
为什么需要反射?
首先要明白反射能有什么好处,如果它不能带来任何好处,那么实际上我们不用它也就不需要担心性能带来的影响。
reflect反射判断结构体是否为空
业务场景:通过这个方式可以在传入的结构体为空直接进行返回,而不对SQL 拼接,从而避免了全表扫描有慢SQL
如果不使用反射,那么当需要判断一个结构体是否为空时则需要一个字段一个字段进行判断,实现如下:
type aStruct struct {
Name string
Male string
}
func (s *aStruct) IsEmpty() bool {
return s.Male == "" && s.Name == ""
}
type complexSt struct {
A aStruct
S []string
IntValue int
}
func (c *complexSt) IsEmpty() bool {
return c.A.IsEmpty() && len(c.S) == 0 && c.IntValue == 0
}
这时如果需要增加一个新结构体的判空,那么就需要实现对应的方法对每个字段进行判断
如果使用反射的方式进行实现可以参见 : Golang 空结构体判断
这个时候只需要传入对应的结构体就可以得到对应的数据是否为空,不需要重复进行实现。
性能对比
func BenchmarkReflectIsStructEmpty(b *testing.B) {
s := complexSt{
A: aStruct{},
S: make([]string, 0),
IntValue: 0,
}
for i := 0; i < b.N; i++ {
IsStructEmpty(s)
}
}
func BenchmarkNormalIsStructEmpty(b *testing.B) {
s := complexSt{
A: aStruct{},
S: make([]string, 0),
IntValue: 0,
}
for i := 0; i < b.N; i++ {
s.IsEmpty()
}
}
执行性能测试
# -benchmem 查看每次分配内存的次数
# -benchtime=3s 执行的时间指定为3s,一般1s、3s、5s得到的结果差不多的,如果性能较差,执行时间越长得到的性能平均值越准确
# -count=3 执行次数,多次执行能保证准确性
# -cpu n 指定cpu的核数,一般情况下CPU核数增加会提升性能,但也不是正相关的关系,因为核数多了之后上下文切换会带来影响,需要看是IO密集型还是CPU密集型的应用,多协程的测试中可以进行对比
go test -bench="." -benchmem -cpuprofile=cpu_profile.out -memprofile=mem_profile.out -benchtime=3s -count=3 .执行结果:
BenchmarkReflectIsStructEmpty-16 8126697 493 ns/op 112 B/op 7 allocs/op
BenchmarkReflectIsStructEmpty-16 6139268 540 ns/op 112 B/op 7 allocs/op
BenchmarkReflectIsStructEmpty-16 7222296 465 ns/op 112 B/op 7 allocs/op
BenchmarkNormalIsStructEmpty-16 1000000000 0.272 ns/op 0 B/op 0 allocs/op
BenchmarkNormalIsStructEmpty-16 1000000000 0.285 ns/op 0 B/op 0 allocs/op
BenchmarkNormalIsStructEmpty-16 1000000000 0.260 ns/op 0 B/op 0 allocs/op结果分析:
结果字段的含义:
| 结果项 | 含义 |
|---|---|
| BenchmarkReflectIsStructEmpty-16 | BenchmarkReflectIsStructEmpty 是测试的函数名 -16 表示GOMAXPROCS (线程数)的值为16 |
| 2899022 | 一共执行了2899022次 |
| 401 ns/op | 表示平均每次操作花费了401纳秒 |
| 112 B/op | 表示每次操作申请了112 Byte的内存 |
| 7 allocs/op | 表示申请了七次内存 |
反射判断每次操作的耗时大约是直接判断的1000倍,且带来了额外七次的内存分配,每次会增加112Byte,这样看下来性能比直接操作还是会下降不少的。
反射复制结构体同名字段
DTOVOnewtype aStruct struct {
Name string
Male string
}
type aStructCopy struct {
Name string
Male string
}
func newAStructCopyFromAStruct(a *aStruct) *aStructCopy {
return &aStructCopy{
Name: a.Name,
Male: a.Male,
}
}
使用反射来对结构体进行复制,在有需要复制的新结构体时我们只需要将结构体指针传入即可进行同名字段的复制,实现如下:
func CopyIntersectionStruct(src, dst interface{}) {
sElement := reflect.ValueOf(src).Elem()
dElement := reflect.ValueOf(dst).Elem()
for i := 0; i < dElement.NumField(); i++ {
dField := dElement.Type().Field(i)
sValue := sElement.FieldByName(dField.Name)
if !sValue.IsValid() {
continue
}
value := dElement.Field(i)
value.Set(sValue)
}
}
性能对比
Benchmark Test
func BenchmarkCopyIntersectionStruct(b *testing.B) {
a := &aStruct{
Name: "test",
Male: "test",
}
for i := 0; i < b.N; i++ {
var ac aStructCopy
CopyIntersectionStruct(a, &ac)
}
}
func BenchmarkNormalCopyIntersectionStruct(b *testing.B) {
a := &aStruct{
Name: "test",
Male: "test",
}
for i := 0; i < b.N; i++ {
newAStructCopyFromAStruct(a)
}
}
运行性能测试
go test -bench="." -benchmem -cpuprofile=cpu_profile.out -memprofile=mem_profile.out -benchtime=3s -count=3 .
运行结果:
BenchmarkCopyIntersectionStruct-16 10787202 352 ns/op 64 B/op 5 allocs/op
BenchmarkCopyIntersectionStruct-16 10886558 304 ns/op 64 B/op 5 allocs/op
BenchmarkCopyIntersectionStruct-16 10147404 322 ns/op 64 B/op 5 allocs/op
BenchmarkNormalCopyIntersectionStruct-16 1000000000 0.277 ns/op 0 B/op 0 allocs/op
BenchmarkNormalCopyIntersectionStruct-16 1000000000 0.270 ns/op 0 B/op 0 allocs/op
BenchmarkNormalCopyIntersectionStruct-16 1000000000 0.259 ns/op 0 B/op 0 allocs/op与上面第一个运行结果相差无几,反射的耗时仍然是不使用反射的1000倍,内存分配也在每次多增加了64Byte
在实际的业务场景中可能多次反射的组合使用,如果是需要对实际性能可以自行编写 BenchmarkTest 进行测试
火焰图对比可以更加明确的看出运行时间的占比
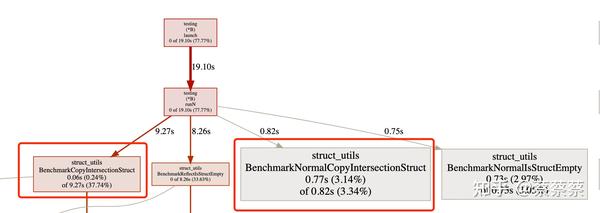
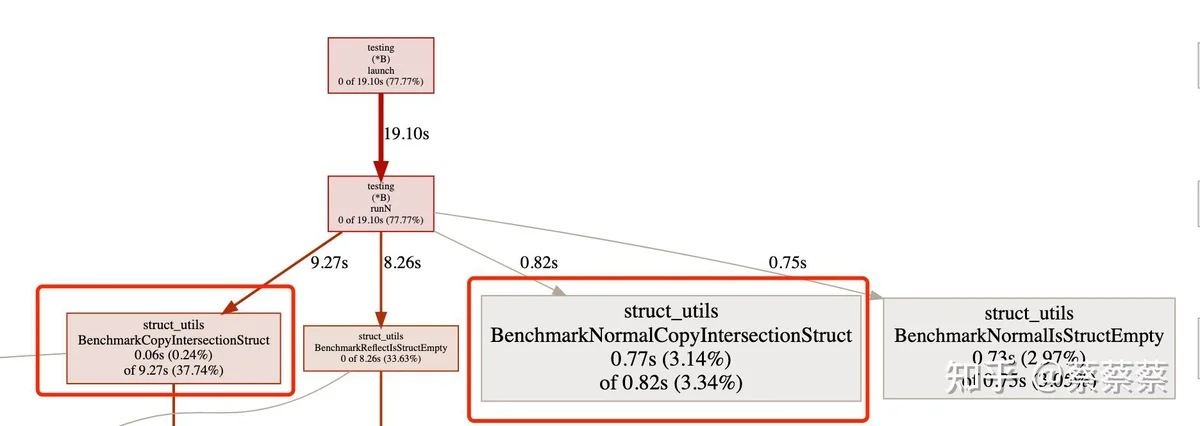
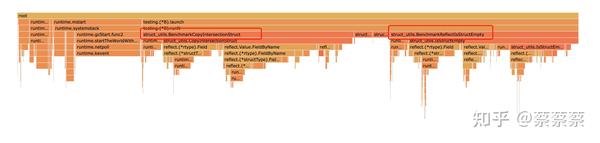
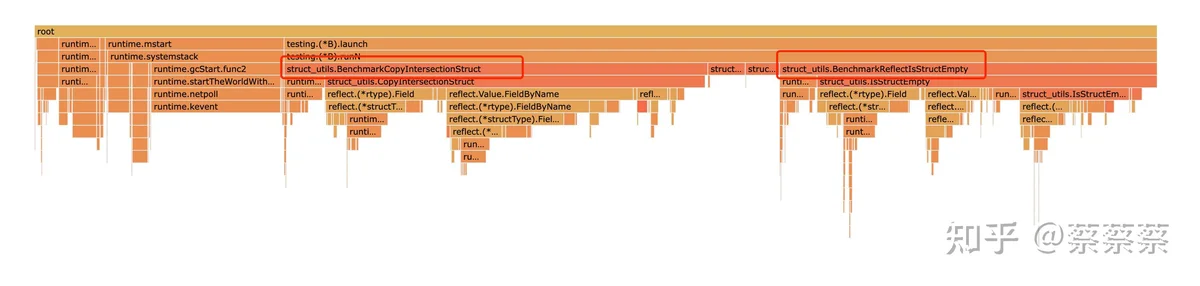
结论
业务接口中我们假设接口的相应是10ms,一个反射方法的操作平均是 400纳秒,会带来的额外内存分配大概是 64Byte~112Byte。
1ms【毫秒】 = 1000μs【微秒】=1000 * 1000ns【纳秒】
1MB = 1024KB = 1024 * 1024 B
如果一个接口在链路上做了1000次反射的操作,单次操作大约会增加0.4ms的接口延时,一般单次请求中经过的中间件和业务操作也很少会达到这个次数,所以这种响应时长的影响基本可以忽略不计。实际业务中更多的损耗则是会在内存的复制和网络IO上。
但是反射在编码上也存在实实在在的问题就是维护起来会比普通业务代码更加困难,理解上会更加费劲,所以在使用时需要进行斟酌,避免过度使用导致代码的复杂度不断提高