
简介
设计模式是面向对象软件的设计经验,是解决特定问题的一系列套路。它不是语法规定,而是一套用来提高代码可复用性、可维护性、可读性、稳健性以及安全性的解决方案。每一种设计模式系统的命名、解释和评价了面向对象中一个重要的和重复出现的设计。
创建模式是用来帮助我们创建对象的,具体有如下几种:
- 工厂模式 (Factory Pattern)
- 抽象工厂模式 (Abstract Factory Pattern)
- 单例模式 (Singleton Pattern)
- 建造者模式 (Builder Pattern)
- 原型模式 (Prototype Pattern)
通俗解释
追 MM 少不了请吃饭了,麦当劳的鸡翅和肯德基的鸡翅都是 MM 爱吃的东西,虽然口味有所不同,但不管你带 MM 去麦当劳或肯德基,只管向服务员说「来四个鸡翅」就行了。麦当劳和肯德基就是生产鸡翅的 Factory 工厂模式:客户类和工厂类分开。
消费者任何时候需要某种产品,只需向工厂请求即可。消费者无须修改就可以接纳新产品。缺点是当产品修改时,工厂类也要做相应的修改。如:如何创建及如何向客户端提供。
简单工厂模式
简单工厂模式(Simple Factory Pattern):又称为静态工厂方法(Static Factory Method)模式,它属于类创建型模式。在简单工厂模式中,可以根据参数的不同返回不同类的实例。
优点
工厂类含有必要的判断逻辑,可以决定在什么时候创建哪一个产品类的实例,客户端可以免除直接创建产品对象的责任,而仅仅“消费”产品;简单工厂模式通过这种做法实现了对责任的分割,它提供了专门的工厂类用于创建对象。 客户端无须知道所创建的具体产品类的类名,只需要知道具体产品类所对应的参数即可,对于一些复杂的类名,通过简单工厂模式可以减少使用者的记忆量。 通过引入配置文件,可以在不修改任何客户端代码的情况下更换和增加新的具体产品类,在一定程度上提高了系统的灵活性。
缺点
由于工厂类集中了所有产品创建逻辑,一旦不能正常工作,整个系统都要受到影响。 使用简单工厂模式将会增加系统中类的个数,在一定程序上增加了系统的复杂度和理解难度。 系统扩展困难,一旦添加新产品就不得不修改工厂逻辑,在产品类型较多时,有可能造成工厂逻辑过于复杂,不利于系统的扩展和维护。 简单工厂模式由于使用了静态工厂方法,造成工厂角色无法形成基于继承的等级结构。
代码编写
NewNamepackage factory
// IRuleConfigParser IRuleConfigParser
type IRuleConfigParser interface {
Parse(data []byte)
}
// jsonRuleConfigParser jsonRuleConfigParser
type jsonRuleConfigParser struct {
}
// Parse Parse
func (J jsonRuleConfigParser) Parse(data []byte) {
panic("implement me")
}
// yamlRuleConfigParser yamlRuleConfigParser
type yamlRuleConfigParser struct {
}
// Parse Parse
func (Y yamlRuleConfigParser) Parse(data []byte) {
panic("implement me")
}
// NewIRuleConfigParser NewIRuleConfigParser
func NewIRuleConfigParser(t string) IRuleConfigParser {
switch t {
case "json":
return jsonRuleConfigParser{}
case "yaml":
return yamlRuleConfigParser{}
}
return nil
}
单元测试
package factory
import (
"reflect"
"testing"
)
func TestNewIRuleConfigParser(t *testing.T) {
type args struct {
t string
}
tests := []struct {
name string
args args
want IRuleConfigParser
}{
{
name: "json",
args: args{t: "json"},
want: jsonRuleConfigParser{},
},
{
name: "yaml",
args: args{t: "yaml"},
want: yamlRuleConfigParser{},
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := NewIRuleConfigParser(tt.args.t); !reflect.DeepEqual(got, tt.want) {
t.Errorf("NewIRuleConfigParser() = %v, want %v", got, tt.want)
}
})
}
}
工厂模式
在工厂方法模式中,我们执行单个函数,传入一个参数(提供信息表明我们想要什么),但 并不要求知道任何关于对象如何实现以及对象来自哪里的细节
适用场景
创建对象需要大量重复的代码 客户端(应用层)不依赖于产品实例,如何被创建、实现等细节 一个类通过其子类来指定创建哪个对象
优点
用户只需要关心所需产品对应的工厂,无须关心创建细节 加入新产品符合开闭原则,提高可扩展性
缺点
在添加新产品时,需要编写新的具体产品类,而且还要提供与之对应的具体工厂类,系统中类的个数将成对增加,在一定程度上增加了系统的复杂度,有更多的类需要编译和运行,会给系统带来一些额外的开销。 由于考虑到系统的可扩展性,需要引入抽象层,在客户端代码中均使用抽象层进行定义,增加了系统的抽象性和理解难度,且在实现时可能需要用到DOM、反射等技术,增加了系统的实现难度。
代码编写
new// IRuleConfigParserFactory 工厂方法接口
type IRuleConfigParserFactory interface {
CreateParser() IRuleConfigParser
}
// yamlRuleConfigParserFactory yamlRuleConfigParser 的工厂类
type yamlRuleConfigParserFactory struct {
}
// CreateParser CreateParser
func (y yamlRuleConfigParserFactory) CreateParser() IRuleConfigParser {
return yamlRuleConfigParser{}
}
// jsonRuleConfigParserFactory jsonRuleConfigParser 的工厂类
type jsonRuleConfigParserFactory struct {
}
// CreateParser CreateParser
func (j jsonRuleConfigParserFactory) CreateParser() IRuleConfigParser {
return jsonRuleConfigParser{}
}
// NewIRuleConfigParserFactory 用一个简单工厂封装工厂方法
func NewIRuleConfigParserFactory(t string) IRuleConfigParserFactory {
switch t {
case "json":
return jsonRuleConfigParserFactory{}
case "yaml":
return yamlRuleConfigParserFactory{}
}
return nil
}
单元测试
package factory
import (
"reflect"
"testing"
)
func TestNewIRuleConfigParserFactory(t *testing.T) {
type args struct {
t string
}
tests := []struct {
name string
args args
want IRuleConfigParserFactory
}{
{
name: "json",
args: args{t: "json"},
want: jsonRuleConfigParserFactory{},
},
{
name: "yaml",
args: args{t: "yaml"},
want: yamlRuleConfigParserFactory{},
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := NewIRuleConfigParserFactory(tt.args.t); !reflect.DeepEqual(got, tt.want) {
t.Errorf("NewIRuleConfigParserFactory() = %v, want %v", got, tt.want)
}
})
}
}
抽象工厂模式(Abstract Factory Pattern):提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们具体的类。抽象工厂模式又称为Kit模式,属于对象创建型模式。一个抽象工厂是一些工厂方法的(逻辑)集合,其中每一个工厂方法负责生成不同的对象。
通俗解释
请 MM 去麦当劳吃汉堡,不同的 MM 有不同的口味,要每个都记住是一件烦人的事情,我一般采用 Factory Method 模式,带着 MM 到服务员那儿,说「要一个汉堡」,具体要什么样的汉堡呢,让 MM 直接跟服务员说就行了。
工厂方法模式:核心工厂类不再负责所有产品的创建,而是将具体创建的工作交给子类去做,成为一个抽象工厂角色,仅负责给出具体工厂类必须实现的接口,而不接触哪一个产品类应当被实例化这种细节。
应用环境
使用工厂模式还是抽象工厂模式?
通常先从简单的工厂模式开始,后面发现应用程序需要许多的工厂方法,且将这些工厂方法组合起来创建一系列的对象是有意义的,这样的话就应该使用抽象工厂。
优点
抽象工厂模式隔离了具体类的生成,使得客户并不需要知道什么被创建。由于这种隔离,更换一个具体工厂就变得相对容易。所有的具体工厂都实现了抽象工厂中定义的那些公共接口,因此只需改变具体工厂的实例,就可以在某种程度上改变整个软件系统的行为。另外,应用抽象工厂模式可以实现高内聚低耦合的设计目的,因此抽象工厂模式得到了广泛的应用。 当一个产品族中的多个对象被设计成一起工作时,它能够保证客户端始终只使用同一个产品族中的对象。这对一些需要根据当前环境来决定其行为的软件系统来说,是一种非常实用的设计模式。 增加新的具体工厂和产品族很方便,无须修改已有系统,符合“开闭原则”。
缺点
在添加新的产品对象时,难以扩展抽象工厂来生产新种类的产品,这是因为在抽象工厂角色中规定了所有可能被创建的产品集合,要支持新种类的产品就意味着要对该接口进行扩展,而这将涉及到对抽象工厂角色及其所有子类的修改,显然会带来较大的不便。 开闭原则的倾斜性(增加新的工厂和产品族容易,增加新的产品等级结构麻烦)。
代码实现
该示例来自《Mastering Python Design Patterns,Second Edition》,模拟一个游戏。
HeroObstacleWorldHeroObstacleWorldpackage abstractfactory
import (
"fmt"
)
// Hero 英雄
type Hero interface {
// InteractWith 和 xx 交互
InteractWith(Obstacle)
String() string
}
var _ Hero = (*Frog)(nil)
// Frog 青蛙🐸
type Frog struct {
Name string
}
func (f *Frog) InteractWith(o Obstacle) {
act := o.Action()
fmt.Printf("%s the Frog encounters %s and %s!\n", f, o, act)
}
func (f *Frog) String() string {
return f.Name
}
var _ Hero = (*Wizard)(nil)
// Wizard 巫师💂
type Wizard struct {
Name string
}
func (w *Wizard) InteractWith(o Obstacle) {
act := o.Action()
fmt.Printf("%s the Wizard battles against %s and %s!\n", w, o, act)
}
func (w *Wizard) String() string {
return w.Name
}
// Obstacle 障碍物
type Obstacle interface {
// Action 动作
Action() string
String() string
}
var _ Obstacle = (*Bug)(nil)
// Bug 虫子🐛
type Bug struct{}
func (b *Bug) Action() string {
return "eat it"
}
func (b *Bug) String() string {
return "a bug"
}
var _ Obstacle = (*Ork)(nil)
// Ork 兽人👹
type Ork struct{}
func (o *Ork) Action() string {
return "kills it"
}
func (o *Ork) String() string {
return "an evil ork"
}
// World 世界
type World interface {
// MakeCharacter 初始化角色
MakeCharacter() Hero
// MakeObstacle 初始化障碍物
MakeObstacle() Obstacle
String() string
}
var _ World = (*FrogWorld)(nil)
// FrogWorld 青蛙的世界
type FrogWorld struct {
PlayerName string
}
func (fw *FrogWorld) MakeCharacter() Hero {
return &Frog{
Name: fw.PlayerName,
}
}
func (fw *FrogWorld) MakeObstacle() Obstacle {
return &Bug{}
}
func (fw *FrogWorld) String() string {
return "\n\n\t------ Frog World ------"
}
var _ World = (*WizardWorld)(nil)
// WizardWorld 巫师世界
type WizardWorld struct {
PlayerName string
}
func (ww *WizardWorld) MakeCharacter() Hero {
return &Wizard{
Name: ww.PlayerName,
}
}
func (ww *WizardWorld) MakeObstacle() Obstacle {
return &Ork{}
}
func (ww *WizardWorld) String() string {
return "\n\n\t------ Wizard World ------"
}
// GameEnvironment 游戏入口 🕹
type GameEnvironment struct {
hero Hero
obstacle Obstacle
}
func NewGame(world World) GameEnvironment {
fmt.Println(world)
return GameEnvironment{
hero: world.MakeCharacter(),
obstacle: world.MakeObstacle(),
}
}
// Play 开始游戏
func (g GameEnvironment) Play() {
g.hero.InteractWith(g.obstacle)
}
单元测试
package abstractfactory
import "testing"
func TestFrogWorld(t *testing.T) {
var world World = &FrogWorld{PlayerName: "Billy"}
var game GameEnvironment = NewGame(world)
game.Play()
}
func TestWizardWorld(t *testing.T) {
var world World = &WizardWorld{PlayerName: "Charles"}
var game GameEnvironment = NewGame(world)
game.Play()
}
通俗解释
俺有 6 个漂亮的老婆,她们的老公都是我,我就是我们家里的老公 Sigleton,她们只要说道「老公」,都是指的同一个人,那就是我 (刚才做了个梦啦,哪有这么好的事)
单例模式:单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例单例模式。单例模式只应在有真正的 “单一实例” 的需求时才可使用。
概念
单例模式,是一种很常见的软件设计模式,在他的核心结构中只包含一个被称为单例的特殊类。通过单例模式可以保证系统中一个类只有一个实例且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。
单例模式确保某一个类只有一个实例。为什么要确保一个类只有一个实例?有什么时候才需要用到单例模式呢?听起来一个类只有一个实例好像没什么用呢!那我们来举个例子。比如我们的APP中有一个类用来保存运行时全局的一些状态信息,如果这个类实现不是单例的,那么App里面的组件能够随意的生成多个类用来保存自己的状态,等于大家各玩各的,那这个全局的状态信息就成了笑话了。而如果把这个类实现成单例的,那么不管App的哪个组件获取到的都是同一个对象(比如Application类,除了多进程的情况下)。
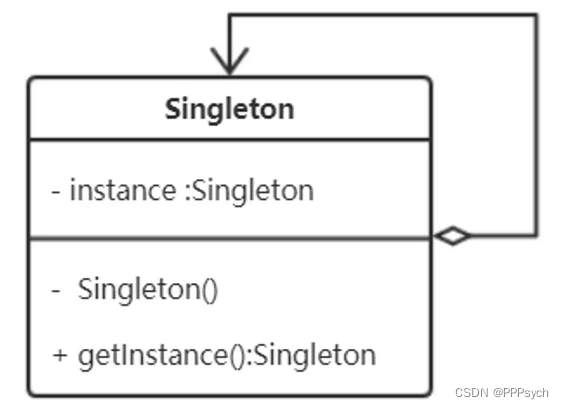
- 单例类只能有一个实例,并提供一个访问它的全局访问点。
- 单例类必须自己创建自己的唯一实例。
- 单例类必须给所有其他对象提供这一实例。
应用环境
- 要求生产唯一序列号。
- WEB 中的计数器,不用每次刷新都在数据库里加一次,用单例先缓存起来。
- 创建的一个对象需要消耗的资源过多时,比如 I/O 与数据库的连接等。
- 主要解决"一个全局使用的类频繁地创建与销毁"这样的问题
- 当您想控制实例数目,节省系统资源的时候可以用单例模式
优点
- 在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例。
- 避免对资源的多重占用。
实现方式
-
懒汉模式
-
饿汉模式
懒汉模式
概念
从懒汉这两个字,我们就能知道,这个人很懒,所以他不可能在未使用实例时就创建了对象,他肯定会在使用时才会创建实例,这个好处的就在于,只有在使用的时候才会创建该实例。
不加锁实现
这种方法是会存在线程安全问题的,在高并发的时候会有多个线程同时掉这个方法,那么都会检测instance为nil,这样就会导致创建多个对象,所以这种方法是不推荐的
GetInstancetype singleton struct {}s := &singleton{}package one
type singleton struct {
}
var instance *singleton
func GetInstance() *singleton {
if instance == nil{
instance = new(singleton)
}
return instance
}
整个方法加锁
这里对整个方法进行了加锁,这种可以解决并发安全的问题,但是效率就会降下来,每一个对象创建时都是进行加锁解锁,这样就拖慢了速度,所以不推荐这种写法。
type singleton struct {
}
var instance *singleton
var lock sync.Mutex
func GetInstance() *singleton {
lock.Lock()
defer lock.Unlock()
if instance == nil{
instance = new(singleton)
}
return instance
}
创建方法时进行锁定
这种方法也是线程不安全的,虽然我们加了锁,多个线程同样会导致创建多个实例,所以这种方式也不是推荐的。
type singleton struct {
}
var instance *singleton
var lock sync.Mutex
func GetInstance() *singleton {
if instance == nil{
lock.Lock()
instance = new(singleton)
lock.Unlock()
}
return instance
}
双重检锁
这里在上面的代码做了改进,只有当对象未初始化的时候,才会有加锁和减锁的操作。但是又出现了另一个问题:每一次访问都要检查两次
原子操作实现
sync.OnceDotype singleton struct {
}
var instance *singleton
var once sync.Once
func GetInstance() *singleton {
once.Do(func() {
instance = new(singleton)
})
return instance
}
懒汉模式
概念
看了懒汉的模式,饿汉模式我们很好解释了,因为他饿呀,所以很着急的就创建了实例,不用等到使用时才创建,这样我们每次调用获取接口将不会重新创建新的对象,而是直接返回之前创建的对象。比较适用于:如果某个单例使用的次数少,并且创建单例消息的资源比较多,那么就需要实现单例的按需创建,这个时候懒汉模式就是一个不错的选择。不过也有缺点,饿汉模式将在包加载的时候就会创建单例对象,当程序中用不到该对象时,浪费了一部分空间,但是相对于懒汉模式,不需要进行了加锁操作,会更安全,但是会减慢启动速度。
全局变量实现、init加载实现
以下这两种方法都可以,第一种我们采用创建一个全局变量的方式来实现,第二种我们使用init包加载的时候创建实例,这里两个都可以,不过根据golang的执行顺序,全局变量的初始化函数会比包的init函数先执行,没有特别的差距。
全局变量实现:
type singleton struct {
}
var instance = new(singleton)
func GetInstance() *singleton{
return instance
}
init加载实现:
type singleton struct {
}
var instance *singleton
func init() {
instance = new(singleton)
}
func GetInstance() *singleton{
return instance
}
代码实现
饿汉式
代码实现:
package singleton
// Singleton 饿汉式单例
type Singleton struct{}
var singleton *Singleton
func init() {
singleton = &Singleton{}
}
// GetInstance 获取实例
func GetInstance() *Singleton {
return singleton
}
单元测试:
package singleton_test
import (
"testing"
singleton "github.com/mohuishou/go-design-pattern/01_singleton"
"github.com/stretchr/testify/assert"
)
func TestGetInstance(t *testing.T) {
assert.Equal(t, singleton.GetInstance(), singleton.GetInstance())
}
func BenchmarkGetInstanceParallel(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
if singleton.GetInstance() != singleton.GetInstance() {
b.Errorf("test fail")
}
}
})
}
init懒汉式(双重检测)
代码实现:
package singleton
import "sync"
var (
lazySingleton *Singleton
once = &sync.Once{}
)
// GetLazyInstance 懒汉式
func GetLazyInstance() *Singleton {
if lazySingleton == nil {
once.Do(func() {
lazySingleton = &Singleton{}
})
}
return lazySingleton
}
通俗解释
MM 最爱听的就是「我爱你」这句话了,见到不同地方的 MM,要能够用她们的方言跟她说这句话哦,我有一个多种语言翻译机,上面每种语言都有一个按键,见到 MM 我只要按对应的键,它就能够用相应的语言说出「我爱你」这句话了,国外的 MM 也可以轻松搞掂,这就是我的「我爱你」builder。
建造模式:将产品的内部表象和产品的生成过程分割开来,从而使一个建造过程生成具有不同的内部表象的产品对象。建造模式使得产品内部表象可以独立的变化,客户不必知道产品内部组成的细节。建造模式可以强制实行一种分步骤进行的建造过程。
概念
在软件开发过程中有时需要创建一个复杂的对象,这个复杂对象通常由多个子部件按一定的步骤组合而成。产品都是由多个部件构成的,各个部件可以灵活选择,但其创建步骤都大同小异。将一个复杂对象的构造与它的表示分离,使同样的构建过程可以创建不同的表示,这样的设计模式被称为建造者模式。它是将一个复杂的对象分解为多个简单的对象,然后一步一步构建而成。它将变与不变相分离,即产品的组成部分是不变的,但每一部分是可以灵活选择的。
四个要素:
- 产品类:一般是一个较为复杂的对象,也就是说创建对象的过程比较复杂,一般会有比较多的代码量。在本类图中,产品类是一个具体的类,而非抽象类。实际编程中,产品类可以是由一个抽象类与它的不同实现组成,也可以是由多个抽象类与他们的实现组成。
- 抽象建造者:引入抽象建造者的目的,是为了将建造的具体过程交与它的子类来实现。这样更容易扩展。一般至少会有两个抽象方法,一个用来建造产品,一个是用来返回产品。
- 建造者:实现抽象类的所有未实现的方法,具体来说一般是两项任务:组建产品;返回组建好的产品。
- 导演类(监工):负责调用适当的建造者来组建产品,导演类一般不与产品类发生依赖关系,与导演类直接交互的是建造者类。一般来说,导演类被用来封装程序中易变的部分。
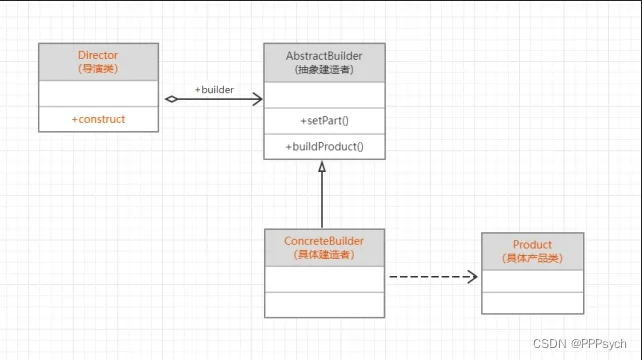
示例:
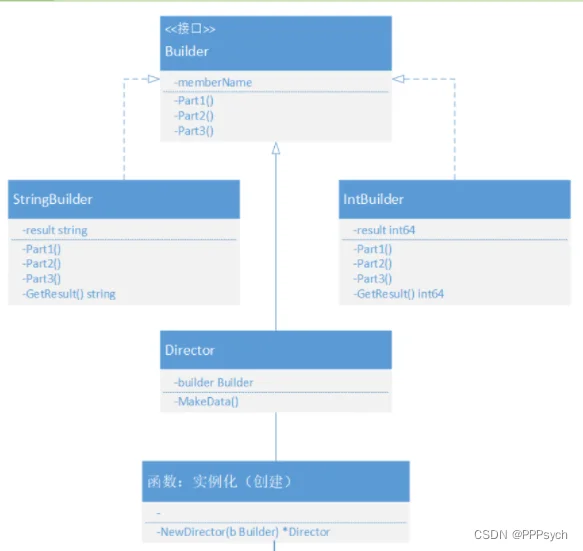
package main
import "fmt"
//================1.建造者接口==============
//Builder 是生成器接口
type Builder interface {
Part1()
Part2()
Part3()
}
//===============2.建造者对象及操作===============
type Director struct {
builder Builder //建造者的接口
}
//创建接口
func NewDirector(b Builder) *Director {
return &Director{builder: b}
}
func (d *Director) MakeData() {
d.builder.Part1()
d.builder.Part2()
d.builder.Part3()
}
//===========3.建造者实例==============
//string建造者
type StringBuilder struct {
result string
}
func (sb *StringBuilder) Part1() {
sb.result += "1"
}
func (sb *StringBuilder) Part2() {
sb.result += "2"
}
func (sb *StringBuilder) Part3() {
sb.result += "3"
}
func (sb *StringBuilder) GetResult() string {
return sb.result
}
//int建造者
type IntBuilder struct {
result int64
}
func (ib *IntBuilder) Part1() {
ib.result = ib.result + 1
}
func (ib *IntBuilder) Part2() {
ib.result = ib.result + 2
}
func (ib *IntBuilder) Part3() {
ib.result = ib.result + 3
}
func (ib *IntBuilder) GetResult() int64 {
return ib.result
}
func main() {
//b:=StringBuilder{}
b:=IntBuilder{}
sb := NewDirector(&b) //对象继承了接口(实现了接口对应的方法);若参数为接口类型,则传递的是对象的地址
sb.MakeData()
fmt.Println("执行效果为:",b.result)
}
应用环境
主要解决在软件系统中,有时候面临一个复杂对象的创建工作,通常这个复杂对象由各个部分的子对象用一定的算法构建成。由于需求的变化,这个复杂对象的各个部分通常会出现巨大的变化,所以,将各个子对象独立出来,容易修改。
建造者的应用场景:
- 类中的属性比较多。
- 类中的属性有一定的依赖关系,或者约束条件。
- 存在必选或非必选属性。
- 创建不可变对象
优点
- 封装性好,创建和使用分离
- 扩展性好,建造类之间独立、一定程度上解耦。
缺点
- 产生多余的Builder对象;
- 产品内部发生变化,建造者都要修改,成本较大。
建造者模式和工厂模式的区别
-
建造者模式更加注重方法的调用顺序,工厂模式注重于创建对象。
-
创建对象的力度不同,建造者模式创建复杂的对象,由各种复杂的部件组成,工厂模式创建出来的都一样。
-
关注点不一样,工厂模式只需要把对象创建出来就行了,而建造者模式不仅要创建出这个对象,还要知道这个对象由哪些部分组成。
-
建造者模式根据建造过程中的顺序不一样,最终的对象部件组成也不一样。
总结:
- 建造者:创建参数较多的对象。
- 工厂模式:创建类型相关的不同对象
代码实现
其实在 Golang 中对于创建类参数比较多的对象的时候,我们常见的做法是必填参数直接传递,可选参数通过传递可变的方法进行创建。
本文会先实现建造者模式,然后再实现我们常用的方式。
建造者模式
通过下面可以看到,使用 Go 编写建造者模式的代码其实会很长,这些是它的一个缺点,所以如果不是参数的校验逻辑很复杂的情况下一般我们在 Go 中不会采用这种方式,而会采用后面的另外一种方式
package builder
import "fmt"
const (
defaultMaxTotal = 10
defaultMaxIdle = 9
defaultMinIdle = 1
)
// ResourcePoolConfig resource pool
type ResourcePoolConfig struct {
name string
maxTotal int
maxIdle int
minIdle int
}
// ResourcePoolConfigBuilder 用于构建 ResourcePoolConfig
type ResourcePoolConfigBuilder struct {
name string
maxTotal int
maxIdle int
minIdle int
}
// SetName SetName
func (b *ResourcePoolConfigBuilder) SetName(name string) error {
if name == "" {
return fmt.Errorf("name can not be empty")
}
b.name = name
return nil
}
// SetMinIdle SetMinIdle
func (b *ResourcePoolConfigBuilder) SetMinIdle(minIdle int) error {
if minIdle < 0 {
return fmt.Errorf("max tatal cannot < 0, input: %d", minIdle)
}
b.minIdle = minIdle
return nil
}
// SetMaxIdle SetMaxIdle
func (b *ResourcePoolConfigBuilder) SetMaxIdle(maxIdle int) error {
if maxIdle < 0 {
return fmt.Errorf("max tatal cannot < 0, input: %d", maxIdle)
}
b.maxIdle = maxIdle
return nil
}
// SetMaxTotal SetMaxTotal
func (b *ResourcePoolConfigBuilder) SetMaxTotal(maxTotal int) error {
if maxTotal <= 0 {
return fmt.Errorf("max tatal cannot <= 0, input: %d", maxTotal)
}
b.maxTotal = maxTotal
return nil
}
// Build Build
func (b *ResourcePoolConfigBuilder) Build() (*ResourcePoolConfig, error) {
if b.name == "" {
return nil, fmt.Errorf("name can not be empty")
}
// 设置默认值
if b.minIdle == 0 {
b.minIdle = defaultMinIdle
}
if b.maxIdle == 0 {
b.maxIdle = defaultMaxIdle
}
if b.maxTotal == 0 {
b.maxTotal = defaultMaxTotal
}
if b.maxTotal < b.maxIdle {
return nil, fmt.Errorf("max total(%d) cannot < max idle(%d)", b.maxTotal, b.maxIdle)
}
if b.minIdle > b.maxIdle {
return nil, fmt.Errorf("max idle(%d) cannot < min idle(%d)", b.maxIdle, b.minIdle)
}
return &ResourcePoolConfig{
name: b.name,
maxTotal: b.maxTotal,
maxIdle: b.maxIdle,
minIdle: b.minIdle,
}, nil
}
单元测试
package builder
import (
"testing"
"github.com/stretchr/testify/assert"
"github.com/stretchr/testify/require"
)
func TestResourcePoolConfigBuilder_Build(t *testing.T) {
tests := []struct {
name string
builder *ResourcePoolConfigBuilder
want *ResourcePoolConfig
wantErr bool
}{
{
name: "name empty",
builder: &ResourcePoolConfigBuilder{
name: "",
maxTotal: 0,
},
want: nil,
wantErr: true,
},
{
name: "maxIdle < minIdle",
builder: &ResourcePoolConfigBuilder{
name: "test",
maxTotal: 0,
maxIdle: 10,
minIdle: 20,
},
want: nil,
wantErr: true,
},
{
name: "success",
builder: &ResourcePoolConfigBuilder{
name: "test",
},
want: &ResourcePoolConfig{
name: "test",
maxTotal: defaultMaxTotal,
maxIdle: defaultMaxIdle,
minIdle: defaultMinIdle,
},
wantErr: false,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
got, err := tt.builder.Build()
require.Equalf(t, tt.wantErr, err != nil, "Build() error = %v, wantErr %v", err, tt.wantErr)
assert.Equal(t, tt.want, got)
})
}
}
常用方式
package builder
import "fmt"
// ResourcePoolConfigOption option
type ResourcePoolConfigOption struct {
maxTotal int
maxIdle int
minIdle int
}
// ResourcePoolConfigOptFunc to set option
type ResourcePoolConfigOptFunc func(option *ResourcePoolConfigOption)
// NewResourcePoolConfig NewResourcePoolConfig
func NewResourcePoolConfig(name string, opts ...ResourcePoolConfigOptFunc) (*ResourcePoolConfig, error) {
if name == "" {
return nil, fmt.Errorf("name can not be empty")
}
option := &ResourcePoolConfigOption{
maxTotal: 10,
maxIdle: 9,
minIdle: 1,
}
for _, opt := range opts {
opt(option)
}
if option.maxTotal < 0 || option.maxIdle < 0 || option.minIdle < 0 {
return nil, fmt.Errorf("args err, option: %v", option)
}
if option.maxTotal < option.maxIdle || option.minIdle > option.maxIdle {
return nil, fmt.Errorf("args err, option: %v", option)
}
return &ResourcePoolConfig{
name: name,
maxTotal: option.maxTotal,
maxIdle: option.maxIdle,
minIdle: option.minIdle,
}, nil
}
单元测试:
package builder
import (
"testing"
"github.com/stretchr/testify/assert"
"github.com/stretchr/testify/require"
)
func TestNewResourcePoolConfig(t *testing.T) {
type args struct {
name string
opts []ResourcePoolConfigOptFunc
}
tests := []struct {
name string
args args
want *ResourcePoolConfig
wantErr bool
}{
{
name: "name empty",
args: args{
name: "",
},
want: nil,
wantErr: true,
},
{
name: "success",
args: args{
name: "test",
opts: []ResourcePoolConfigOptFunc{
func(option *ResourcePoolConfigOption) {
option.minIdle = 2
},
},
},
want: &ResourcePoolConfig{
name: "test",
maxTotal: 10,
maxIdle: 9,
minIdle: 2,
},
wantErr: false,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
got, err := NewResourcePoolConfig(tt.args.name, tt.args.opts...)
