 互斥测量
互斥争用随着goroutine的数量而增加。
按如下命令运行: