
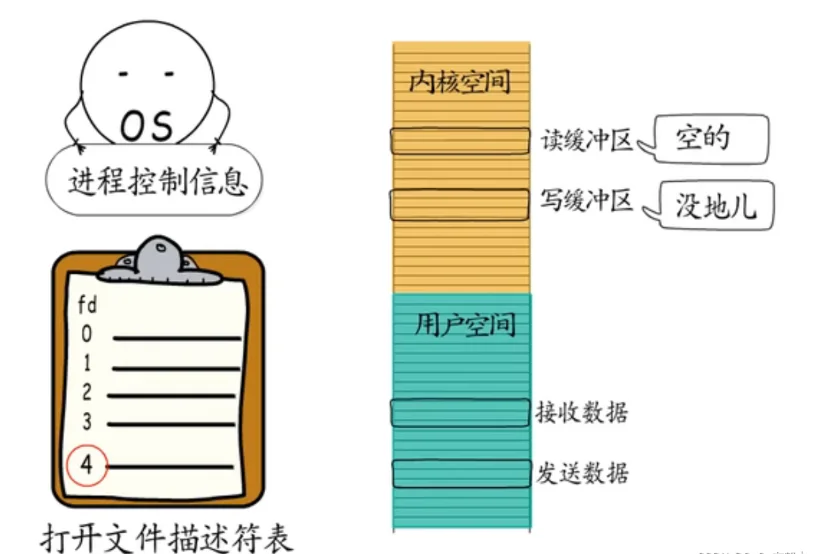
1. 想读时缓冲区没数据,想写时缓冲区没空间,遇到这样的socket,该如何是好?
我们知道通过操作系统记录的进程控制信息,可以找到"打开文件描述符表",进程打开的文件,创建的socket等等,都会记录到这张表里。
socket的所有操作都由操作系统来提供,也就是要通过系统调用来完成,每创建一个socket,就会在打开文件描述符表中,对应增加一条记录,而返回给应用程序的只有一个socket描述符,用于识别不同的socket。

而且每个TCP socket在创建时,操作系统都会为它分配一个读缓冲区和一个写缓冲区,要获得响应数据,就要从读缓冲区拷贝过来,
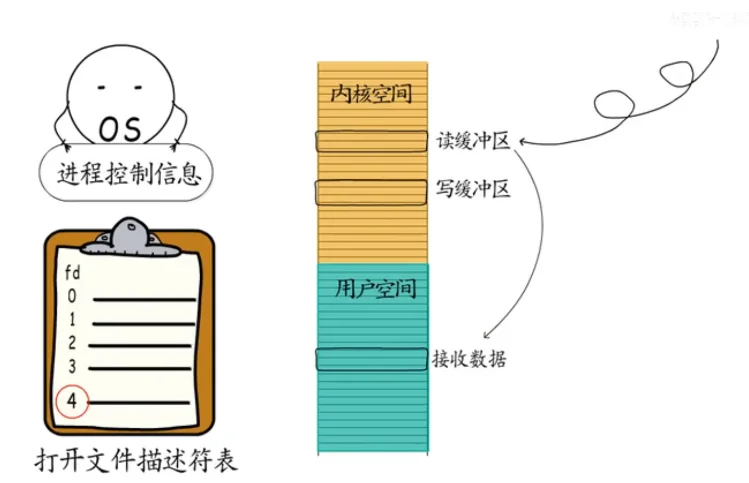
同样的要通过socket发送数据,也要先把数据拷贝到写缓冲区才行。
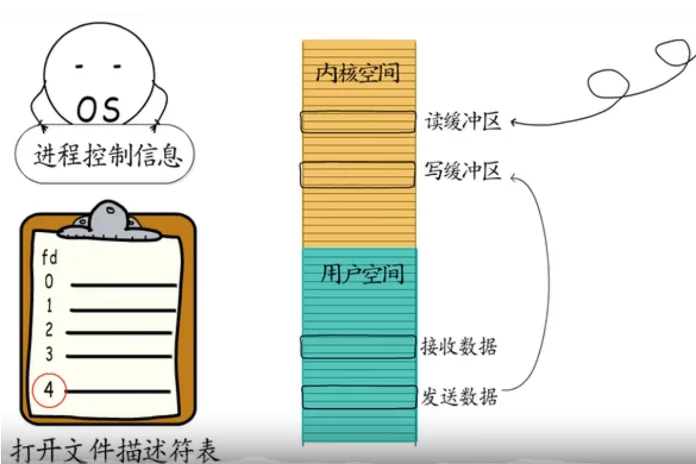
所以,问题出现了,用户程序想要读数据的时候,读缓冲区里未必有数据,想发送数据的时候,写缓冲区里也未必有空间。
2. IO多路复用和业务逻辑耦合在一起也是麻烦!
2.1阻塞式IO
那怎么办?第一种办法,乖乖的让出CPU,进到等待队列里,等socket就绪后,再次获得时间片就可以继续执行了。这就是阻塞式IO。
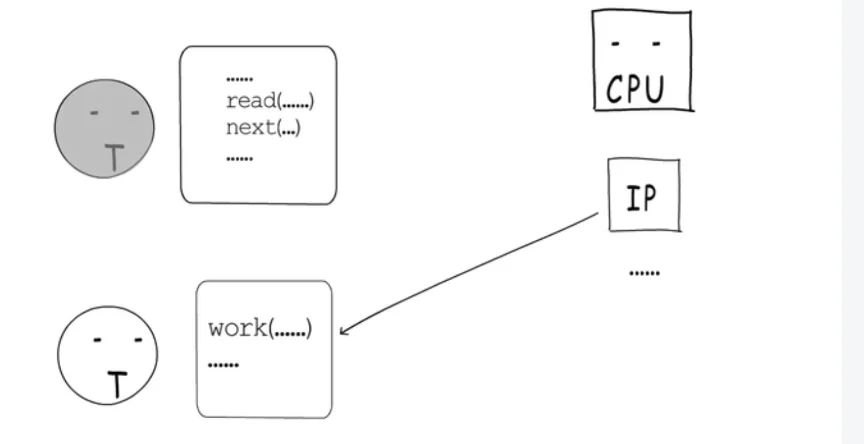
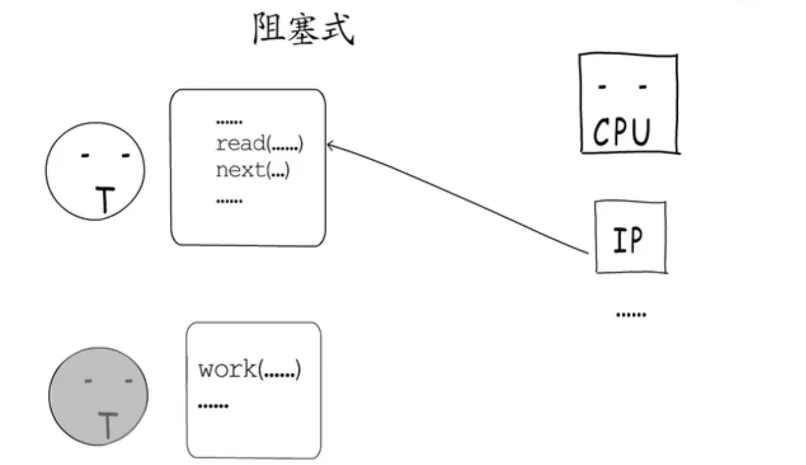
使用阻塞式IO,要处理一个socket就要占用一个线程。等这个socket处理完才能接手下一个,这在高并发场景下会加剧调度开销
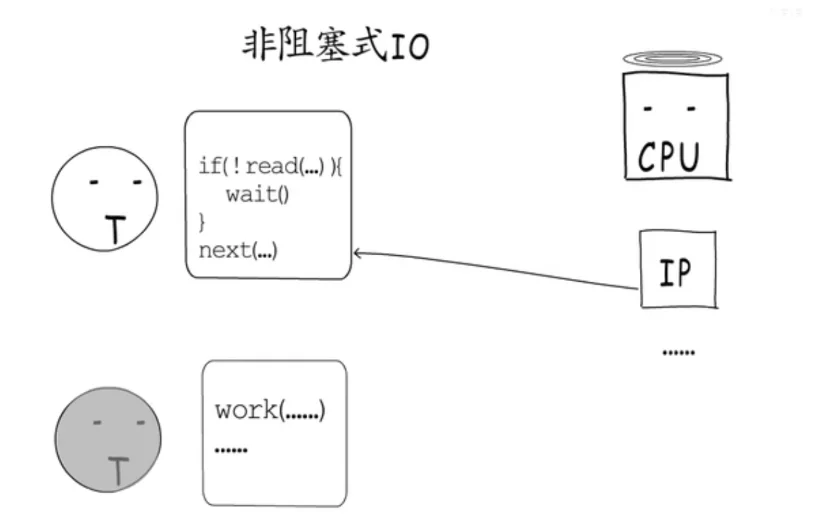
2.2非阻塞式IO
第二中办法是非阻塞式IO,也就是不让出CPU,但是需要频繁的检查socket是否就绪了。这是一种“忙等待”的方式,很难把握轮询的间隔间,容易造成空耗CPU,加剧相应延迟。
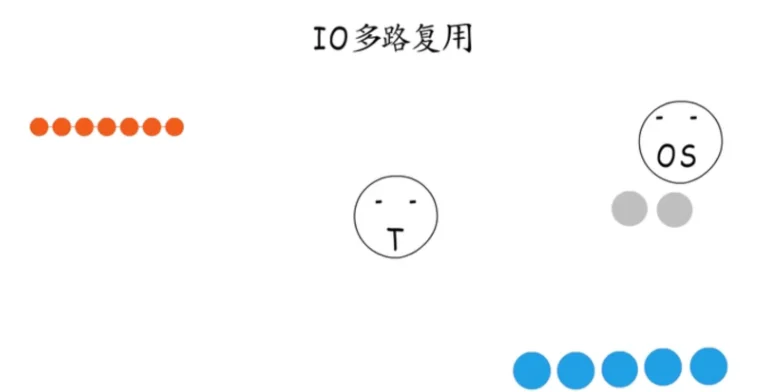
2.3IO多路复用
IO多路复用
第三种办法就是“IO多路复用”,由操作系统提供支持,把需要等待的socket加入到监听集合,这样就可以通过一次系统调用,同时监听多个socket。
有socket就绪了,就可以逐个处理了,既不用为了等待某个socket而阻塞,也不会陷入“忙等待”之中
Linux中提供了三种IO多路复用的实现方式
(1)select
select
第一种select,我们可以设置要监听的描述符,也可以设置等待超时时间,如果有准备好的fd,或达到指定超时时间,select函数就会返回。从函数签名来看,它支持监听可读,可写,异常三类事件。因为这个fd_set是个unsigned long型的数组,共16个元素,每一位对应一个fd,16*64=1024,最多可以监听1024个fd。这就有点少了,而且每次调用select都要传递所有监听集合,这就需要频繁的从用户态到内核态拷贝数据。除此之外,即便有fd就绪了,也需要遍历整个监听集合,来判断哪个fd是可操作的,这些都会影响性能。
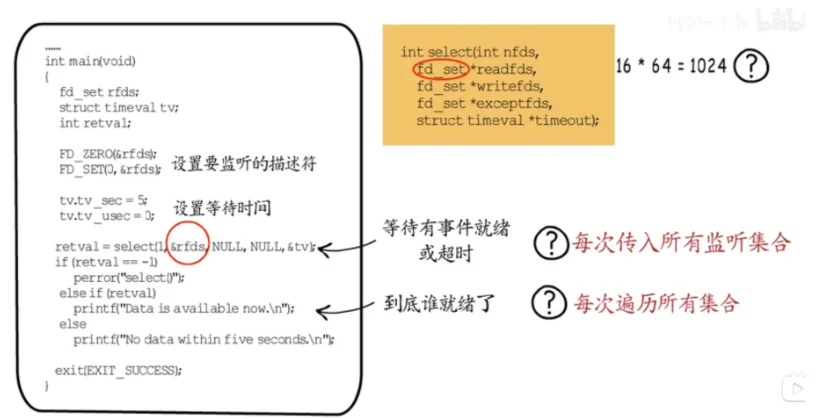
(2)poll
poll
第二种IO多路复用实现方式:poll。虽然支持的fd数目等于最多可打开的文件描述符的个数,但是另外两个问题依然存在。

(3)epoll
epoll
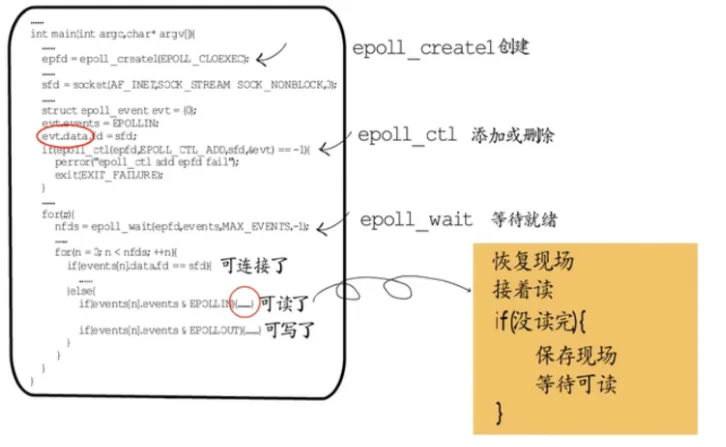
而epoll就没有这些问题了,它提供三个接口,epoll_create1用于创建一个epoll,并获取一个句柄;
epoll_ctl用于添加,修改或删除fd与对应的事件信息,除了指定fd和要监听的事件类型,还可以传入一个event data,通常会按需定义一个数据结构,用于处理对应的fd。可以看到每次都只需传入要操作的一个fd,无需传入所有监听集合,而且只需要注册这一次,通过epoll_wait得到的fd集合都是已经就绪的,逐个处理即可,无需遍历所有监听集合。

3. 协程和IO多路复用怎么合作?
使用协程
通过IO多路复用,线程再也不用为了等待某一个socket,而阻塞或空耗CPU。并发处理能力因而大幅提升,但是也并非没有问题,例如一个socket可读了,但是这回只读到了半条请求,也就是说需要再次等待这个socket可读,在继续处理下一个socket之前,需要记录下这个socket的处理状态,下一个这个socket可读时,也需要恢复上次保存的现场,才好继续处理。
也就是说,在IO多路复用中实现业务逻辑时,我们需要随着事件的等待和就绪,而频繁的保存和恢复现场,这并不符合常规开发习惯,如果业务逻辑比较简单还好,若是较为复杂的业务场景,就是悲剧了。
既然业务处理过程中,要等待事件时,需要保存现场并切换到下一个就绪的fd,而事件就绪时又需要恢复现场继续处理,那岂不是很适合协程?
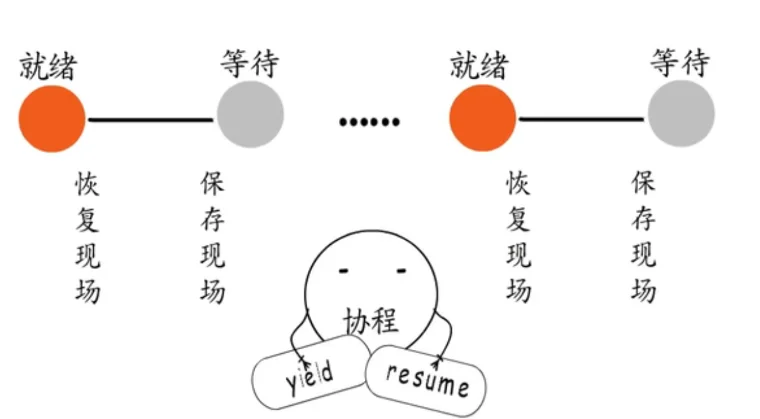
在IO多路复用这里,事件循环依然存在,依然要在循环中逐个处理就绪的fd,但处理过程却不是围绕具体业务,而是面向协程调度。如果是用于监听端口的fd就绪了,就建立连接创建一个新的fd,交给一个协程来负责,协程执行入口就指向业务处理函数入口,业务处理过程中,需要等待时就注册IO事件,然后让出。
这样执行权就会回到切换到该协程的地方继续执行。如果是其他等待IO事件的fd就绪了,只需要恢复关联的协程即可。
协程拥有自己的栈,要保存和恢复现场都很容易实现。这样IO多路复用这一层的事件循环,就和具体业务逻辑解耦了。可以把read,write,connect等可以回发生等待的函数包装一下,在其中实现IO事件注册与主动让出,这样在业务逻辑层面就可以使用这些包装函数,按照常规的顺序编程方式,来实现业务逻辑了。
这些包装函数在需要等待时,就会注册IO事件,然后让出协程。这样我们在实现业务逻辑时就完全不用关心保存和恢复现场的问题了。协程和IO多路复用之间的合作,不仅保留了IO多路复用的高并发性能,还解放了业务逻辑的实现。
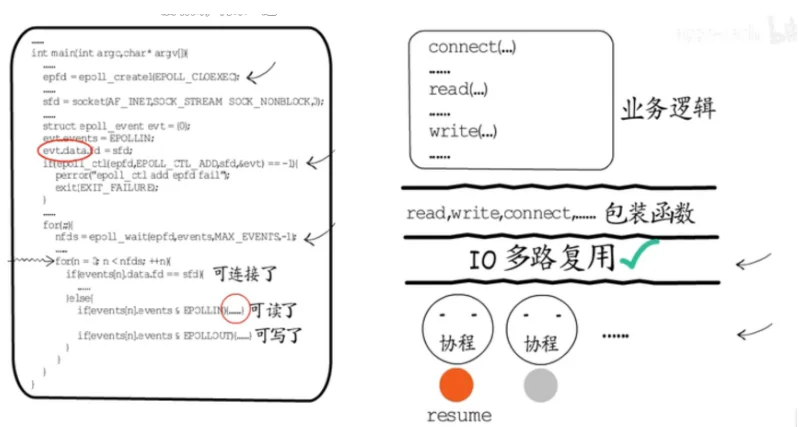
其实在Golang,OpenResty,Swoole中,协程和IO多路复用的合作方式,核心思想大抵如此。

为了增强理解,我们按照这个思路实现了一个精简版的实例,项目结构是这样的,最底层实现了协程,定义了协程对应的数据结构,提供协程初始化与切换等核心功能。基于这些功能实现了协程池,可以预创建一批协程备用,回收空闲协程复用,还可以根据请求情况缩减或扩张协程池规模,这样上层应用就不用关心协程的实现细节了。协程池之上是IO多路复用功能的实现,目前已实现对这些IO多路复用的支持,对于学习理解相关概念而言足够了。再往上是框架层,封装了事件循环,实现了基于IO的协程调度,有了框架层的封装,我们只需要关注业务层面的具体实现就ok了。