require.Equalf(t, tt.wantErr, err != nil, "error = %v, wantErr %v", err, tt.wantErr)
assert.Equal(t, tt.want, got)
})
}
}
总结
其实可以看到,绝大多数情况下直接使用后面的这种方式就可以了,并且在编写公共库的时候,强烈建议入口的参数都可以这么传递,这样可以最大程度的保证我们公共库的兼容性,避免在后续的更新的时候出现破坏性的更新的情况。
原型模式通俗解释
跟 MM 用 QQ 聊天,一定要说些深情的话语了,我搜集了好多肉麻的情话,需要时只要 copy 出来放到 QQ 里面就行了,这就是我的情话 prototype 了。(100 块钱一份,你要不要)
原始模型模式:通过给出一个原型对象来指明所要创建的对象的类型,然后用复制这个原型对象的方法创建出更多同类型的对象。原始模型模式允许动态的增加或减少产品类,产品类不需要非得有任何事先确定的等级结构,原始模型模式适用于任何的等级结构。缺点是每一个类都必须配备一个克隆方法。
概念
原型模式(Prototype Pattern)是用于创建重复的对象,同时又能保证性能。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式是实现了一个原型接口,该接口用于创建当前对象的克隆。当直接创建对象的代价比较大时,则采用这种模式。例如,一个对象需要在一个高代价的数据库操作之后被创建。我们可以缓存该对象,在下一个请求时返回它的克隆,在需要的时候更新数据库,以此来减少数据库调用。
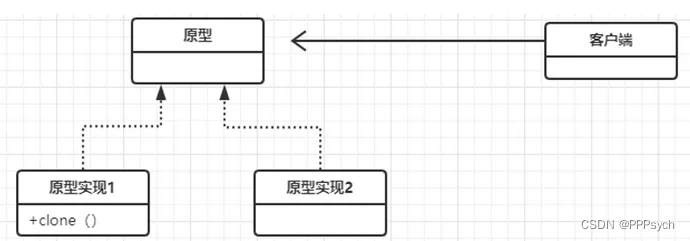
应用环境
- 当一个系统应该独立于它的产品创建,构成和表示时。
- 当要实例化的类是在运行时刻指定时,例如,通过动态装载。
- 为了避免创建一个与产品类层次平行的工厂类层次时。
- 当一个类的实例只能有几个不同状态组合中的一种时。建立相应数目的原型并克隆它们可能比每次用合适的状态手工实例化该类更方便一些。
优点
- 性能高。对客户隐藏了具体的产品类,因此减少了客户知道对象的数目。此外,这些模式使客户无需改变即可使用与特定应用相关的类(和工厂模式、建造者模式一样的效果)
- 高效。运行时刻增加和删除产品,原型模式允许只通过客户注册原型实例就可以将一个新的具体产品类型注入系统。
缺点
每种具体实现类型都要有一个克隆自己的操作。在某些场景会比较困难。
代码实现
//原型对象需要实现的接口
//拷贝原有的数据
type CloneAble interface {
Clone() CloneAble
}
func NewProtoTypeManager() *ProtoTypeManager {
return &ProtoTypeManager{prototypes:make(map[string]CloneAble)}
}
func (p *ProtoTypeManager)Get( name string)CloneAble {
return p.prototypes[name]
}
func (p *ProtoTypeManager)Set(name string,prototype CloneAble) {
p.prototypes[name] = prototype
}
type Type1 struct {
name string
}
func (t *Type1)Clone() CloneAble {
tc := *t
return &tc
}
type Type2 struct {
name string
}
func (t *Type2)Clone() CloneAble {
tc := *t
return &tc
}
func TestNewProtoTypeManager(t *testing.T) {
mgr := NewProtoTypeManager()
t1 := &Type1{name:"type1"}
mgr.Set("t1",t1)
t11 := mgr.Get("t1")
t22 := t11.Clone()
if t11 == t22 {
fmt.Println("clone address")
}else{
fmt.Println("clone value")
}
}