
第四篇文章,来聊聊 Golang 生态中如何“遥控”浏览器,更简单、可靠的使用基于 CDP (Chrome DevTools Protocol)协议的浏览器作为容器,获取诸如微博、B 站 这类动态渲染内容信息,将它们转换为 RSS 订阅源。
写在前面
前三篇文章中,我们从零到一实现了一个能够将网站信息转换为 RSS 订阅源的小工具雏形。
不过截止上一篇文章《RSS Can:将网站信息流转换为 RSS 订阅源(三)》,工具还只能处理传统的由服务器生成的内容。现如今,越来越多的网站的内容是由浏览器动态生成的,为了支持更广泛的信息获取,我们就需要借助 go-rod/Rod 这类可以通过 CDP(Chrome DevTools Protocol) 协议“遥控”浏览器(包括无头浏览器)的能力啦。
RSS Can(RSS 罐头)的相关代码已经开源在soulteary/RSS-Can。
项目中的代码,将会伴随文章更新而更新,如果你觉得项目有趣,欢迎“一键三连”。当然,如果你觉得这个事情有价值,也有趣,也欢迎加入项目,一起折腾。
如果你接触过 “CDP” 相关的项目,你或许会好奇,我为什么会选择 “Rod” 这个项目作为组件之一。
聊聊 CDP 相关的项目
提起能够调用浏览器进行自动化操作的 CDP 项目,最出名的三个项目都是 JavaScript 生态中的,分别是:puppeteer/puppeteer(81k stars)、microsoft/playwright(45k stars)、cypress-io/cypress(42k stars)。之前的文章里,也有提起过它们:《Playwright 简明入门教程:录制自动化测试用例,结合 Docker 使用》、《使用 Docker 和 Node 搭建公式渲染服务(后篇)》、《使用 Node.js 生成方便传播的图片》。
但是,在“高效解析动态渲染的网页信息”的场景下,这几个软件就不是那么合适了:
- 性能不够好,不论是针对 CDP 消息的大量编解码消耗,还是本身 Node 相比较 Golang 在拼执行时的稍逊一筹(即使生态非常好,语言灵活性也非常高)。
- 更偏重测试的定位,所以软件的复杂度会高很多。
- Golang 的类型安全,在编译产物的时候可以被保障。
类似的项目还有 Java 生态大名鼎鼎的SeleniumHQ/selenium(25k stars)等,相比较 Node 生态的三巨头,selenium 对于 CDP 的完整支持其实并没有想象中那么好,即使它非常老牌。
简单聊完 JavaScript 和 Java 生态的 CDP 工具后,将实现收回 Golang 生态,选择其实真的不多。相比较目前只有 3k Stars 的 go-rod/rod,拥有 8k Stars 的chromedp/chromedp可能是多数人的选择。虽然 chromedp 项目的示例更完备,但是代码书写的友好度其实没有 rod 好,其次组件灵活组合的能力 rod 也更好一些,最后,关于项目质量(可靠性)我也有一些疑问,这一点和 rod 文档里提出的有一部分是一致的:Crash 后好像进程没有清理掉。
如果我想直接使用 Golang 调用 Chrome ,恰好 chromedp 有现成的例子,我可能会直接用 chromedp。但如果我想做一个稳定的服务,我会选择更小巧、灵活、简单的 rod。
CSR (客户端)方式渲染的网页
之前的三篇文章中,我们使用的例子是静态生成内容的网站,在这里发挥不出 Rod 的神奇作用,所以我们将需要转换信息为 RSS 订阅源网站地址换成 B 站。
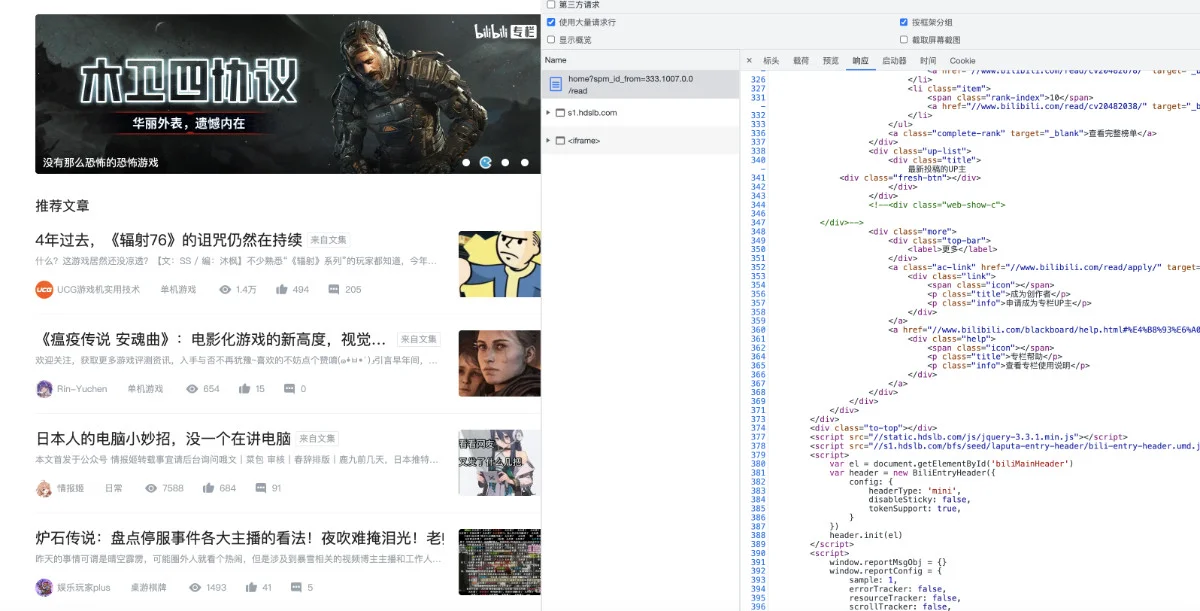
虽然我们还是可以和第一篇文章《使用 Golang 实现更好的 RSS Hub 服务(一)》中一样,使用相同的方式获取存放了有效信息的 HTML 标签的路径。但是,查看网页源文件,可以看到信息流内的东西并不存在于网页的“源代码”里。这是因为上图中的内容列表中的内容,是在网页加载所有前端程序(js、wasm)之后,在请求服务端生成的。
想要解决这个问题,一般有两种方案:
- 解析逻辑,或者跟踪调试工具中展示的网络请求,直接获取接口中的信息。
- 用本文提到的 CDP 相关工具,模拟正常访问,然后从浏览器环境中解析获取我们所需要的信息。
第一种方法看似高效,但是会因为各种原因出现“程序失效”,比如网站改版、网站升级 WAF 限制直接请求接口、网站使用非 Restful API 传输数据等等。试着想象下,当我们订阅了一千条甚至以上的 RSS 信息源之后,如果采用直接“刚”接口的方式,对于程序的维护负担还是比较大的。
相比较第一种方案,基于 CDP 的玩法,只需要消耗稍微多一些的硬件资源(毕竟要跑一个浏览器,哪怕是 headless 的)就能够根据界面特征得到我们想要的信息。
Rod 的基础使用
在了解了 CSR、CDP、Rod 的概况后,我们来开始今天的“旅途”,先来看看怎么简单上手这个工具。
启动 Chrome 的远程调试模式
虽然 Rod 会自动判断是否有合适“操作”浏览器,当缺少可运行浏览器时,会自动下载能够作为容器使用的浏览器。不过,除了调试开发模式或者极其简单的需求中,我个人的习惯是使用“外部浏览器”,开发环境和实际运行一致,实际使用改下远程运行容器(浏览器)地址,就能在各种环境下丝滑的提供服务啦。
--remote-debugging-port=9222 --headless当命令执行完毕,我们将看到下面的日志,提示我们可以开始玩了。
--proxy-server编写基础的“浏览器”自动化命令
假设你已经参考上面启动了一个本地的、支持远程操控的 Chrome 实例,只需要下面不到二十行代码,就能够模拟浏览器打开网页的操作啦:
() => document.title当我们执行完代码,将得到下面的结果:“B站UP主专栏-个人空间-自媒体-哔哩哔哩官网”。
完善浏览器自动化程序
我们像第二篇文章《RSS Can:借助 V8 让 Golang 应用具备动态化能力(二)》里一样,简单调整上面的代码,添加一段 JavaScript 代码,尝试在页面中打印出信息流中的文章标题。
不出意外,代码执行完毕,我们将得到“空”结果。主要的原因在于“我们的代码执行的太快了”,比页面中渲染出我们想要的信息的时间点早了。页面脚本下载需要时间、请求服务器获取接口数据同样需要时间。
为了解决这个问题,我们可以这样调整代码:
在上面的程序中,我们添加了一个“元素检查”的功能,确保程序能够在合适的时机中再去执行必须的代码。再次执行程序,等待程序执行完毕,我们就能得到类似下面的日志结果啦:
Rod 的进阶使用
上面的细节只是使用 Rod 这类 CDP 软件的小细节之一,关于 Rod 的详细使用,或许单独展开一篇内容更为合适。
实际使用的时候,我们还需要注意下面的细节:网页访问是否一直转圈儿没有加载完毕、网页证书是否过期导致无法访问、我们该怎么设置调试模式来观察程序执行过程,以及在前几篇文章中提到的,如何使用 JS SDK 来获取页面中的数据。
下面的程序简单封装了上面提到的一些问题:
上面这个函数的调用,类似下面这样:
当我们执行程序之后,程序将根据我们的实际配置,判断是否是调试环境,打开一个浏览器窗口,或者启动一个无头浏览器进程,在网页加载完毕之后,注入方便处理 DOM 结构的 jQuery 和 JS SDK,然后根据我们定义的 JS 配置获取页面中的数据,生成可以订阅的 RSS 数据。

使用 Docker 取代本地浏览器运行容器
使用 Docker 容器来运行浏览器容器,对于实际的生产环境来说非常实用。如果你只是想了解无头浏览器的使用,可以忽略本小节的内容。
我们可以通过下面的命令,来启动一个包含“浏览器”的 Docker 容器:
container10.11.12.90:9222--proxy-server=rod在后续的文章中,我们会继续展开这部分细节,关于如何部署和使用高可用的无头浏览器集群。如果你比较着急,可以先浏览 browserless 官方文档 进行实践 :D
最后
虽然现在的 RSS Can 的核心功能都就绪了,但是为了更加好用,我们还需要折腾一番。
接下来的文章里,我们继续“填坑”。
–EOF